Spark面試題(一)
Spark面試題(二)
Spark面試題(三)
Spark面試題(四)
Spark面試題(五)——資料傾斜調優
Spark面試題(六)——Spark資源調優
Spark面試題(七)——Spark程式開發調優
Spark面試題(八)——Spark的Shuffle配置調優
資料傾斜指的是,并行處理的資料集中,某一部分(如Spark或Kafka的一個Partition)的資料顯著多于其它部分,進而使得該部分的處理速度成為整個資料集處理的瓶頸。
資料傾斜倆大直接緻命後果。
1、資料傾斜直接會導緻一種情況:Out Of Memory。
2、運作速度慢。
主要是發生在Shuffle階段。同樣Key的資料條數太多了。導緻了某個key(下圖中的80億條)所在的Task資料量太大了。遠遠超過其他Task所處理的資料量。
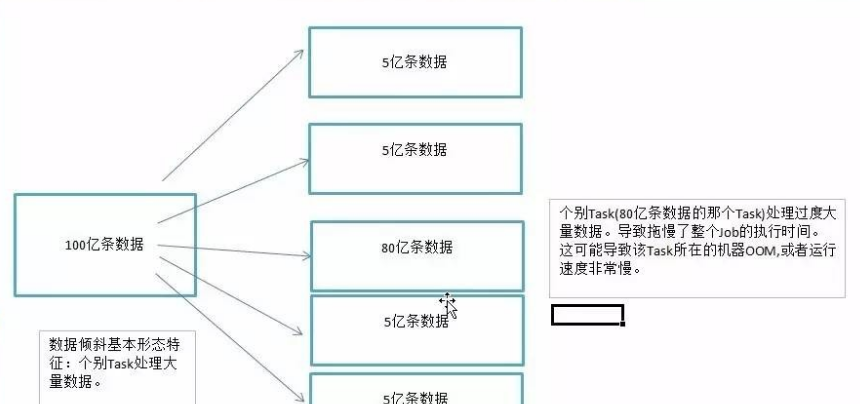
一個經驗結論是:一般情況下,OOM的原因都是資料傾斜
資料傾斜一般會發生在shuffle過程中。很大程度上是你使用了可能會觸發shuffle操作的算子:distinct、groupByKey、reduceByKey、aggregateByKey、join、cogroup、repartition等。
原因:檢視任務->檢視Stage->檢視代碼
某個task執行特别慢的情況
某個task莫名其妙記憶體溢出的情況
檢視導緻資料傾斜的key的資料分布情況

也可從以下幾種情況考慮:
1、是不是有OOM情況出現,一般是少數記憶體溢出的問題
2、是不是應用運作時間差異很大,總體時間很長
3、需要了解你所處理的資料Key的分布情況,如果有些Key有大量的條數,那麼就要小心資料傾斜的問題
4、一般需要通過Spark Web UI和其他一些監控方式出現的異常來綜合判斷
5、看看代碼裡面是否有一些導緻Shuffle的算子出現
3.1 資料源中的資料分布不均勻,Spark需要頻繁互動
3.2 資料集中的不同Key由于分區方式,導緻資料傾斜
3.3 JOIN操作中,一個資料集中的資料分布不均勻,另一個資料集較小(主要)
3.4 聚合操作中,資料集中的資料分布不均勻(主要)
3.5 JOIN操作中,兩個資料集都比較大,其中隻有幾個Key的資料分布不均勻
3.6 JOIN操作中,兩個資料集都比較大,有很多Key的資料分布不均勻
3.7 資料集中少數幾個key資料量很大,不重要,其他資料均勻
注意:
1、需要處理的資料傾斜問題就是Shuffle後資料的分布是否均勻問題
2、隻要保證最後的結果是正确的,可以采用任何方式來處理資料傾斜,隻要保證在處理過程中不發生資料傾斜就可以
<code>解決方案</code>:避免資料源的資料傾斜
<code>實作原理</code>:通過在Hive中對傾斜的資料進行預處理,以及在進行kafka資料分發時盡量進行平均配置設定。這種方案從根源上解決了資料傾斜,徹底避免了在Spark中執行shuffle類算子,那麼肯定就不會有資料傾斜的問題了。
<code>方案優點</code>:實作起來簡單便捷,效果還非常好,完全規避掉了資料傾斜,Spark作業的性能會大幅度提升。
<code>方案缺點</code>:治标不治本,Hive或者Kafka中還是會發生資料傾斜。
<code>适用情況</code>:在一些Java系統與Spark結合使用的項目中,會出現Java代碼頻繁調用Spark作業的場景,而且對Spark作業的執行性能要求很高,就比較适合使用這種方案。将資料傾斜提前到上遊的Hive ETL,每天僅執行一次,隻有那一次是比較慢的,而之後每次Java調用Spark作業時,執行速度都會很快,能夠提供更好的使用者體驗。
總結:前台的Java系統和Spark有很頻繁的互動,這個時候如果Spark能夠在最短的時間内處理資料,往往會給前端有非常好的體驗。這個時候可以将資料傾斜的問題抛給資料源端,在資料源端進行資料傾斜的處理。但是這種方案沒有真正的處理資料傾斜問題。
