iGraph是一個線上圖存儲和查詢服務,從2015年年初正式上線到現在,已經平穩經曆了3次雙十一大促的曆練。在這幾年的發展過程中,我們持續改進使用者接入體驗、跟TPP推薦業務平台一站式內建、線上服務品質持續保持穩定,這一些長期投入讓iGraph赢得了越來越多集團客戶的信任,其中包括集團的核心搜尋和推薦業務。随着支撐越來越多集團業務,iGraph已經發展成為集團線上服務架構中一個非常重要的基礎服務設施。為了支撐iGraph業務的快速增長,今年上半年我們開發了AutoUmars基礎管控元件,并基于此重構了iGraph管控系統。在剛剛過去的2017雙十一大促中,iGraph系統的各項核心業務名額達到了前所未有的峰值。
下面我們分享一些今年大促中iGraph的相關業務資料:
在中美俄三地提供了萬級别表數目的線上并發通路。
Proxy峰值入口通路QPS 千萬級别,Search通路QPS峰值達到億級别。
雙十一當天完成數萬次索引建構,産出數千TB的索引資料,完成資料回流數萬次。
為了能夠高效穩定地支撐今年雙十一,iGraph團隊面臨的問題非常具有挑戰,但是我們就是喜歡解決具有挑戰的問題,也非常樂此不疲。相信大家也對我們的問題和解決方案非常感興趣。這也是我們寫這篇文章的目的——介紹iGraph團隊如何通過自動化流量預估和基于機器學習的智能資料排程來高效支撐2017雙十一大促!
iGraph作為一個基礎查詢服務,流量預估跟一般的業務系統差異非常大——不能簡單通過目前流量乘以一個系數得到大促流量,主要展現在如下方面:
如上圖所示,iGraph調用方有上千個(僅僅TPP平台上場景的數目就超過上千個,這些場景幾乎都是iGraph的調用方),并且每個調用方通路iGraph的流量特征都不一樣(單次使用者請求處理通路iGraph的次數、表的數目、以及每張表通路的消耗等),每個調用方的峰值QPS千差萬别。
有一些調用方在大促期間查詢邏輯和日常的查詢邏輯不一樣,無法簡單根據日常通路流量進行放大得到大促流量。
對于一些大促常場景日常沒有流量,隻有大促當天才打開。
基于以上三點認識,我們就知道看似簡單的流量預估對于iGraph來說并不簡單。之前我們在業務體量較小的時候,是通過人肉進行跟業務方收集流量特征最終得出大促的峰值通路流量,這種出力不讨好的事情我們永遠不會再這麼幹了,因為今年我們我們開發了自動化流量預估系統,高效自動化解決上述問題。
假設我們已經成功估算出iGraph峰值流量了,現在我們已經知道所有表的峰值QPS。但是新的問題出現了,如上圖所示,那就是我們需要多少容器資源來支撐這些峰值QPS以及如何将這些表合理地部署到各個星座(在iGraph中,我們把一個小的容器矩陣稱為一個星座)中。每個容器的資源是有限的,這些資源包括CPU、記憶體、磁盤、可以加載的表總數等等。如何将這萬表排程到不同星座,使得每個星座的資源不會用超,并且盡可能讓所有星座資源使用率均衡稱為我們需要解決問題。這是一個帶限制運籌優化問題,所幸的是我們有iDst同學(@康托,@李濤)的幫忙。iDST智能決策團隊專注于與機器智能決策相關的深度學習、運籌優化技術的研究與賦能,目前已在集團内外,新零售、物流、資料中心、交通等多個行業領域得到應用。我們隻要把表的相關名額資訊、叢集拓撲資訊、目前表的部署資訊送出給他們,他們就可以給我們算出一個最優的且資料遷移代價較小的新的資料部署拓撲。
當上述均衡分布的問題解決後,再來看下之前出現的業務隔離做的不好的問題:單個業務方通路異常時會導緻加載在同一個星座中的其他業務都會受影響。我們做了以下幾點,問題也就迎刃而解:
每份資料會根據所屬業務方配置設定資源池标簽,在計算分布部署時會考慮資料所帶标簽:相同業務線的資料遷移隻會發生在自身的資源池内,這樣既保證了資料端的資源隔離,也可以支援業務線拆分的自動遷移
在Proxy端,我們按照業務通路進行了流量入口劃分,給業務方配置設定單獨的通路入口
基于上述兩點,從入口到資料層面都較好的實作了業務隔離。
