mysql性能優化
目錄
一、優化概述
二、查詢與索引優化分析
1性能瓶頸定位
Show指令
慢查詢日志
explain分析查詢
profiling分析查詢
2索引及查詢優化
三、配置優化
1)
max_connections
2)
back_log
3)
interactive_timeout
4)
key_buffer_size
5)
query_cache_size
6)
record_buffer_size
7)
read_rnd_buffer_size
8)
sort_buffer_size
9)
join_buffer_size
10)
table_cache
11)
max_heap_table_size
12)
tmp_table_size
13)
thread_cache_size
14)
thread_concurrency
15)
wait_timeout
一、 優化概述
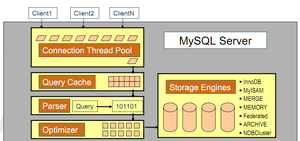
MySQL資料庫是常見的兩個瓶頸是CPU和I/O的瓶頸,CPU在飽和的時候一般發生在資料裝入記憶體或從磁盤上讀取資料時候。磁盤I/O瓶頸發生在裝入資料遠大于記憶體容量的時候,如果應用分布在網絡上,那麼查詢量相當大的時候那麼平瓶頸就會出現在網絡上,我們可以用mpstat,
iostat, sar和vmstat來檢視系統的性能狀态。
除了伺服器硬體的性能瓶頸,對于MySQL系統本身,我們可以使用工具來優化資料庫的性能,通常有三種:使用索引,使用EXPLAIN分析查詢以及調整MySQL的内部配置。
在優化MySQL時,通常需要對資料庫進行分析,常見的分析手段有慢查詢日志,EXPLAIN 分析查詢,profiling分析以及show指令查詢系統狀态及系統變量,通過定位分析性能的瓶頸,才能更好的優化資料庫系統的性能。
1
性能瓶頸定位Show指令
我們可以通過show指令檢視MySQL狀态及變量,找到系統的瓶頸:
Mysql>
show status ——顯示狀态資訊(擴充show status like ‘XXX’)
show variables ——顯示系統變量(擴充show variables like ‘XXX’)
show innodb status ——顯示InnoDB存儲引擎的狀态
show processlist ——檢視目前SQL執行,包括執行狀态、是否鎖表等
Shell>
mysqladmin variables -u username -p password——顯示系統變量
mysqladmin extended-status -u username -p password——顯示狀态資訊
檢視狀态變量及幫助:
mysqld –verbose –help [|more #逐行顯示]
比較全的Show指令的使用可參考:
http://blog.phpbean.com/a.cn/18/
慢查詢日志開啟:
在配置檔案my.cnf或my.ini中在[mysqld]一行下面加入兩個配置參數
log-slow-queries=/data/mysqldata/slow-query.log
long_query_time=2
注:log-slow-queries參數為慢查詢日志存放的位置,一般這個目錄要有mysql的運作帳号的可寫權限,一般都将這個目錄設定為mysql的資料存放目錄;
long_query_time=2中的2表示查詢超過兩秒才記錄;
在my.cnf或者my.ini中添加log-queries-not-using-indexes參數,表示記錄下沒有使用索引的查詢。
long_query_time=10
log-queries-not-using-indexes
慢查詢日志開啟方法二:
我們可以通過指令行設定變量來即時啟動慢日志查詢。由下圖可知慢日志沒有打開,slow_launch_time=# 表示如果建立線程花費了比這個值更長的時間,slow_launch_threads
計數器将增加

MySQL後可以查詢long_query_time
的值 。
慢查詢分析mysqldumpslow
我們可以通過打開log檔案檢視得知哪些SQL執行效率低下
[root@localhost mysql]# more
slow-query.log
# Time: 081026 19:46:34
# User@Host: root[root] @ localhost []
# Query_time: 11 Lock_time: 0 Rows_sent: 1 Rows_examined: 6552961
select count(*) from t_user;
從日志中,可以發現查詢時間超過5
秒的SQL,而小于5秒的沒有出現在此日志中。
如果慢查詢日志中記錄内容很多,可以使用mysqldumpslow工具(MySQL用戶端安裝自帶)來對慢查詢日志進行分類彙總。mysqldumpslow對日志檔案進行了分類彙總,顯示彙總後摘要結果。
