本文來自AI新媒體量子位(QbitAI)
去年開始,工作中需要做許多有關 AI 科普的事情。很長時間裡一直在想,該如何給一個沒有 CS 背景的人講解什麼是深度學習,以便讓一個非技術的投資人、企業管理者、行業專家、媒體記者乃至普通大衆明白深度學習為什麼會特别有效,了解 AI 是如何幫助人們解決具體問題的。中間經由 Quora 一篇簡短回答的啟發,大緻形成了用水流脈絡來比拟神經網絡的想法。曾經在面向銀行界、教育界、投資界人士的演講中,嘗試過基于這個比喻的講解方法,效果很不錯。慢慢就形成了這樣一篇文章,最近也被收進了李開複和我合著的科普書《人工智能》中。
【注】特别需要說明的是,本文對深度學習的概念闡述刻意避免了數學公式和數學論證,這種用水管網絡來普及深度學習的方法隻适合一般公衆。對于懂數學、懂計算機科學的專業人士來說,這樣的描述相當不完備也不精确。流量調節閥的比喻與深度神經網絡中每個神經元相關的權重調整,在數學上并非完全等價。對水管網絡的整體描述也有意忽略了深度學習算法中的代價函數、梯度下降、反向傳播等重要概念。專業人士要學習深度學習,還是要從專業教程看起。
從根本上說,深度學習和所有機器學習方法一樣,是一種用數學模型對真實世界中的特定問題進行模組化,以解決該領域内相似問題的過程。
首先,深度學習是一種機器學習。既然名為“學習”,那自然與我們人類的學習過程有某種程度的相似。回想一下,一個人類小朋友是如何學習的?
比如,很多小朋友都用識字卡片來認字。從古時候人們用的“上大人、孔乙己”之類的描紅本,到今天在手機、平闆電腦上教小朋友認字的識字卡片APP,最基本的思路就是按照從簡單到複雜的順序,讓小朋友反複看每個漢字的各種寫法(大一點的小朋友甚至要學着認識不同的書法字型),看得多了,自然就記住了。下次再見到同一個字,就很容易能認出來。
這個有趣的識字過程看似簡單,實則奧妙無窮。認字時,一定是小朋友的大腦在接受許多遍相似圖像的刺激後,為每個漢字總結出了某種規律性的東西,下次大腦再看到符合這種規律的圖案,就知道是什麼字了。
其實,要教計算機認字,差不多也是同樣的道理。計算機也要先把每一個字的圖案反複看很多很多遍,然後,在計算機的大腦(處理器加上存儲器)裡,總結出一個規律來,以後計算機再看到類似的圖案,隻要符合之前總結的規律,計算機就能知道這圖案到底是什麼字。
用專業的術語來說,計算機用來學習的、反複看的圖檔叫“訓練資料集”;“訓練資料集”中,一類資料差別于另一類資料的不同方面的屬性或特質,叫做“特征”;計算機在“大腦”中總結規律的過程,叫“模組化”;計算機在“大腦”中總結出的規律,就是我們常說的“模型”;而計算機通過反複看圖,總結出規律,然後學會認字的過程,就叫“機器學習”。
到底計算機是怎麼學習的?計算機總結出的規律又是什麼樣的呢?這取決于我們使用什麼樣的機器學習算法。
有一種算法非常簡單,模仿的是小朋友學識字的思路。家長和老師們可能都有這樣的經驗:小朋友開始學識字,比如先教小朋友分辨“一”、“二”、“三”時,我們會告訴小朋友說,一筆寫成的字是“一”,兩筆寫成的字是“二”,三筆寫成的字是“三”。這個規律好記又好用。但是,開始學新字時,這個規律就未必奏效了。比如,“口”也是三筆,可它卻不是“三”。我們通常會告訴小朋友,圍成個方框兒的是“口”,排成橫排的是“三”。這規律又豐富了一層,但仍然禁不住識字數量的增長。很快,小朋友就發現,“田”也是個方框兒,可它不是“口”。我們這時會告訴小朋友,方框裡有個“十”的是“田”。再往後,我們多半就要告訴小朋友,“田”上面出頭是“由”,下面出頭是“甲”,上下都出頭是“申”。很多小朋友就是在這樣一步一步豐富起來的特征規律的指引下,慢慢學會自己總結規律,自己記住新的漢字,并進而學會幾千個漢字的。