這裡需要特别提一下的是,今年我們初步探索出一套單請求消耗CPU的模型,在這個模型上線之前,我們都是假設每個請求消耗的CPU是同等的,而實際上不同請求的CPU消耗相差特别大(這和請求的特征緊密相關,比如請求查詢的表類型、索引中查出來的結果數目、單條結果的大小、最終傳回的結果資料等等),導緻星座之間CPU使用率差異較大。上了新的模型之後,這個問題得到了很大的緩解,詳情參見後面大促資料。
如上兩個問題解決之後我們需要檢查上面兩項工作的成果是否符合預期。我們是通過大促全鍊路壓測的方式來驗證我們的流量預估是否準确以及表的部署是否合理(不能出現資料部分星座通路過高或者過低的情況)。這需要把我們的預估和實際壓測資料拿出來進行diff分析,包括表的QPS次元、星座QPS次元、星座CPU次元、場景QPS次元等。通過這個全面分析,我們一方面能夠check我們的流量預估和部署是否合理,另外一方面能夠找出壓測過程周某些場景流量壓多了或者壓少了,以及流量成分發生變化的情況,然後回報到調用方在下一輪壓測中解決。
既然問題已經定義清楚了,我們提出了如下圖所示的系統架構來極大提升我們今年雙十一大促準備工作的效率。整個項目由iGraph工程團隊和iDST算法同學合作完成
下圖是我們整體的系統架構。
下面介紹下各個元件的功能:
結合調用方自身QPS和iGraph中該調用方的各次元QPS資訊,流量成分分析對每一個調用方分析出如下結果:
調用方一次請求處理需要通路多少次iGraph Proxy
調用方一次請求處理需要通路多少張iGraph表,以及通路每張表的次數
針對大促場景,由于平時沒有流量,流量分析服務會在場景壓測期間進行特征分析
針對部分日常場景在大促期間流量特征發生變化的情況,流量特征分析服務會分别記錄日常流量特征和大促流量特征。在進行大促流量預估時,選擇大促流量特征進行預估。
根據上遊調用方流量峰值預估和iGraph中流量成分分析的結果就可以計算出每一種來源對iGraph Proxy峰值通路QPS和Search峰值通路QPS。
預估出所有場景的Proxy峰值通路QPS和Search峰值通路QPS之後進行疊加聚合,就可以得到iGraph服務Proxy層峰值通路QPS、Search峰值通路QPS以及每一張表的通路QPS。
表級别相關名額(記憶體、磁盤、QPS、Latency)容器相關名額(磁盤、記憶體、CPU消耗)都是通過KMonitor擷取,感謝Kmonitor同學為我們提供穩定metric系統支援,KMonitor是基于optsdb on druid架構的監控系統,支援api接口擷取監控資料。 kmonitor作為統一的監控平台來支撐業務監控和智能運維的相關需求。 關于kmonitor的詳細介紹可以參考Kmonitor監控平台。
容器相關的配置通過iGraph管控系統Autoumars擷取
表級别相關的計算名額我們重點收集了單表消耗記憶體、單表消耗磁盤、單表消CPU等名額,由于像記憶體、磁盤等名額是可以明确統計的,這裡就不做過多贅述。對于單表單次通路的CPU消耗我們初步建立了一個計算的模型:單個容器的CPU消耗取決于容器内所有表的通路QPS、通路rt、以及容器本身的一些特性。
$$
zoneCpuUsed_i = F(TableQps,TableRT,C_i)
C_i表示自容器自身的特性影響
zoneCpuUsed = \sum(TableQPS_n*TableRT_n)*zoneCpuWeight
TableCpuCostPerQuery = TableRT_n*zoneCpuWeight
zoneCpuUsed = \sum(TableQPS_n*TableCpuCostPerQuery_n)
根據上述的一些模型來計算單表單次通路的CPU消耗,結合預估的qps來計算單表CPU消耗。
由于iGraph業務的特殊性,部分資料表是不能進行遷移
單列容器内表無法進行遷移
原始odps分區缺失資料無法進行遷移
部分容器隻能遷出,無法遷入
預熱期和正常大促期間資料會發生替換,這種需要做表映射保證表下線後負載仍較為均衡。
......
