spark 是基于記憶體計算的 大資料分布式計算架構,spark基于記憶體計算,提高了在大資料環境下處理的實時性,同時保證了高容錯性和高可伸縮性,允許使用者将spark部署在大量廉價的硬體上,形成叢集。
1. 分布式計算
2. 記憶體計算
3. 容錯
4. 多計算範式
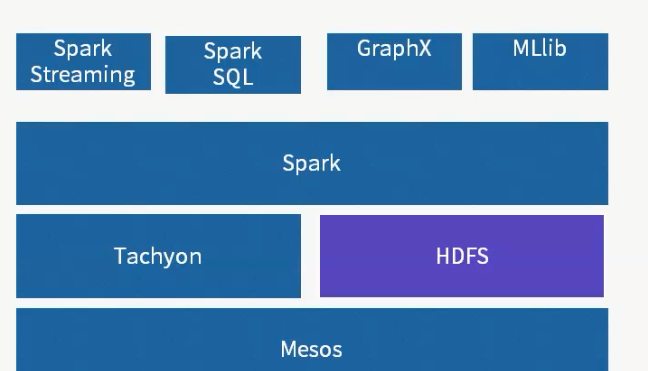
1 Messos 作為資源管理架構。相當于yarn,進行資源管理以及排程。
2 spark生态系統,不提供存儲層,可以調用外部存儲,例如HDFS
3 Tachyon 是 分布式記憶體檔案系統,能夠緩存資料,并提供資料快速讀寫。
4 spark 是核心計算引擎,能夠将任務并行化,在大規模叢集中進行資料計算。
5 spark streaming是 流式計算引擎,能夠将輸入資料切分成小的批次,對每個批次采用spark的計算範式,進行計算。
6 spark sql 是 sql on hadoop 系統,能夠提供互動式查詢,以及報表查詢,并且可以通過jdbc 調用
7 graphx 是 圖計算引擎,能夠完成大規模圖運算。
8 mlib 是 機器學習庫,提供聚類,分類,以及推薦的基本學習算法。 spark優勢
1 計算範式支援 打造多棧計算範式的高效資料流水線
2 處理速度,輕量級快速處理
3 易用性, 分布式RDD抽象,spark支援多語言
4 相容性,與HDFS等存儲層相容 spark的架構
1.spark架構元件簡介
spark叢集中master負責叢集整體資源管理和排程,worker負責帶個節點的資源管理, mater ---> slave 模型, Driver程式是應用邏輯執行的起點,而多個Executor用來對資料進行并行處理
spark的構成:
ClusterManager: 在standalone模式中即為: master: 主節點,控制整個叢集,監控worker.在yarn模式中為資料總管.
Worker: 從節點,負責控制計算節點,啟動Executor或Driver, 在yarn模式中為nodemanager,負責計算節點的控制。
Driver: 運作application的main()函數并且建立sparkcontext
Executor: 執行器,是為某application運作在worker node上的一個程序,啟動程序池運作任務上,每個application擁有獨立的一組executors.
sparkcontext: 整個應用的上下文,控制應用的生命周期
RDD: spark的基本計算單元, 一組RDD形成執行的有向無環圖RDD Graph。
2.spark 架構圖
3. spark叢集執行機制
spark的工作機制
spark的排程原理
spark 在 yarn叢集搭建詳細情況
spark 官方提供4種 叢集部署方案
Spark Mesos模式:官方推薦模式,通用叢集管理,有兩種排程模式:粗粒度模式(Coarse-grained Mode)與細粒度模式(Fine-grained Mode);
Spark YARN模式:Hadoop YARN資源管理模式;
Standalone模式: 簡單模式或稱獨立模式,可以單獨部署到一個叢集中,無依賴任何其他資源管理系統。不使用其他排程工具時會存在單點故障,使用Zookeeper等可以解決;
Local模式:本地模式,可以啟動本地一個線程來運作job,可以啟動N個線程或者使用系統所有核運作job; 第一 Stanalone模式叢集安裝,spark standalone模式的叢集由master 與worker節點組成,程式通過與master節點互動互相申請資源,worker節點啟動executor運作。
spark官方要求 scala版本為2.10 以下,
安裝下載下傳安裝
[root@spark_master ~]# https://codeload.github.com/scala/scala/tar.gz/v2.12.1
[root@spark_master ~]# tar -zxvf scala-2.12.1.tar.gz
檢視主機名 [root@spark_master ~]# cat /etc/hosts 192.168.20.213 spark_salve1
192.168.20.214 spark_salve2
下載下傳spark
[root@spark_manager ~]# wget http://d3kbcqa49mib13.cloudfront.net/spark-2.0.2-bin-hadoop2.7.tgz [root@spark_manager conf]# tar -zxvf spark-2.0.2-bin-hadoop2.7.tgz -C /data/spark [root@spark_manager conf]#cd /data/spark/conf [root@spark_manager conf]#
spark2.0.2 standalone 叢集模式安裝 [root@spark_manager conf]# mv slaves.template slaves [root@spark_manager conf]# mv spark-env.sh.template spark-env.sh [root@spark_manager conf]# cat slaves spark_manager
spark_salve1
spark_salve2 [root@spark_manager conf]#mv spark-env.sh.template spark-env.sh 啟動叢集: 1.啟動manager
[root@spark_manager sbin]# ./start-master.sh
