本文将介紹 vivo 内部容器化平台跨大版本無損更新中遇到的問題和解決方法,以期幫助讀者更快速、更安全的更新自己的叢集。
活躍的社群和廣大的使用者群,使 Kubernetes 仍然保持3個月一個版本的高頻釋出節奏。高頻的版本釋出帶來了更多的新功能落地和 bug 及時修複,但是線上環境業務長期運作,任何變更出錯都可能帶來巨大的經濟損失,更新對企業來說相對吃力,緊跟社群更是幾乎不可能,是以高頻釋出和穩定生産之間的沖突需要容器團隊去衡量和取舍。
vivo 網際網路團隊建設大規模 Kubernetes 叢集以來,部分叢集較長時間一直使用 v1.10 版本,但是由于業務容器化比例越來越高,對大規模叢集穩定性、應用釋出的多樣性等訴求日益攀升,叢集更新迫在眉睫。叢集更新後将解決如下問題:
高版本叢集在大規模場景做了優化,更新可以解決一系列性能瓶頸問題。
高版本叢集才能支援 OpenKruise 等 CNCF 項目,更新可以解決版本依賴問題。
高版本叢集增加的新特性能夠提高叢集資源使用率,降低伺服器成本同時提高叢集效率。
公司内部維護多個不同版本叢集,更新後減少叢集版本碎片化,進一步降低運維成本。
這篇文章将會從0到1的介紹 vivo 網際網路團隊支撐線上業務的叢集如何在不影響原有業務正常運作的情況下從 v1.10 版本更新到 v1.17 版本。之是以更新到 v1.17 而不是更高的 v1.18 以上版本, 是因為在 v1.18 版本引入的代碼變動 [1] 會導緻 extensions/v1beta1 等進階資源類型無法繼續運作(這部分代碼在 v1.18 版本删除)。
容器叢集搭建通常有二進制 systemd 部署和核心元件靜态 Pod 容器化部署兩種方式,叢集 API 服務多副本對外負載均衡。兩種部署方式在更新時沒有太大差別,二進制部署更貼合早期叢集,是以本文将對二進制方式部署的叢集更新做分享。
對二進制方式部署的叢集,叢集元件更新主要是二進制的替換、配置檔案的更新和服務的重新開機;從生産環境 SLO 要求來看,更新過程務必不能因為叢集元件自身邏輯變化導緻業務重新開機。是以更新的難點集中在下面幾點:
首先,目前内部叢集運作版本較低,但是運作容器數量卻很多,其中部分仍然是單副本運作,為了不影響業務運作,需要盡可能避免容器重新開機,這無疑是更新中最大的難點,而在 v1.10 版本和 v1.17 版本之間,kubelet 關于容器 Hash 值計算方式發生了變化,也就是說一旦更新必然會觸發 kubelet 重新啟動容器。
其次,社群推薦的方式是基于偏差政策 [2] 的更新以保證高可用叢集更新同時不會因為 API resources 版本差異導緻 kube-apiserve 和 kubelet 等元件出現相容性錯誤,這就要求每次更新元件版本不能有2個 Final Release 以上的偏差,比如直接從 v1.11 更新至 v1.13是不推薦的。
再次,更新過程中由于新特性的引入,API 相容性可能引發舊版本叢集的配置不生效,為整個叢集埋下穩定性隐患。這便要求在更新前盡可能的熟悉更新版本間的 ChangeLog,排查出可能帶來潛在隐患的新特性。
針對前述的難點,本節将逐個提出針對性解決方案,同時也會介紹更新後遇到的高版本 bug 和解決方法。希望關于更新前期相容性篩查和更新過程中排查的問題能夠給讀者帶來啟發。
在軟體領域,主流的應用更新方式有兩種,分别是原地更新和替換更新。目前這兩種更新方式在業内網際網路大廠均有采用,具體方案選擇與叢集上業務有很大關系。
1)Kubernetes 替換更新是先準備一個高版本叢集,對低版本叢集通過逐個節點排幹、删除最後加入新叢集的方式将低版本叢集内節點逐漸輪換更新到新版本。 2)替換更新的優點是原子性更強,逐漸更新各個節點,更新過程不存在中間态,對業務安全更有保障;缺點是叢集更新工作量較大,排幹操作對pod重新開機敏感度高的應用、有狀态應用、單副本應用等都不友好。
