在前面的一篇文章《圖形資料庫Neo4J簡介》中,我們介紹了一種非常流行的圖形資料庫Neo4J的使用方法。而在本文中,我們将對另外一種類型的NoSQL資料庫——Cassandra進行簡單地介紹。
接觸Cassandra的原因與接觸Neo4J的原因相同:我們的産品需要能夠記錄一系列關系型資料庫所無法快速處理的大量資料。Cassandra,以及後面将要介紹的MongoDB,都是我們在技術選型過程中的一個備選方案。雖然說最後我們并沒有選擇Cassandra,但是在整個技術選型過程中所接觸到的一系列内部機制,思考方式等都是非常有趣的。而且在整個選型過程中也借鑒了CAM(Cloud Availability Manager)組在實際使用過程中所得到的一些經驗。是以我在這裡把自己的筆記總結成一篇文章,分享出來。
技術選型
技術選型常常是一個非常嚴謹的過程。由于一個項目通常是由數十位甚至上百位開發人員協同開發的,是以一個精準的技術選型常常能夠大幅提高整個項目的開發效率。在嘗試為某一類需求設計解決方案時,我們常常會有很多種可以選擇的技術。為了能夠精準地選擇一個适合于這些需求的技術,我們就需要考慮一系列有關學習曲線,開發,維護等衆多方面的因素。這些因素主要包括:
該技術所提供的功能是否能夠完整地解決問題。
該技術的擴充性如何。是否允許使用者添加自定義組成來滿足特殊的需求。
該技術是否有豐富完整的文檔,并且能夠以免費甚至付費的形式得到專業的支援。
該技術是否有很多人使用,尤其是一些大型企業在使用,并存在着成功的案例。
在該過程中,我們會逐漸篩選市面上所能找到的各種技術,并最終确定适合我們需求的那一種。
針對我們剛剛所提到的需求——記錄并處理系統自動生成的大量資料,我們在技術選型的初始階段會有很多種選擇:Key-Value資料庫,如Redis,Document-based資料庫,如MongoDB,Column-based資料庫,如Cassandra等。而且在實作特定功能時,我們常常可以通過以上所列的任何一種資料庫來搭建一個解決方案。可以說,如何在這三種資料庫之間選擇常常是NoSQL資料庫初學者所最為頭疼的問題。導緻這種現象的一個原因就是,Key-Value,Document-based以及Column-based實際上是對NoSQL資料庫的一種較為泛泛的分類。不同的資料庫提供商所提供的NoSQL資料庫常常具有略為不同的實作方式,并提供了不同的功能集合,進而會導緻這些資料庫類型之間的邊界并不是那麼清晰。
恰如其名所示,Key-Value資料庫會以鍵值對的方式來對資料進行存儲。其内部常常通過哈希表這種結構來記錄資料。在使用時,使用者隻需要通過Key來讀取或寫入相應的資料即可。是以其在對單條資料進行CRUD操作時速度非常快。而其缺陷也一樣明顯:我們隻能通過鍵來通路資料。除此之外,資料庫并不知道有關資料的其它資訊。是以如果我們需要根據特定模式對資料進行篩選,那麼Key-Value資料庫的運作效率将非常低下,這是因為此時Key-Value資料庫常常需要掃描所有存在于Key-Value資料庫中的資料。
是以在一個服務中,Key-Value資料庫常常用來作為服務端緩存使用,以記錄一系列經由較為耗時的複雜計算所得到的計算結果。最著名的就是Redis。當然,為Memcached添加了持久化功能的MemcacheDB也是一種Key-Value資料庫。
Document-based資料庫和Key-Value資料庫之間的不同主要在于,其所存儲的資料将不再是一些字元串,而是具有特定格式的文檔,如XML或JSON等。這些文檔可以記錄一系列鍵值對,數組,甚至是内嵌的文檔。如:
有些讀者可能會有疑問,我們同樣也可以通過Key-Value資料庫來存儲JSON或XML格式的資料,不是麼?答案就是Document-based資料庫常常會支援索引。我們剛剛提到過,Key-Value資料庫在執行資料的查找及篩選時效率非常差。而在索引的幫助下,Document-based資料庫則能夠很好地支援這些操作了。有些Document-based資料庫甚至允許執行像關系型資料庫那樣的JOIN操作。而且相較于關系型資料庫,Document-based資料庫也将Key-Value資料庫的靈活性得以保留。
而Column-based資料庫則與前面兩種資料庫非常不同。我們知道,一個關系型資料庫中所記錄的資料常常是按照行來組織的。每一行中包含了表示不同意義的多個列,并被順序地記錄在持久化檔案中。我們知道,關系型資料庫中的一個常見操作就是對具有特定特征的資料進行篩選及操作,而且該操作常常是通過WHERE子句來完成的:
在一個傳統的關系型資料庫中,該語句所操作的表可能如下所示:
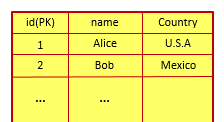
而在該表所對應的資料庫檔案中,每一行中的各個數值将被順序記錄,進而形成了如下圖所示的資料檔案:

是以在執行上面的SQL語句時,關系型資料庫并不能連續操作檔案中所記錄的資料:
這大大降低了關系型資料庫的性能:為了運作該SQL語句,關系型資料庫需要讀取每一行中的id域和name域。這将導緻關系型資料庫所要讀取的資料量顯著增加,也需要在通路所需資料時執行一系列偏移量計算。況且上面所舉的例子僅僅是一個最簡單的表。如果表中包含了幾十列,那麼資料讀取量将增大幾十倍,偏移量計算也會變得更為複雜。
那麼我們應該如何解決這個問題呢?答案就是将一列中的資料連續地存在一起:
而這就是Column-based資料庫的核心思想:按照列來在資料檔案中記錄資料,以獲得更好的請求及周遊效率。這裡有兩點需要注意:首先,Column-based資料庫并不表示會将所有的資料按列進行組織,也沒有那個必要。對某些需要執行請求的資料進行按列存儲即可。另外一點則是,Cassandra對Query的支援實際上是與其所使用的資料模型關聯在一起的。也就是說,對Query的支援很有限。我們馬上就會在下面的章節中對該限制進行介紹。
至此為止,您應該能夠根據各種資料庫所具有的特性來為您的需求選擇一個合适的NoSQL資料庫了。
Cassandra初體驗
OK,在簡單地介紹了Key-Value,Document-based以及Column-based三種不同類型的NoSQL資料庫之後,我們就要開始嘗試着使用Cassandra了。鑒于我個人在使用一系列NoSQL資料庫時常常遇到它們的版本更新缺乏API後向相容性這一情況,我在這裡直接使用了Datastax Java Driver的樣例。這樣讀者也能從該頁面中查閱針對最新版本用戶端的示例代碼。
一段最簡單的讀取一條記錄的Java代碼如下所示:
看起來很簡單,是麼?其實在用戶端的幫助下,操作Cassandra實際上并不是非常困難的一件事。反過來,如何為Cassandra所記錄的資料設計模型才是最需要讀者仔細考慮的。與大家所最為熟悉的關系型資料庫模組化方式不同,Cassandra中的資料模型設計需要是Join-less的。簡單地說,那就是由于這些資料分布在Cassandra的不同結點上,是以這些資料的Join操作并不能被高效地執行。
那麼我們應該如何為這些資料定義模型呢?首先我們要了解Cassandra所支援的基本資料模型。這些基本資料模型有:Column,Super Column,Column Family以及Keyspace。下面我們就對它們進行簡單地介紹。
Column是Cassandra所支援的最基礎的資料模型。該模型中可以包含一系列鍵值對:
Super Column則包含了一系列Column。在一個Super Column中的屬性可以是一個Column的集合:
這裡需要注意的是,Cassandra文檔已經不再建議過多的使用Super Column,而原因卻沒有直接說明。據說這和Super Column常常需要在資料通路時執行反序列化相關。一個最為常見的證據就是,網絡上常常會有一些開發人員在Super Column中添加了過多的資料,并進而導緻和這些Super Column相關的請求運作緩慢。當然這隻是猜測。隻不過既然官方文檔都已經開始對Super Column持謹慎意見,那麼我們也需要在日常使用過程中盡量避免使用Super Column。
而一個Column Family則是一系列Column的集合。在該集合中,每個Column都會有一個與之相關聯的鍵:
上面的Column Family示例中所包含的是一系列Column。除此之外,Column Family還可以包含一系列Super Column(請謹慎使用)。
最後,Keyspace則是一系列Column Family的集合。
發現了麼?上面沒有任何一種方法能夠通過一個Column(Super Column)引用另一個Column(Super Column),而隻能通過Super Column包含其它Column的方式來完成這種資訊的包含。這與我們在關系資料庫設計過程中通過外鍵與其它記錄相關聯的使用方法非常不同。還記得之前我們通過外鍵來建立資料關聯這一方法的名稱麼?對的,Normalization。該方法可以通過外鍵所訓示的關聯關系有效地消除在關系型資料庫中的備援資料。而在Cassandra中,我們要使用的方法就是Denormalization,也即是允許可以接受的一定程度的資料備援。也就是說,這些關聯的資料将直接記錄在目前資料類型之中。