2. 啟動slave(workers) [root@spark_slave1 sbin]# ./start-slave.sh 192.168.20.215:7077 [root@spark_slave2 sbin]# ./start-slave.sh 192.168.20.215:7077 #######################################################################################################################################
spark2.0.2 standalone HA 叢集模式安裝 多個slave的情況下自動具備了worker的HA,因為spark會将失敗的任務排程到其他worker上執行。但是,master還是有單點的,如果master故障了,那麼使用者就無法送出新的作業 了。注意,已經送出到worker的作業不受影響。
spark官方給出了2種解決方法,一個是使用zk做分布式協調,zk選主;另一個是使用基于LOCAL FILE SYSTEM恢複的單節點方案。第二種其實隻有1個master執行個體,當master故障後服務不可用,必須重新開機master程序,一般在生成系統上是不可接受的,是以我采用的是第一種方式。
一配置 zookeeper:略過
2. 主機名資訊:
192.168.20.215 spark_manager
192.168.20.211 standby_master
192.168.20.37 zookeeper1
192.168.20.38 zookeeper2
192.168.20.39 zookeepe3
第一台spark_manager
[root@spark_manager sbin]# ssh-keygen -t rsa
[root@spark_manager sbin]# ssh-copy-id -i /root/.ssh/id_rsa.pub [email protected]
[root@spark_manager sbin]# ssh-copy-id -i /root/.ssh/id_rsa.pub [email protected]
[root@spark_manager sbin]# ssh-copy-id -i /root/.ssh/id_rsa.pub [email protected]
[root@spark_manager sbin]# ssh-copy-id -i /root/.ssh/id_rsa.pub [email protected]
第二台spark_manager
[root@standby_master ~]# ssh-keygen -t rsa
[root@standby_manager sbin]# ssh-copy-id -i /root/.ssh/id_rsa.pub [email protected]
[root@standby_manager sbin]# ssh-copy-id -i /root/.ssh/id_rsa.pub [email protected]
[root@standby_manager sbin]# ssh-copy-id -i /root/.ssh/id_rsa.pub [email protected]
[root@standby_manager sbin]# ssh-copy-id -i /root/.ssh/id_rsa.pub [email protected]
[root@spark_manager conf]# mv slaves.template slaves [root@spark_manager conf]# mv spark-env.sh.template spark-env.sh [root@spark_manager conf]# cat slaves spark_salve1
spark_salve2 [root@spark_manager conf]# mv spark-env.sh.template spark-env.sh [root@spark_manager conf]# cat spark-env.sh
export SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=zookeeper1:2181,zookeeper2:2181,zookeeper3:2181 -Dspark.deploy.zookeeper.dir=/spark"
[root@spark_manager conf]# scp -r /data/spark 192.168.20.211:/data/ [root@spark_manager conf]# scp -r /data/spark 192.168.20.213:/data/ [root@spark_manager conf]# scp -r /data/spark 192.168.20.214:/data/
[root@spark_manager sbin]# ./start-all.sh
slave 出現

spark_manager不能識别,但是host已經指向了,修改了下面shell 啟動腳本主機名更改成IP。
[root@spark_manager data]# vim /data/spark/sbin/start-slaves.sh
[root@spark_manager sbin]# jps
6867 Worker
6934 Jps
6282 Master
[root@spark_salve1 data]# jps
4019 Jps
3941 Worker
[root@spark_slave2 ~]# jps
2565 Worker
2618 Jps
啟動standby_manager 程序
[root@standby_master sbin]# ./start-master.sh
[root@standby_master sbin]# jps
2655 Master
2735 Jps
HA 切換
kill 掉 spark_manager 上的 manager 程序,
檢視spark_salve 日志,表示已經切換。
standby_manager 日志。