摘要:語音轉寫文字ASR技術的基本概念與數學原理簡介。
本文分享自華為雲社群《新手語音入門(三): 語音識别ASR算法初探 | 編碼與解碼 | 聲學模型與語音模型 | 貝葉斯公式 | 音素》,作者:黃辣雞 。
語音識别技術的發展已有數十年發展曆史,大體來看可以分成傳統的識别的方法和基于深度學習網絡的端到端的方法。
無論哪種方法,都會遵循“輸入-編碼-解碼-輸出”的過程。
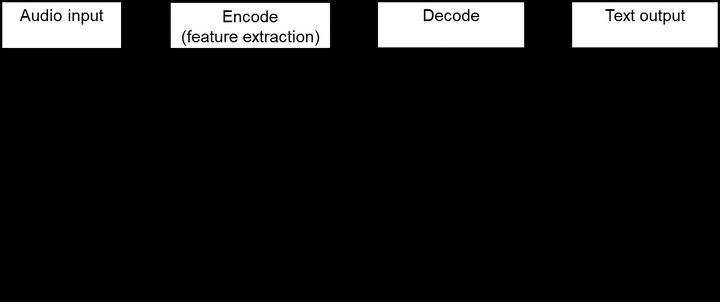
圖1 語音識别過程
語音識别的輸入是聲音,屬于計算機無法直接處理的信号,是以需要編碼過程将其轉變為數字資訊,并提取其中的特征進行處理。編碼時一般會将聲音信号按照很短的時間間隔,切成小段,成為幀。對于每一幀,可以通過某種規則(例如MFCC特征)提取信号中的特征,将其變成一個多元向量。向量中的每個次元都是這幀信号的一個特征。

圖2 語音識别編碼過程
解碼過程則是将編碼得到的向量變成文字的過程,需要經過兩個模型的處理,一個模型是聲學模型,一個模型是語言模型。聲學模型通過處理編碼得到的向量,将相鄰的幀組合起來變成音素,如中文拼音中的聲母和韻母,再組合起來變成單個單詞或漢字。語言模型用來調整聲學模型所得到的不合邏輯的字詞,使識别結果變得通順。兩者都需要大量資料用來訓練。
圖3 語言模型處理過程
已知一段音頻信号,處理成聲學特征向量Acoustic Feature Vector後表示為X=[x1,x2,x3,…]X=[x1,x2,x3,…],其中x_ixi表示一幀特征向量;可能的文本序清單示為W=[w1,w2,w3,…]W=[w1,w2,w3,…],其中wi表示一個詞,求W∗=argmaxwP(W∣X),這便是語音識别的基本出發點。并且由貝葉斯公式可知:
其中,P(X|W)P(X∣W)稱之為聲學模型(Acoustic Model, AM), P(W)P(W)稱之為語言模型(Language Model, LM),由于P(W)P(W)一般是一個不變量,可以省去不算。
目前許多研究将語音識别問題看做聲學模型與語音模型兩部分,分别求取P(X|W)P(X∣W)和P(W)P(W)。後來,基于深度學習和大資料的端對端(End-to-End)方法發展起來,直接計算P(W|X)P(W∣X),把聲學模型和語言模型融為了一體。
語音識别的問題可以看做是語音到文本的對應關系,語音識别問題大體可以歸結為文本基本組成機關的選擇上。機關不同,則模組化力度也随之改變。
圖4 語音識别的基本途徑
根據圖中文本基本組成機關從大到小分别是:
整句文本,如“Hello
World”,對應的語音模組化尺度為整條語音。
詞,如孤立詞“Good”、“World”、對應的語音模組化尺度大約為每個詞的發音範圍。
音素,如将“world”進一步表示為“/wɘrld//wɘrld/”,其中的每個音标作為基本機關,對應的語音模組化尺度則縮減為每個音素的發音範圍。
三音素,即考慮上下文的音素,如将音素“/d//d/”進一步表示為“{/l-d-sil, /u-d-l/,…}/l−d−sil,/u−d−l/,…”,對應的語音模組化尺度是每個三音素的發音範圍,長度與單音素差不多。
隐馬爾可夫模型狀态,即将每個三因素都用一個三狀态隐馬爾可夫模型表示,并用每個狀态作為模組化粒度,對應的語音模組化尺度将進一步縮短。
上面每種實作方法都對應着不同的模組化粒度,大體可以分為以隐馬爾可夫模型結構和端對端的結構。後面兩期博文将詳細介紹基于兩種結構的語音識别算法設計。
語音識别基本法 - 清華大學語音和語言技術中心[PDF]
點選關注,第一時間了解華為雲新鮮技術~