有一種名叫決策樹的機器學習方法,就和上面根據特征規律來識字的過程非常相似。當計算機隻需要認識“一”、“二”、“三”這三個字時,計算機隻要數一下要識别的漢字的筆畫數量,就可以分辨出來了。當我們為待識别漢字集(訓練資料集)增加“口”和“田”時,計算機之前的判定方法失敗,就必須引入其他判定條件。由此一步步推進,計算機就能認識越來越多的字。
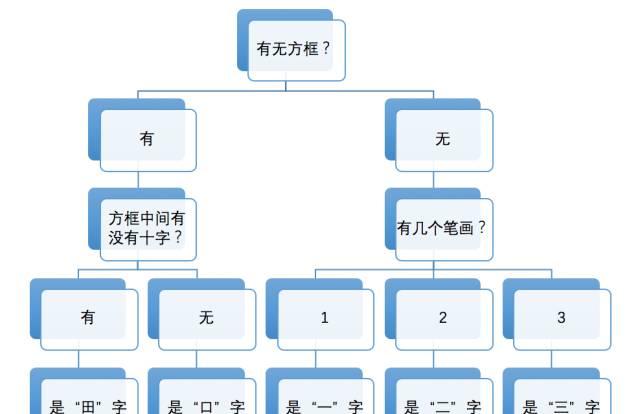

附圖顯示了計算機學習“由”、“甲”、“申”這三個新漢字前後,計算機内部的決策樹的不同。這說明,當我們給計算機“看”了三個新漢字及其特征後,計算機就像小朋友那樣,總結并記住了新的規律,“認識”了更多的漢字。這個過程,就是一種最基本的機器學習了。
當然,這種基于決策樹的學習方法太簡單了,很難擴充,也很難适應現實世界的不同情況。于是,科學家和工程師們陸續發明出了許許多多不同的機器學習方法。
例如,我們可以把漢字“由”、“甲”、“申”的特征,包括有沒有出頭,筆畫間的位置關系等,映射到某個特定空間裡的一個點(我知道,這裡又出現數學術語了。不過這不重要,是否了解“映射”的真實含義,完全不影響後續閱讀)。也就是說,訓練資料集中,這三個字的大量不同寫法,在計算機看來就變成了空間中的一大堆點。隻要我們對每個字的特征提取得足夠好,空間中的一大堆點就會大緻分布在三個不同的範圍裡。
這時,讓計算機觀察這些點的規律,看能不能用一種簡明的分割方法(比如在空間中畫直線),把空間分割成幾個互相獨立的區域,盡量使得訓練資料集中每個字對應的點都位于同一個區域内。如果這種分割是可行的,就說明計算機“學”到了這些字在空間中的分布規律,為這些字建立了模型。
接下來,看見一個新的漢字圖像時,計算機就簡單把圖像換算成空間裡的一個點,然後判斷這個點落在了哪個字的區域裡,這下,不就能知道這個圖像是什麼字了嗎?
很多人可能已經看出來了,使用畫直線的方法來分割一個平面空間(如附圖所示),很難适應幾千個漢字以及總計至少數萬種不同的寫法。如果想把每個漢字的不同變形都對應為空間中的點,那就極難找到一種數學上比較直截了當的方法,來将每個漢字對應的點都分割包圍在不同區域裡。
很多年裡,數學家和計算機科學家就是被類似的問題所困擾。人們不斷改進機器學習方法。比如,用複雜的高階函數來畫出變化多端的曲線,以便将空間裡互相交錯的點分開來,或者,幹脆想辦法把二維空間變成三維空間、四維空間甚至幾百維、幾千維、幾萬維的高維空間。在深度學習實用化之前,人們發明了許多種傳統的、非深度的機器學習方法。這些方法雖然在特定領域取得了一定成就,但這個世界實在是複雜多樣、變化萬千,無論人們為計算機選擇了多麼優雅的模組化方法,都很難真正模拟世界萬物的特征規律。這就像一個試圖用有限幾種顔色畫出世界真實面貌的畫家,即便畫藝再高明,他也很難做到“寫實”二字。
那麼,如何大幅擴充計算機在描述世界規律時的基本手段呢?有沒有可能為計算機設計一種靈活度極高的表達方式,然後讓計算機在大規模的學習過程裡不斷嘗試和尋找,自己去總結規律,直到最終找到符合真實世界特征的一種表示方法呢?