1)Kubernetes 原地更新是對節點上服務如 kube-controller-manager、 kubelet 等元件按照一定順序批量更新,從節點角色次元批量管理元件版本。 2)原地更新的優點是自動化操作便捷,并且通過适當的修改能夠很好的保證容器的生命周期連續性;缺點是叢集更新中元件更新順序很重要,更新中存在中間态,并且一個元件重新開機失敗可能影響後續其他元件更新,原子性差。
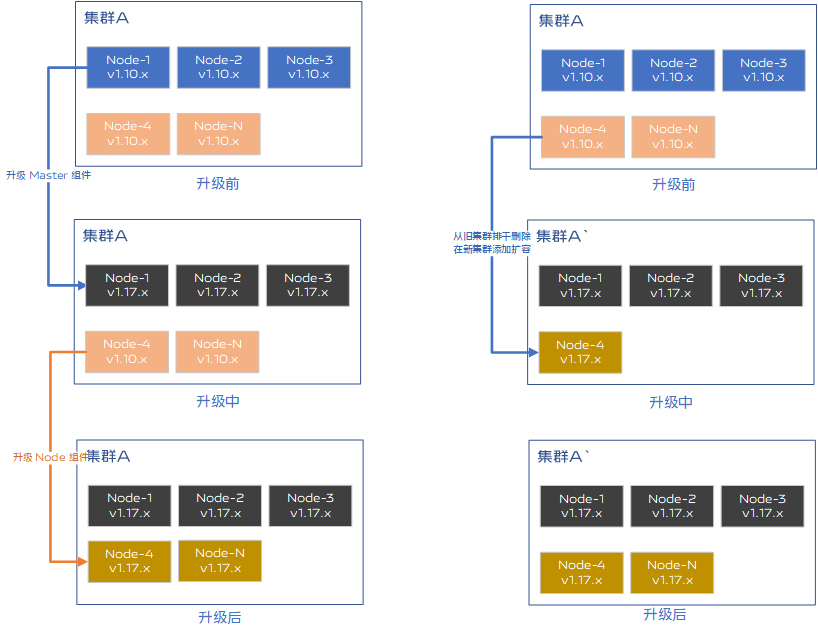
vivo 容器叢集上運作的部分業務對重新開機容忍度較低,盡可能避免容器重新開機是更新工作的第一要務。當解決好更新版本帶來的容器重新開機後,結合業務容器化程度和業務類型不同,因地制宜的選擇更新方式即可。二進制部署叢集建議選擇原地更新的方式,具有時間短,操作簡捷,單副本業務不會被更新影響的好處。
由于Kubernetes 本身是基于 API 的微服務架構,Kuberntes 内部架構也是通過 API 的調用和對資源對象的 List-Watch 來協同資源狀态,是以社群開發者在設計 API 時遵循向上或向下相容的原則。這個相容性規則也是遵循社群的偏差政策 [2],即 API groups 棄用、啟用時,對于 Alpha 版本會立即生效,對于 Beta 版本将會繼續支援3個版本,超過對應版本将導緻 API resource version 不相容。例如 kubernetes 在 v1.16 對 Deployment 等資源的 extensions/v1beta1 版本執行了棄用,在v1.18 版本從代碼級别執行了删除,當跨3個版本以上更新時會導緻相關資源無法被識别,相應的增删改查操作都無法執行。
如果按照官方建議的更新政策,從 v1.10 更新到 v1.17 需要經過至少 7 次更新,這對于業務場景複雜的生産環境來說運維複雜度高,業務風險大。
對于類似的 API breaking change 并不是每個版本都會存在,社群建議的偏差政策是最安全的更新政策,經過細緻的 Change Log 梳理和充分的跨版本測試,我們确認這幾個版本之間不能存在影響業務運作和叢集管理操作的 API 相容性問題,對于 API 類型的廢棄,可以通過配置 apiserver 中相應參數來啟動繼續使用,保證環境業務繼續正常運作。
在初步驗證更新方案時發現大量容器都被重建,重新開機原因從更新後 kubelet 元件日志看到是 "Container definition changed"。結合源碼報錯位于 pkg/kubelet/kuberuntime_manager.go 檔案 computePodActions 方法,該方法用來計算 pod 的 spec 哈希值是否發生變化,如果變化則傳回 true,告知 kubelet syncPod 方法觸發 pod 内容器重建或者 pod 重建。
kubelet 容器 Hash 計算;
相對于 v1.10 版本,v1.17 版本在計算容器 Hash 時使用的是 container 結構 json 序列化後的資料,而不是 v1.10 版本使用 container struct 的結構資料。而且高版本 kubelet 中對容器的結構也增加了新的屬性,通過 go-spew 庫計算出結果自然不一緻,進一步向上傳遞傳回值使得 syncPod 方法觸發容器重建。
那是否可以通過修改 go-spew 對 container struct 的資料結構剔除新增的字段呢? 答案是肯定的,但是卻不是優雅的方式,因為這樣對核心代碼邏輯侵入較為嚴重,以後每個版本的更新都需要定制代碼,并且新增的字段越來越多,維護複雜度也會越來越高。換個角度,如果在更新過渡期間将屬于舊版本叢集 kubelet 建立的 Pod 跳過該檢查,則可以避免容器重新開機。
和圈内同僚交流後發現類似思路在社群已有實作,本地建立一個記錄舊叢集版本資訊和啟動時間的配置檔案,kubelet 代碼中維護一個 cache 讀取配置檔案,在每個 syncPod 周期中,當 kubelet 發現自身 version 高于 cache 中記錄的 oldVersion, 并且容器啟動時間早于目前 kubelet 啟動時間,則會跳過容器 Hash 值計算。更新後的叢集内運作定時任務探測 Pod 的 containerSpec 是否與高版本計算方式計算得到 Hash 結果全部一緻,如果是則可以删除掉本地配置檔案,syncPod 邏輯恢複到與社群完全一緻。