在使用Cassandra時,哪些不該抽象為Cassandra資料模型,而哪些資料應該有一個獨立的抽象呢?這一切決定于我們的應用所常常執行的讀取及寫入請求。想想我們為什麼使用Cassandra,或者說Cassandra相較于關系型資料庫的優勢:快速地執行在海量資料上的讀取或寫入請求。如果我們僅僅根據所操作的事物抽象資料模型,而不去理會Cassandra在這些模型之上的執行效率,甚至導緻這些資料模型無法支援相應的業務邏輯,那麼我們對Cassandra的使用也就沒有實際的意義了。是以一個較為正确的做法就是:首先根據應用的需求來定義一個抽象概念,并開始針對該抽象概念以及應用的業務邏輯設計在該抽象概念上運作的請求。接下來,軟體開發人員就可以根據這些請求來決定如何為這些抽象概念設計模型了。
在抽象設計模型時,我們常常需要面對另外一個問題,那就是如何指定各Column Family所使用的各種鍵。在Cassandra相關的各類文檔中,我們常常會遇到以下一系列關鍵的名詞:Partition Key,Clustering Key,Primary Key以及Composite Key。那麼它們指的都是什麼呢?
Primary Key實際上是一個非常通用的概念。在Cassandra中,其表示用來從Cassandra中取得資料的一個或多個列:
在上面的示例中,我們指定了key域作為sample的PRIMARY KEY。而在需要的情況下,一個Primary Key也可以由多個列共同組成:
在上面的示例中,我們所建立的Primary Key就是一個由兩個列key_one和key_two組成的Composite Key。其中該Composite Key的第一個組成被稱為是Partition Key,而後面的各組成則被稱為是Clustering Key。Partition Key用來決定Cassandra會使用叢集中的哪個結點來記錄該資料,每個Partition Key對應着一個特定的Partition。而Clustering Key則用來在Partition内部排序。如果一個Primary Key隻包含一個域,那麼其将隻擁有Partition Key而沒有Clustering Key。
Partition Key和Clustering Key同樣也可以由多個列組成:
而在一個CQL語句中,WHERE等子句所标示的條件隻能使用在Primary Key中所使用的列。您需要根據您的資料分布決定到底哪些應該是Partition Key,哪些應該作為Clustering Key,以對其中的資料進行排序。
一個好的Partition Key設計常常會大幅提高程式的運作性能。首先,由于Partition Key用來控制哪個結點記錄資料,是以Partition Key可以決定是否資料能夠較為均勻地分布在Cassandra的各個結點上,以充分利用這些結點。同時在Partition Key的幫助下,您的讀請求應盡量使用較少數量的結點。這是因為在執行讀請求時,Cassandra需要協調處理從各個結點中所得到的資料集。是以在響應一個讀操作時,較少的結點能夠提供較高的性能。是以在模型設計中,如何根據所需要運作的各個請求指定模型的Partition Key是整個設計過程中的一個關鍵。一個取值均勻分布的,卻常常在請求中作為輸入條件的域,常常是一個可以考慮的Partition Key。
除此之外,我們也應該好好地考慮如何設定模型的Clustering Key。由于Clustering Key可以用來在Partition内部排序,是以其對于包含範圍篩選的各種請求的支援較好。
Cassandra内部機制
在本節中,我們将對Cassandra的一系列内部機制進行簡單地介紹。這些内部機制很多都是業界所常用的解決方案。是以在了解了Cassandra是如何使用它們的之後,您就可以非常容易地了解其它類庫對這些機制的使用,甚至在您自己的項目中借鑒及使用它們。
這些常見的内部機制有:Log-Structured Merge-Tree,Consistent Hash,Virtual Node等。
Log-Structured Merge-Tree
最有意思的一個資料結構莫過于Log-Structured Merge-Tree。Cassandra内部使用類似的結構來提高服務執行個體的運作效率。那它是如何工作的呢?