現在,我們終于要談到深度學習了!
深度學習就是這樣一種在表達能力上靈活多變,同時又允許計算機不斷嘗試,直到最終逼近目标的一種機器學習方法。從數學本質上說,深度學習與前面談到的傳統機器學習方法并沒有實質性差别,都是希望在高維空間中,根據對象特征,将不同類别的對象區分開來。但深度學習的表達能力,與傳統機器學習相比,卻有着天壤之别。
簡單地說,深度學習就是把計算機要學習的東西看成一大堆資料,把這些資料丢進一個複雜的、包含多個層級的資料處理網絡(深度神經網絡),然後檢查經過這個網絡處理得到的結果資料是不是符合要求——如果符合,就保留這個網絡作為目标模型,如果不符合,就一次次地、锲而不舍地調整網絡的參數設定,直到輸出滿足要求為止。
這麼說還是太抽象,太難懂。我們換一種更直覺的講法。
假設深度學習要處理的資料是資訊的“水流”,而處理資料的深度學習網絡是一個由管道和閥門組成的巨大的水管網絡。網絡的入口是若幹管道開口,網絡的出口也是若幹管道開口。這個水管網絡有許多層,每一層有許多個可以控制水流流向與流量的調節閥。根據不同任務的需要,水管網絡的層數、每層的調節閥數量可以有不同的變化組合。對複雜任務來說,調節閥的總數可以成千上萬甚至更多。水管網絡中,每一層的每個調節閥都通過水管與下一層的所有調節閥連接配接起來,組成一個從前到後,逐層完全連通的水流系統(這裡說的是一種比較基本的情況,不同的深度學習模型,在水管的安裝和連接配接方式上,是有差别的)。
那麼,計算機該如何使用這個龐大的水管網絡,來學習識字呢?
比如,當計算機看到一張寫有“田”字的圖檔時,就簡單将組成這張圖檔的所有數字(在計算機裡,圖檔的每個顔色點都是用“0”和“1”組成的數字來表示的)全都變成資訊的水流,從入口灌進水管網絡。
我們預先在水管網絡的每個出口都插一塊字牌,對應于每一個我們想讓計算機認識的漢字。這時,因為輸入的是“田”這個漢字,等水流流過整個水管網絡,計算機就會跑到管道出口位置去看一看,是不是标記有“田”字的管道出口流出來的水流最多。如果是這樣,就說明這個管道網絡符合要求。如果不是這樣,我們就給計算機下達指令:調節水管網絡裡的每一個流量調節閥,讓“田”字出口“流出”的數字水流最多。
這下,計算機可要忙一陣子了,要調節那麼多閥門呢!好在計算機計算速度快,暴力計算外加算法優化(其實,主要是精妙的數學方法了,不過我們這裡不講數學公式,大家隻要想象計算機拼命計算的樣子就可以了),總是可以很快給出一個解決方案,調好所有閥門,讓出口處的流量符合要求。
下一步,學習“申”字時,我們就用類似的方法,把每一張寫有“申”字的圖檔變成一大堆數字組成的水流,灌進水管網絡,看一看,是不是寫有“申”字的那個管道出口流出來的水最多,如果不是,我們還得再次調整所有的調節閥。這一次,要既保證剛才學過的“田”字不受影響,也要保證新的“申”字可以被正确處理。
如此反複進行,直到所有漢字對應的水流都可以按照期望的方式流過整個水管網絡。這時,我們就說,這個水管網絡已經是一個訓練好的深度學習模型了。
例如,附圖顯示了“田”字的資訊水流被灌入水管網絡的過程。為了讓水流更多地從标記有“田”字的出口流出,計算機需要用特定方式近乎瘋狂地調節所有流量調節閥,不斷實驗、摸索,直到水流符合要求為止。
當大量識字卡片被這個管道網絡處理,所有閥門都調節到位後,整套水管網絡就可以用來識别漢字了。這時,我們可以把調節好的所有閥門都“焊死”,靜候新的水流到來。
與訓練時做的事情類似,未知的圖檔會被計算機轉變成資料的水流,灌入訓練好的水管網絡。這時,計算機隻要觀察一下,哪個出口流出來的水流最多,這張圖檔寫的就是哪個字。
簡單嗎?神奇嗎?難道深度學習竟然就是這樣的一個靠瘋狂調節閥門來“湊”出最佳模型的學習方法?整個水管網絡内部,每個閥門為什麼要如此調節,為什麼要調節到如此程度,難道完全由最終每個出口的水流量來決定?這裡面,真的沒有什麼深奧的道理可言?