具體方案參考這種實作的好處是對原生 kubelet 代碼侵入小,沒有改變核心代碼邏輯,而且未來如果還需要更新高版本也可以複用該代碼。如果叢集内所有 Pod 都是目前版本 kubelet 建立,則會恢複到社群自身的邏輯。

Kubernetes 雖然疊代了十幾個版本,但是每個疊代社群活躍度仍然很高,保持着每個版本大約30個關于拓展性增強和穩定性提升的新特性。選擇更新很大一方面原因是引入很多社群開發的新特性來豐富叢集的功能與提升叢集穩定性。新特性開發也是遵循偏差政策,跨大版本更新很可能導緻在部配置設定置未加載的情況下啟用新特性,這就給叢集帶來穩定性風險,是以需要梳理影響 Pod 生命周期的一些特性,尤其關注控制器相關的功能。
這裡注意到在 v1.13 版本引入的 TaintBasedEvictions 特性用于更細粒度的管理 Pod 的驅逐條件。在 v1.13基于條件版本之前,驅逐是基于 NodeController 的統一時間驅逐,節點 NotReady 超過預設5分鐘後,節點上的 Pod 才會被驅逐;在 v1.16 預設開啟 TaintBasedEvictions 後,節點 NotReady 的驅逐将會根據每個 Pod 自身配置的 TolerationSeconds 來差異化的處理。
舊版本叢集建立的 Pod 預設沒有設定 TolerationSeconds,一旦更新完畢 TaintBasedEvictions 被開啟,節點變成 NotReady 後 5 秒就會驅逐節點上的 Pod。對于短暫的網絡波動、kubelet 重新開機等情況都會影響叢集中業務的穩定性。
TaintBasedEvictions 對應的控制器是按照 pod 定義中的 tolerationSeconds 決定 Pod 的驅逐時間,也就是說隻要正确設定 Pod 中的 tolerationSeconds 就可以避免出現 Pod 的非預期驅逐。
在v1.16 版本社群預設開啟的 DefaultTolerationSeconds 準入控制器基于 k8s-apiserver 輸入參數 default-not-ready-toleration-seconds 和 default-unreachable-toleration-seconds 為 Pod 設定預設的容忍度,以容忍 notready:NoExecute 和 unreachable:NoExecute 污點。
建立 Pod 在請求發送後會經過 DefaultTolerationSeconds 準入控制器給 pod 加上預設的 tolerations。但是這個邏輯如何對叢集中已經建立的 Pod 生效呢?檢視該準入控制器發現除了支援 create 操作,update 操作也會更新 pod 定義觸發 DefaultTolerationSeconds 插件去設定 tolerations。是以我們通過給叢集中已經運作的 Pod 打 label 就可以達成目的。
為了判斷更新時 Pod 是否發生非預期的驅逐以及是否存在 Pod 内容器批量重新開機,有腳本去實時同步節點上非Running狀态的Pod和發生重新開機的容器。
在更新過程中,突然多出來數十個 pod 被标記為 MatchNodeSelector 狀态,檢視該節點上業務容器确實停止。kubelet 日志中看到如下錯誤日志;
經分析,Pod 變成 MatchNodeSelector 狀态是因為 kubelet 重新開機時對節點上 Pod 做準入檢查時無法找到節點滿足要求的節點标簽,pod 狀态就會被設定為 Failed 狀态,而 Reason 被設定為 MatchNodeSelector。在 kubectl 指令擷取時,printer 做了相應轉換直接顯示了Reason,是以我們看到 Pod 狀态是 MatchNodeSelector。通過給節點加上标簽,可以讓 Pod 重新排程回來,然後删除掉 MatchNodeSelector 狀态的 Pod 即可。
