本文來自AI新媒體量子位(QbitAI)
最近,斯坦福大學的李飛飛與與她的學生Ranjay Krishna、Kenji Hata、Frederic Ren,以及同僚Juan Carlos Niebles向ICCV 2017送出論文,提出了一個新模型,可以識别視訊中的事件,同時用自然語言描述出來。
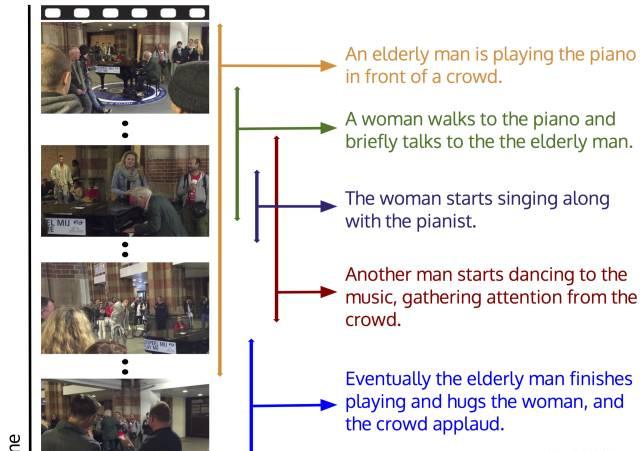
△ 新模型的原理及應用案例
大多數視訊都包含着大量事件。舉個例子吧,比如在一段鋼琴演奏的視訊中,可能不僅僅包含鋼琴演奏者,還可能包含着一群跳舞的人,或者一群鼓掌的觀衆,這些事件很可能是同時發生的。當一段視訊中包含檢測内容和描述内容時,我們稱它為“字幕密集型事件”。
李飛飛團隊的模型,可以利用過去和未來的上下文内容資訊,來識别視訊中這些事件之間的關系,并把所有事件描述出來。

上面這張流程圖展現了新模型的運作原理。
同時,他們還釋出了ActivityNet字幕資料集。這個資料集中包含了長達849小時的2萬個視訊,以及10萬條帶有開始和結束時間的描述資訊,可以用來對字幕密集型事件進行基準測試。
資料集下載下傳:
本文作者:安妮
原文釋出時間:2017-05-08