簡單地說,一個Log-Structured Merge-Tree主要由兩個樹形結構的資料組成:存在于記憶體中的C0,以及主要存在于磁盤中的C1:
在添加一個新的結點時,Log-Structured Merge-Tree會首先在日志檔案中添加一條有關該結點插入的記錄,然後再将該結點插入到樹C0中。添加到日志檔案中的記錄主要是基于資料恢複的考慮。畢竟C0樹處于記憶體中,非常容易受到系統當機等因素的影響。而在讀取資料時,Log-Structured Merge-Tree會首先嘗試從C0樹中查找資料,然後再在C1樹中查找。
在C0樹滿足一定條件之後,如其所占用的記憶體過大,那麼它所包含的資料将被遷移到C1中。在Log-Structured Merge-Tree這個資料結構中,該操作被稱為是rolling merge。其會把C0樹中的一系列記錄歸并到C1樹中。歸并的結果将會寫入到新的連續的磁盤空間。
幾乎是論文中的原圖
就單個樹來看,C1和我們所熟悉的B樹或者B+樹有點像,是不?
不知道您注意到沒有。上面的介紹突出了一個詞:連續的。這是因為C1樹中同一層次的各個結點在磁盤中是連續記錄的。這樣磁盤就可以通過連續讀取來避免在磁盤上的過多尋道,進而大大地提高了運作效率。
Memtable和SSTable
好,剛剛我們已經提到了Cassandra内部使用和Log-Structured Merge-Tree類似的資料結構。那麼在本節中,我們就将對Cassandra的一些主要資料結構及操作流程進行介紹。可以說,如果您大緻了解了上一節對Log-Structured Merge-Tree的講解,那麼了解這些資料結構也将是非常容易的事情。
在Cassandra中有三個非常重要的資料結構:記錄在記憶體中的Memtable,以及儲存在磁盤中的Commit Log和SSTable。Memtable在記憶體中記錄着最近所做的修改,而SSTable則在磁盤上記錄着Cassandra所承載的絕大部分資料。在SSTable内部記錄着一系列根據鍵排列的一系列鍵值對。通常情況下,一個Cassandra表會對應着一個Memtable和多個SSTable。除此之外,為了提高對資料進行搜尋和通路的速度,Cassandra還允許軟體開發人員在特定的列上建立索引。
鑒于資料可能存儲于Memtable,也可能已經被持久化到SSTable中,是以Cassandra在讀取資料時需要合并從Memtable和SSTable所取得的資料。同時為了提高運作速度,減少不必要的對SSTable的通路,Cassandra提供了一種被稱為是Bloom Filter的組成:每個SSTable都有一個Bloom Filter,以用來判斷與其關聯的SSTable是否包含目前查詢所請求的一條或多條資料。如果是,Cassandra将嘗試從該SSTable中取出資料;如果不是,Cassandra則會忽略該SSTable,以減少不必要的磁盤通路。
在經由Bloom Filter判斷出與其關聯的SSTable包含了請求所需要的資料之後,Cassandra就會開始嘗試從該SSTable中取出資料了。首先,Cassandra會檢查Partition Key Cache是否緩存了所要求資料的索引項Index Entry。如果存在,那麼Cassandra會直接從Compression Offset Map中查詢該資料所在的位址,并從該位址取回所需要的資料;如果Partition Key Cache并沒有緩存該Index Entry,那麼Cassandra首先會從Partition Summary中找到Index Entry所在的大緻位置,并進而從該位置開始搜尋Partition Index,以找到該資料的Index Entry。在找到Index Entry之後,Cassandra就可以從Compression Offset Map找到相應的條目,并根據條目中所記錄的資料的位移取得所需要的資料:
較文檔中原圖略作調整
發現了麼?實際上SSTable中所記錄的資料仍然是順序記錄的各個域,但是不同的是,它的查找首先經由了Partition Key Cache以及Compression Offset Map等一系列組成。這些組成僅僅包含了一系列對應關系,也就是相當于連續地記錄了請求所需要的資料,進而提高了資料搜尋的運作速度,不是麼?