深度學習大緻就是這麼一個用人類的數學知識與計算機算法建構起整體架構,再結合盡可能多的訓練資料,以及計算機的大規模運算能力去調節内部參數,盡可能逼近問題目标的半理論、半經驗的模組化方式。
指導深度學習的基本是一種實用主義的思想。
不是要了解更複雜的世界規律嗎?那我們就不斷增加整個水管網絡裡可調節的閥門的個數(增加層數或增加每層的調節閥數量)。不是有大量訓練資料和大規模計算能力嗎?那我們就讓許多CPU和許多GPU(圖形處理器,俗稱顯示卡晶片,原本是專用于作圖和玩遊戲的,碰巧也特别适合深度學習計算)組成龐大計算陣列,讓計算機在拼命調節無數個閥門的過程中,學到訓練資料中的隐藏的規律。也許正是因為這種實用主義的思想,深度學習的感覺能力(模組化能力)遠強于傳統的機器學習方法。
實用主義意味着不求甚解。即便一個深度學習模型已經被訓練得非常“聰明”,可以非常好地解決問題,但很多情況下,連設計整個水管網絡的人也未必能說清楚,為什麼管道中每一個閥門要調節成這個樣子。也就是說,人們通常隻知道深度學習模型是否工作,卻很難說出,模型中某個參數的取值與最終模型的感覺能力之間,到底有怎樣的因果關系。
這真是一件特别有意思的事。有史以來最有效的機器學習方法,在許多人看來,竟然是一個隻可意會、不可言傳的“黑盒子”。
由此引發的一個哲學思辨是,如果人們隻知道計算機學會了做什麼,卻說不清計算機在學習過程中掌握的是一種什麼樣的規律,那這種學習本身會不會失控?
比如,很多人由此擔心,按照這樣的路子發展下去,計算機會不會悄悄學到什麼我們不希望它學會的知識?另外,從原理上說,如果無限增加深度學習模型的層數,那計算機的模組化能力是不是就可以與真實世界的終極複雜度有一比呢?如果這個答案是肯定的,那隻要有足夠的資料,計算機就能學會宇宙中所有可能的知識——接下來會發生什麼?大家是不是對計算機的智慧超越人類有了些許的憂慮?還好,關于深度學習到底是否有能力表達宇宙級别的複雜知識,專家們尚未有一緻看法。人類至少在可見的未來還是相對安全的。
補充一點:目前,已經出現了一些可視化的工具,能夠幫助我們“看見”深度學習在進行大規模運算時的“樣子”。比如說,谷歌著名的深度學習架構TensorFlow就提供了一個網頁版的小工具(Tensorflow — Neural Network Playground),用人們易于了解的圖示,畫出了正在進行深度學習運算的整個網絡的實時特征。
附圖顯示了一個包含4層中間層級(隐含層)的深度神經網絡針對某訓練資料集進行學習時的“樣子”。圖中,我們可以直覺地看到,網絡的每個層級與下一個層級之間,資料“水流”的方向與大小。我們還可以随時在這個網頁上改變深度學習架構的基本設定,從不同角度觀察深度學習算法。這對我們學習和了解深度學習大有幫助。
本文作者:王詠剛
原文釋出時間:2017-05-04