<code>解決方案1</code>:調整并行度
<code>實作原理</code>:增加shuffle read task的數量,可以讓原本配置設定給一個task的多個key配置設定給多個task,進而讓每個task處理比原來更少的資料。
<code>方案優點</code>:實作起來比較簡單,可以有效緩解和減輕資料傾斜的影響。
<code>方案缺點</code>:隻是緩解了資料傾斜而已,沒有徹底根除問題,根據實踐經驗來看,其效果有限。
<code>實踐經驗</code>:該方案通常無法徹底解決資料傾斜,因為如果出現一些極端情況,比如某個key對應的資料量有100萬,那麼無論你的task數量增加到多少,都無法處理。
總結:調整并行度:适合于有大量key由于分區算法或者分區數的問題,将key進行了不均勻分區,可以通過調大或者調小分區數來試試是否有效
解決方案2:
緩解資料傾斜(自定義Partitioner)
<code>适用場景</code>:大量不同的Key被配置設定到了相同的Task造成該Task資料量過大。
<code>解決方案</code>: 使用自定義的Partitioner實作類代替預設的HashPartitioner,盡量将所有不同的Key均勻配置設定到不同的Task中。
<code>優勢</code>: 不影響原有的并行度設計。如果改變并行度,後續Stage的并行度也會預設改變,可能會影響後續Stage。
<code>劣勢</code>: 适用場景有限,隻能将不同Key分散開,對于同一Key對應資料集非常大的場景不适用。效果與調整并行度類似,隻能緩解資料傾斜而不能完全消除資料傾斜。而且需要根據資料特點自定義專用的Partitioner,不夠靈活。
解決方案:Reduce side Join轉變為Map side Join
<code>方案适用場景</code>:在對RDD使用join類操作,或者是在Spark SQL中使用join語句時,而且join操作中的一個RDD或表的資料量比較小(比如幾百M),比較适用此方案。
<code>方案實作原理</code>:普通的join是會走shuffle過程的,而一旦shuffle,就相當于會将相同key的資料拉取到一個shuffle read task中再進行join,此時就是reduce join。但是如果一個RDD是比較小的,則可以采用廣播小RDD全量資料+map算子來實作與join同樣的效果,也就是map join,此時就不會發生shuffle操作,也就不會發生資料傾斜。
<code>方案優點</code>:對join操作導緻的資料傾斜,效果非常好,因為根本就不會發生shuffle,也就根本不會發生資料傾斜。
<code>方案缺點</code>:适用場景較少,因為這個方案隻适用于一個大表和一個小表的情況。
<code>解決方案</code>:兩階段聚合(局部聚合+全局聚合)
<code>适用場景</code>:對RDD執行reduceByKey等聚合類shuffle算子或者在Spark SQL中使用group by語句進行分組聚合時,比較适用這種方案
<code>實作原理</code>:将原本相同的key通過附加随機字首的方式,變成多個不同的key,就可以讓原本被一個task處理的資料分散到多個task上去做局部聚合,進而解決單個task處理資料量過多的問題。接着去除掉随機字首,再次進行全局聚合,就可以得到最終的結果。具體原理見下圖。
<code>優點</code>:對于聚合類的shuffle操作導緻的資料傾斜,效果是非常不錯的。通常都可以解決掉資料傾斜,或者至少是大幅度緩解資料傾斜,将Spark作業的性能提升數倍以上。
<code>缺點</code>:僅僅适用于聚合類的shuffle操作,适用範圍相對較窄。如果是join類的shuffle操作,還得用其他的解決方案将相同key的資料分拆處理