Cassandra的寫入流程也與Log-Structured Merge-Tree的寫入流程非常類似:Log-Structured Merge-Tree中的日志對應着Commit Log,C0樹對應着Memtable,而C1樹則對應着SSTable的集合。在寫入時,Cassandra會首先将資料寫入到Memtable中,同時在Commit Log的末尾添加該寫入所對應的記錄。這樣在機器斷電等異常情況下,Cassandra仍能通過Commit Log來恢複Memtable中的資料。
在持續地寫入資料後,Memtable的大小将逐漸增長。在其大小到達某個門檻值時,Cassandra的資料遷移流程就将被觸發。該流程一方面會将Memtable中的資料添加到相應的SSTable的末尾,另一方面則會将Commit Log中的寫入記錄移除。
這也就會造成一個容易讓讀者困惑的問題:如果是将新的資料寫入到SSTable的末尾,那麼資料遷移的過程該如何執行對資料的更新?答案就是:在需要對資料進行更新時,Cassandra會在SSTable的末尾添加一條具有目前時間戳的記錄,以使得其能夠标明自身為最新的記錄。而原有的在SSTable中的記錄随即宣告失效。
這會導緻一個問題,那就是對資料的大量更新會導緻SSTable所占用的磁盤空間迅速增長,而且其中所記錄的資料很多都已經是過期資料。是以在一段時間之後,磁盤的空間使用率會大幅下降。此時我們就需要通過壓縮SSTable的方式釋放這些過期資料所占用的空間:
現在有一個問題,那就是我們可以根據重複資料的時間戳來判斷哪條是最新的資料,但是我們應該如何處理資料的删除呢?在Cassandra中,對資料的删除是通過一個被稱為tombstone的組成來完成的。如果一條資料被添加了一個tombstone,那麼其在下次壓縮時就被認為是一條已經被删除的資料,進而不會添加到壓縮後的SSTable中。
在壓縮過程中,原有的SSTable和新的SSTable同時存在于磁盤上。這些原有的SSTable用來完成對資料讀取的支援。一旦新的SSTable建立完畢,那麼老的SSTable就将被删除。
在這裡我們要提幾點在日常使用Cassandra的過程中需要注意的問題。首先是,由于通過Commit Log來重建Memtable是一個較為耗時的過程,是以我們在需要重建Memtable的一系列操作前需要嘗試手動觸發歸并邏輯,以将該結點上Memtable中的資料持久化到SSTable中。最常見的一種需要重建Memtable的操作就是重新啟動Cassandra所在的結點。
另一個需要注意的地方是,不要過度地使用索引。雖然說索引可以大幅地增加資料的讀取速度,但是我們同樣需要在資料寫入時對其進行維護,造成一定的性能損耗。在這點上,Cassandra和傳統的關系型資料庫沒有太大差別。
Cassandra叢集
當然,使用單一的資料庫執行個體來運作Cassandra并不是一個好的選擇。單一的伺服器可能導緻服務叢集産生單點失效的問題,也無法充分利用Cassandra的橫向擴充能力。是以從本節開始,我們就将對Cassandra叢集以及叢集中所使用的各種機制進行簡單地講解。
在一個Cassandra叢集中常常包含着以下一系列組成:結點(Node),資料中心(Data Center)以及叢集(Cluster)。結點是Cassandra叢集中用來存儲資料的最基礎結構;資料中心則是處于同一地理區域的一系列結點的集合;而叢集則常常由多個處于不同區域的資料中心所組成:
上圖所展示的Cassandra叢集由三個資料中心組成。這三個資料中心中的兩個處于同一區域内,而另一個資料中心則處于另一個區域中。可以說,兩個資料中心處于同一區域的情況并不多見,但是Cassandra的官方文檔也沒有否定這種叢集搭建方式。每個資料中心則包含了一系列結點,以用來存儲Cassandra叢集所要承載的資料。
有了叢集,我們就需要使用一系列機制來完成叢集之間的互相協作,并考慮叢集所需要的一系列非功能性需求了:結點的狀态維護,資料分發,擴充性(Scalability),高可用性,災難恢複等。