這些資料會打上一定的無法遷移的标簽,在計算最佳分布邏輯時會考慮這些标簽,進行政策控制
算法同學會根據之前産出的叢集狀态快照作為優化引擎的輸入,優化引擎的輸出則是最終需要執行的遷移序列。
算法産出最終遷移序列之後,Autoumars将會自動掃描産出結果,解析完成後按照固定的批次順序執行遷移任務:
解析完成的遷移plan:
具體的遷移任務:
下面總結一下在今年大促期間的取得成果:
流量預估從原先的需要算法同學緊密配合,變成了算法同學無感覺,并且一天之内就能出一個版本的流量預估報告。
成功進行多輪的負載平滑遷移,共計進行了數萬次資料表遷移,将叢集中各個容器的CPU平均負載提高20%左右,磁盤使用率和記憶體使用率穩定在較高水位,未出現各個資源使用不均勻的情況。
大促效果
調整前各個星座負載狀态,單個柱狀圖表示了單項資源(記憶體、磁盤、cpu等)使用額度,标紅部分就是目前資源使用已經超出最大限制,遷移之後所有星座的負載都均衡了。
實際遷移plan執行完畢後CPU消耗的變化,可以明顯看出各個容器CPU消耗逐漸均衡
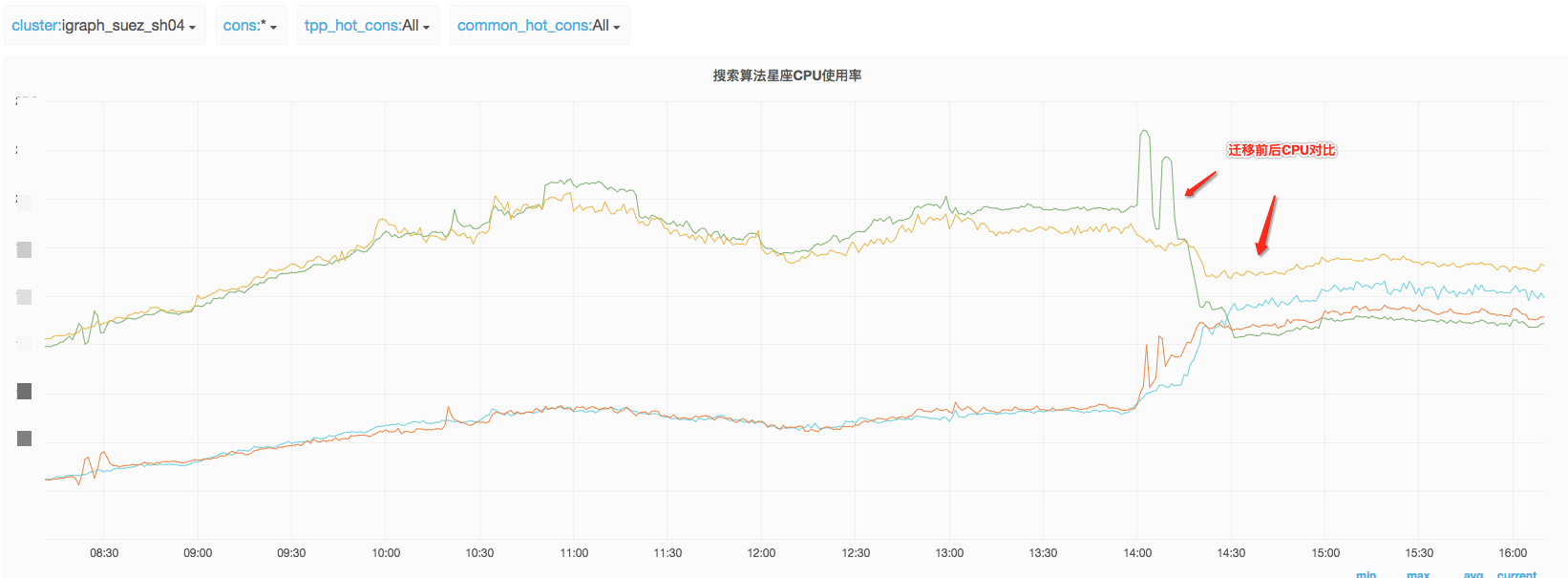
大促當天各個星座cpu負載基本均衡

今年是iGraph資料部署調整第一次和算法配合一起進行大促的動态調整,仍有很多的不足之處需要後續持續改進:
1.單表CPU計算的模型過于簡單,需要考慮searcher服務端多層cache對預估結果的影響,這種情況在壓測集比較小的場景下影響較大。另外表增量更新部分的開銷也需要考慮進來
2.在各輪壓測完畢後對比分析壓測情況和預估情況差異,目前這塊還隻有簡單的工具完成,還未內建到整套管控中去,産品化做的不夠好,需要不斷完善。
3.由于iGraph自身容器遷移成本較高,目前還不能支援實時排程,這塊也是後續的優化目标。另外如何用最小的遷移成本來達到平鋪的效果需要和算法同學一起研究下。