建議在更新前寫腳本檢查節點上 pod 定義中使用的 NodeSelector 屬性節點是否都有對應的 Label。
預發環境更新後的叢集運作在 v1.17 版本後,突然有節點變成 NotReady 狀态告警,分析後通過重新開機 kubelet 節點恢複正常。繼續分析出錯原因發現 kubelet 日志中出現了大量 use of closed network connection 報錯。在社群搜尋相關 issue 發現有類似的問題,其中有開發者描述了問題的起因和解決辦法,并且在 v1.18 已經合入了代碼。
問題的起因是 kubelet 預設連接配接是 HTTP/2.0 長連接配接,在建構 client 到 server的連接配接時使用的 golang net/http2 包存在 bug,在 http 連接配接池中仍然能擷取到 broken 的連接配接,也就導緻 kubelet 無法正常與 kube-apiserver 通信。
golang社群通過增加 http2 連接配接健康檢查規避這個問題,但是這個 fix 仍然存在 bug ,社群在 golang v1.15.11 版本徹底修複。我們内部通過 backport 到 v1.17 分支,并使用 golang 1.15.15 版本編譯二進制解決了此問題。
在預釋出環境測試運作期間,偶然發現叢集每個節點 kubelet 都有近10個長連接配接與 kube-apiserver 通信,這與我們認知的 kubelet 會複用連接配接與 kube-apiserver 通信明顯不符,檢視 v1.10 版本環境也确實隻有1個長連接配接。這種 TCP 連接配接數增加情況無疑會對 LB 造成了壓力,随着節點增多,一旦 LB 被拖垮,kubelet 無法上報心跳,節點會變成 NotReady,緊接着将會有大量 Pod 被驅逐,後果是災難性的。是以除去對 LB 本身參數調優外,還需要定位清楚kubelet 到 kube-apiserver 連接配接數增加的原因。
在本地搭建的 v1.17.1 版本 kubeadm 叢集 kubelet 到 kube-apiserver 也僅有1個長連接配接,說明這個問題是在 v1.17.1 到更新目标版本之間引入的,排查後(問題)發現增加了判斷邏輯導緻 kubelet 擷取 client 時不再從 cache 中擷取緩存的長連接配接。transport 的主要功能其實就是緩存了長連接配接,用于大量 http 請求場景下的連接配接複用,減少發送請求時 TCP(TLS) 連接配接建立的時間損耗。在該 PR 中對 transport 自定義 RoundTripper 的接口,一旦 tlsConfig 對象中有 Dial 或者 Proxy 屬性,則不使用 cache 中的連接配接而建立連接配接。
在這裡建構 closeAllConns 對象來關閉已經處于 Dead 但是尚未 Close 的連接配接,但是上一個問題通過更新 golang 版本解決了這個問題,是以我們在本地代碼分支回退了該修改中的部分代碼解決了 TCP 連接配接數增加的問題。
最近追蹤社群發現已經合并了解決方案 ,通過重構 client-go 的接口實作對自定義 RESTClient 的 TCP 連接配接複用。
跨版本更新最大的風險是更新前後對象定義不一緻,可能導緻更新後的元件無法解析儲存在 ETCD 資料庫中的對象;也可能是更新存在中間态,kubelet 還未更新而控制平面元件更新,存在上報狀态異常,最壞的情況是節點上 Pod 被驅逐。這些都是更新前需要考慮并通過測試驗證的。