對結點的狀态進行探測是高可用性的第一步,也是在結點間分發資料的基礎。Cassandra使用了一種被稱為是Gossip的點對點通訊方案,以在Cassandra叢集中的各個結點之間共享及傳遞各個結點的狀态。隻有這樣,Cassandra才能知道到底哪些結點可以有效地儲存資料,進而将對資料的操作分發給各結點。
在儲存資料的過程中,Cassandra會使用一個被稱為是Partitioner的組成來決定資料到底要分發到哪些結點上。而另一個和資料存儲相關的組成就是Snitch。其會提供根據叢集中所有結點的性能來決定如何對資料進行讀寫。
這些組成内部也使用了一系列業界所常用的方法。例如Cassandra内部通過VNode來處理各硬體的性能不同,進而在實體硬體層次上形成一種類似《企業級負載平衡簡介》一文所中提到過的Weighted Round Robin的解決方案。再比如其内部使用了Consistent Hash,我們也在《Memcached簡介》一文中給出過介紹。
好了,簡介完成。在下面幾節中,我們就将對Cassandra所使用的這些機制進行介紹。
Gossip
首先就是Gossip。其是用來在Cassandra叢集中的各個結點之間傳輸結點狀态的協定。它每秒都将運作一次,并将目前Cassandra結點的狀态以及其所知的其它結點的狀态與至多三個其它結點交換。通過這種方法,Cassandra的有效結點能很快地了解目前叢集中其它結點的狀态。同時這些狀态資訊還包含一個時間戳,以允許Gossip判斷到底哪個狀态是更新的狀态。
除了在叢集中的各個結點之間交換各結點的狀态之外,Gossip還需要能夠應對對叢集進行操作的一系列動作。這些操作包括結點的添加,移除,重新加入等。為了能夠更好地處理這些情況,Gossip提出了一個叫做Seed Node的概念。其用來為各個新加入的結點提供一個啟動Gossip交換的入口。在加入到Cassandra叢集之後,新結點就可以首先嘗試着跟其所記錄的一系列Seed Node交換狀态。這一方面可以得到Cassandra叢集中其它結點的資訊,進而允許其與這些結點進行通訊,又可以将自己加入的資訊通過這些Seed Node傳遞出去。由于一個結點所得到的結點狀态資訊常常被記錄在磁盤等持久化組成中,是以在重新啟動之後,其仍然可以通過這些持久化後的結點資訊進行通訊,以重新加入Gossip交換。而在一個結點失效的情況下,其它結點将會定時地向該結點發送探測消息,以嘗試與其恢複連接配接。但是這會為我們永久地移除一個結點帶來麻煩:其它Cassandra結點總覺得該結點将在某一時刻重新加入叢集,是以一直向該結點發送探測資訊。此時我們就需要使用Cassandra所提供的結點工具了。
那麼Gossip是如何判斷是否某個結點失效了呢?如果在交換過程中,參與交換的另一方很久不回答,那麼目前結點就會将目标結點标示為失效,并進而通過Gossip協定将該狀态傳遞出去。由于Cassandra叢集的拓撲結構可能非常複雜,如跨區域等,是以其用來判斷一個結點是否失效的标準并不是在多長時間之内沒有響應就判定為失效。畢竟這會導緻很大的問題:兩個在同一個Lab中的結點進行狀态交換會非常快,而跨區域的交換則會比較慢。如果我們設定的時間較短,那麼跨區域的狀态交換常常會被誤報為失效;如果我們所設定的時間較長,那麼Gossip對結點失效的探測靈敏度将降低。為了避免這種情況,Gossip使用的是一種根據以往結點間交換曆史等衆多因素綜合起來的決策邏輯。這樣對于兩個距離較遠的結點,其将擁有較大的時間窗,進而不會産生誤報。而對于兩個距離較近的結點,Gossip将使用較小的時間窗,進而提高探測的靈敏度。
Consistent Hash
接下來我們要講的是Consistent Hash。在通常的雜湊演算法中常常包含着桶這個概念。每次哈希計算都是在決定特定資料需要存儲在哪個桶中。而如果桶的數量發生了變化,那麼之前的哈希計算結果都将失效。而Consistent Hash則很好地解決了該問題。
那Consistent Hash是如何工作的呢?首先請考慮一個圓,在該圓上分布了多個點,以表示整數0到1023。這些整數平均分布在整個圓上:
在上圖中,我們突出地顯示了将圓六等分的六個藍點,表示用來記錄資料的六個結點。這六個結點将各自負責一個範圍。例如512這個藍點所對應的結點就将記錄從哈希值為512到681這個區間的資料。在Cassandra以及其它的一些領域中,這個圓被稱為是一個Ring。接下來我們就對目前需要存儲的資料執行哈希計算,并得到該資料所對應的哈希值。例如一段資料的哈希值為900,那麼它就位于853和1024之間:
是以該資料将被藍點853所對應的結點記錄。這樣一旦其它結點失效,該資料所在的結點也不會發生變化:
那每段資料的哈希值到底是如何計算出來的呢?答案是Partitioner。其輸入為資料的Partition Key。而其計算結果在Ring上的位置就決定了到底是由哪些結點來完成對資料的儲存。
Virtual Node
上面我們介紹了Consistent Hash的運作原理。但是這裡還有一個問題,那就是失效的那個結點上的資料該怎麼辦?我們就無法通路了麼?這取決于我們對Cassandra叢集資料複制方面的設定。通常情況下,我們都會啟用該功能,進而使得多個結點同時記錄一份資料的拷貝。那麼在其中一個結點失效的情況下,其它結點仍然可以用來讀取該資料。
這裡要處理的一個情況就是,各個實體結點所具有的容量并不相同。簡單地說,如果一個結點所能提供的服務能力遠小于其它結點,那麼為其配置設定相同的負載将使得它不堪重負。為了處理這種情況,Cassandra提供了一種被稱為VNode的解決方案。在該解決方案中,每個實體結點将根據其實際容量被劃分為一系列具有相同容量的VNode。每個VNode則用來負責Ring上的一段資料。例如對于剛剛所展示的具有六個結點的Ring,各個VNode和實體機之間的關系則可能如下所示:
在使用VNode時,我們常常需要注意的一點就是Replication Factor的設定。從其所表示的意義來講,Cassandra中的Replication Factor和其它常見資料庫中所使用的Replication Factor沒有什麼不同:其所具有的數值用來表示記錄在Cassandra中的資料有多少份拷貝。例如在其被設定為1的情況下,Cassandra将隻會儲存一份資料。如果其被設定為2,那麼Cassandra将多儲存一份這些資料的拷貝。
在決定Cassandra叢集所需要使用的Replication Factor時,我們需要考慮以下一系列因素:
實體機的數量。試想一下,如果我們将Replication Factor設定為超過實體機的數量,那麼必然會有實體機儲存了同一份資料的兩部分拷貝。這實際上沒有太大的作用:一旦該實體機出現異常,那就會一次損失多份資料。是以就高可用性這一點來說,Replication Factor的數值超過實體機的數量時,多出的這些資料拷貝意義并不大。
實體機的異構性。實體機的異構性常常也會影響您所設Replication Factor的效果。舉一個極端的例子。如果說我們有一個Cassandra叢集而且其由五台實體機組成。其中一台實體機的容量是其它實體機的4倍。那麼将Replication Factor設定為3時将會出現具有較大容量的實體機上存儲了同樣的資料這種問題。其并不比設定為2好多少。
是以在決定一個Cassandra叢集的Replication Factor時,我們要仔細地根據叢集中實體機的數量和容量設定一個合适的數值。否則其隻會導緻更多的無用的資料拷貝。
注:這篇文章寫于15年8月。鑒于NoSQL資料庫發展非常快,而且常常具有一系列影響後向相容性的更改(如Spring Data Neo4J已經不支援@Fetch)。是以如果您發現有什麼描述已經發生了改變,請幫留下評論,以便其它讀者參考。在此感激不盡
轉載請注明原文位址并标明轉載:http://www.cnblogs.com/loveis715/p/5299495.html
商業轉載請事先與我聯系:[email protected]
公衆号一定幫忙别标成原創,因為協調起來太麻煩了。。。