<code>解決方案</code>:為傾斜key增加随機前/字尾
<code>适用場景</code>:兩張表都比較大,無法使用Map側Join。其中一個RDD有少數幾個Key的資料量過大,另外一個RDD的Key分布較為均勻。
<code>解決方案</code>:将有資料傾斜的RDD中傾斜Key對應的資料集單獨抽取出來加上随機字首,另外一個RDD每條資料分别與随機字首結合形成新的RDD(笛卡爾積,相當于将其資料增到到原來的N倍,N即為随機字首的總個數),然後将二者Join後去掉字首。然後将不包含傾斜Key的剩餘資料進行Join。最後将兩次Join的結果集通過union合并,即可得到全部Join結果。
<code>優勢</code>:相對于Map側Join,更能适應大資料集的Join。如果資源充足,傾斜部分資料集與非傾斜部分資料集可并行進行,效率提升明顯。且隻針對傾斜部分的資料做資料擴充,增加的資源消耗有限。
<code>劣勢</code>:如果傾斜Key非常多,則另一側資料膨脹非常大,此方案不适用。而且此時對傾斜Key與非傾斜Key分開處理,需要掃描資料集兩遍,增加了開銷。
注意:具有傾斜Key的RDD資料集中,key的數量比較少
<code>解決方案</code>:随機字首和擴容RDD進行join
<code>适用場景</code>:如果在進行join操作時,RDD中有大量的key導緻資料傾斜,那麼進行分拆key也沒什麼意義。
<code>實作思路</code>:将該RDD的每條資料都打上一個n以内的随機字首。同時對另外一個正常的RDD進行擴容,将每條資料都擴容成n條資料,擴容出來的每條資料都依次打上一個0~n的字首。最後将兩個處理後的RDD進行join即可。和上一種方案是盡量隻對少數傾斜key對應的資料進行特殊處理,由于處理過程需要擴容RDD,是以上一種方案擴容RDD後對記憶體的占用并不大;而這一種方案是針對有大量傾斜key的情況,沒法将部分key拆分出來進行單獨處理,是以隻能對整個RDD進行資料擴容,對記憶體資源要求很高。
<code>優點</code>:對join類型的資料傾斜基本都可以處理,而且效果也相對比較顯著,性能提升效果非常不錯。
<code>缺點</code>:該方案更多的是緩解資料傾斜,而不是徹底避免資料傾斜。而且需要對整個RDD進行擴容,對記憶體資源要求很高。
<code>實踐經驗</code>:曾經開發一個資料需求的時候,發現一個join導緻了資料傾斜。優化之前,作業的執行時間大約是60分鐘左右;使用該方案優化之後,執行時間縮短到10分鐘左右,性能提升了6倍。
注意:将傾斜Key添加1-N的随機字首,并将被Join的資料集相應的擴大N倍(需要将1-N數字添加到每一條資料上作為字首)
<code>解決方案</code>:過濾少數傾斜Key
<code>适用場景</code>:如果發現導緻傾斜的key就少數幾個,而且對計算本身的影響并不大的話,那麼很适合使用這種方案。比如99%的key就對應10條資料,但是隻有一個key對應了100萬資料,進而導緻了資料傾斜。
<code>優點</code>:實作簡單,而且效果也很好,可以完全規避掉資料傾斜。
<code>缺點</code>:适用場景不多,大多數情況下,導緻傾斜的key還是很多的,并不是隻有少數幾個。
<code>實踐經驗</code>:在項目中我們也采用過這種方案解決資料傾斜。有一次發現某一天Spark作業在運作的時候突然OOM了,追查之後發現,是Hive表中的某一個key在那天資料異常,導緻資料量暴增。是以就采取每次執行前先進行采樣,計算出樣本中資料量最大的幾個key之後,直接在程式中将那些key給過濾掉。
猜你喜歡
Hive計算最大連續登陸天數
Hadoop 資料遷移用法詳解
Hbase修複工具Hbck
數倉模組化分層理論
一文搞懂Hive的資料存儲與壓縮
大資料元件重點學習這幾個