經過反複測試,上述問題在 v1.10 到 v1.17 之間除了部分廢棄的 API Resources 通過增加 kube-apiserver 配置方式其他情況暫時不存在。為了保證更新時及時能處理未覆寫到的特殊情況,強烈建議更新前備份 ETCD 資料庫,并在更新期間停止控制器和排程器,避免非預期的控制邏輯發生(實際上這裡應該是停止 controller manager 中的部分控制器,不過需要修改代碼編譯臨時 controller manager ,增加了更新流程步驟和管理複雜度,是以直接停掉了全局控制器)。
除卻以上代碼變動和更新流程注意事項,在替換二進制更新前,就剩下比對新老版本服務的配置項的差別以保證服務成功啟動運作。對比後發現,kubelet 元件啟動時不再支援 --allow-privileged 參數,需要删除。值得說明的是,删除不代表高版本不再支援節點上運作特權容器,在 v1.15 以後通過 Pod Security Policy 資源對象來定義一組 pod 通路的安全特征,更細粒度的做安全管控。
基于上面讨論的無損更新代碼側的修改編譯二進制,再對叢集元件配置檔案中各個配置項修改後,就可以着手線上更新。整個更新步驟為:
備份叢集(二進制,配置檔案,ETCD資料庫等);
灰階更新部分節點,驗證二進制和配置檔案正确性
提前分發更新的二進制檔案;
停止控制器、排程器和告警;
更新控制平面服務配置檔案,更新元件;
更新計算節點服務配置檔案,更新元件;
為節點打 Label 觸發 pod 增加 tolerations 屬性;
打開控制器和排程器,啟用告警;
叢集業務點檢,确認叢集正常。
更新過程中建議節點并發數不要太高,因為大量節點 kubelet 同時重新開機上報資訊,對 kube-apiserver 前面使用的 LB 帶來沖擊,特别情況下可能節點心跳上報失敗,節點狀态會在 NotReady 與 Ready 狀态間跳動。
叢集更新是困擾容器團隊比較長時間的事,在經過一系列調研和反複測試,解決了上面提到的數個關鍵問題後,成功将叢集從 v1.10 更新到 v1.17 版本,1000 個節點的叢集分批執行更新操作,大概花費 10 分鐘,後續在完成平台接口改造後将會再次更新到更高版本。
叢集版本更新提高了叢集的穩定性、增加了叢集的擴充性,同時還豐富了叢集的能力,更新後的叢集也能夠更好的相容 CNCF 項目。
如開篇所述,按照偏差政策頻繁對大規模叢集更新可能不太現實,是以跨版本更新雖然風險較大,但是也是業界廣泛采用的方式。在 2021 年中國 KubeCon 大會上,阿裡巴巴也有關于零停機跨版本更新 Kubernetes 叢集的分享,主要是關于應用遷移、流量切換等更新關鍵點的介紹,更新的準備工作和更新過程相對複雜。相對于阿裡巴巴的叢集跨版本替換更新方案,原地更新的方式需要在源碼上做少量修改,但是更新過程會更簡單,運維自動化程度更高。
由于叢集版本具有很大的可選擇性,本文所述的更新并不一定廣泛适用,筆者更希望給讀者提供生産叢集在跨版本更新時的思路和風險點。更新過程短暫,但是更新前的準備和調研工作是費時費力的,需要對不同版本 Kubernetes 特性和源碼深入探索,同時對 Kubernetes 的 API 相容性政策和釋出政策擁有完整認知,這樣便能在更新前做出充分的測試,也能更從容面對更新過程中突發情況。
[1]https://github.com
[2] https://kubernetes.io/version-skew-policy
[3] 具體方案參考:https://github.comstart
[4] 類似的問題: https://github.com/kubernetes
[5] https://github.com/golang/34978
[6] https://github.com/kubernetes/100376
[7] https://github.com/kubernetes/95427
[8] https://github.com/kubernetes/105490
作者:vivo網際網路伺服器團隊-Shu Yingya
分享 vivo 網際網路技術幹貨與沙龍活動,推薦最新行業動态與熱門會議。