進入log的存放目錄,運作
[root@mysql_data]#mysqldumpslow
slow-query.log
Reading mysql slow query log from
Count: 2 Time=11.00s (22s) Lock=0.00s (0s) Rows=1.0 (2), root[root]@mysql
select count(N) from t_user;
mysqldumpslow指令
/path/mysqldumpslow
-s c -t 10 /database/mysql/slow-query.log
這會輸出記錄次數最多的10條SQL語句,其中:
-s,
是表示按照何種方式排序,c、t、l、r分别是按照記錄次數、時間、查詢時間、傳回的記錄數來排序,ac、at、al、ar,表示相應的倒叙;
-t,
是top n的意思,即為傳回前面多少條的資料;
-g,
後邊可以寫一個正則比對模式,大小寫不敏感的;
例如:
-s r -t 10 /database/mysql/slow-log
得到傳回記錄集最多的10個查詢。
-s t -t 10 -g “left join” /database/mysql/slow-log
得到按照時間排序的前10條裡面含有左連接配接的查詢語句。
使用mysqldumpslow指令可以非常明确的得到各種我們需要的查詢語句,對MySQL查詢語句的監控、分析、優化是MySQL優化非常重要的一步。開啟慢查詢日志後,由于日志記錄操作,在一定程度上會占用CPU資源影響mysql的性能,但是可以階段性開啟來定位性能瓶頸。
使用 EXPLAIN 關鍵字可以模拟優化器執行SQL查詢語句,進而知道MySQL是如何處理你的SQL語句的。這可以幫你分析你的查詢語句或是表結構的性能瓶頸。通過explain指令可以得到:
–
表的讀取順序
資料讀取操作的操作類型
哪些索引可以使用
哪些索引被實際使用
表之間的引用
每張表有多少行被優化器查詢
EXPLAIN字段:
ØTable:顯示這一行的資料是關于哪張表的
Øpossible_keys:顯示可能應用在這張表中的索引。如果為空,沒有可能的索引。可以為相關的域從WHERE語句中選擇一個合适的語句
Økey:實際使用的索引。如果為NULL,則沒有使用索引。MYSQL很少會選擇優化不足的索引,此時可以在SELECT語句中使用USE
INDEX(index)來強制使用一個索引或者用IGNORE INDEX(index)來強制忽略索引
Økey_len:使用的索引的長度。在不損失精确性的情況下,長度越短越好
Øref:顯示索引的哪一列被使用了,如果可能的話,是一個常數
Ørows:MySQL認為必須檢索的用來傳回請求資料的行數
Øtype:這是最重要的字段之一,顯示查詢使用了何種類型。從最好到最差的連接配接類型為system、const、eq_reg、ref、range、index和ALL
nsystem、const:可以将查詢的變量轉為常量. 如id=1;
id為 主鍵或唯一鍵.
neq_ref:通路索引,傳回某單一行的資料.(通常在聯接時出現,查詢使用的索引為主鍵或惟一鍵)
nref:通路索引,傳回某個值的資料.(可以傳回多行)
通常使用=時發生
nrange:這個連接配接類型使用索引傳回一個範圍中的行,比如使用>或<查找東西,并且該字段上建有索引時發生的情況(注:不一定好于index)
nindex:以索引的順序進行全表掃描,優點是不用排序,缺點是還要全表掃描
nALL:全表掃描,應該盡量避免
ØExtra:關于MYSQL如何解析查詢的額外資訊,主要有以下幾種
nusing
index:隻用到索引,可以避免通路表.
where:使用到where來過慮資料. 不是所有的where clause都要顯示using where. 如以=方式通路索引.
tmporary:用到臨時表
filesort:用到額外的排序. (當使用order by v1,而沒用到索引時,就會使用額外的排序)
nrange
checked for eache record(index map:N):沒有好的索引.
通過慢日志查詢可以知道哪些SQL語句執行效率低下,通過explain我們可以得知SQL語句的具體執行情況,索引使用等,還可以結合show指令檢視執行狀态。
如果覺得explain的資訊不夠詳細,可以同通過profiling指令得到更準确的SQL執行消耗系統資源的資訊。
profiling預設是關閉的。可以通過以下語句檢視
打開功能:
mysql>set profiling=1; 執行需要測試的sql 語句:
mysql>
show profiles\G; 可以得到被執行的SQL語句的時間和ID
mysql>show
profile for query 1; 得到對應SQL語句執行的詳細資訊
Show
Profile指令格式:
SHOW
PROFILE [type [, type] … ]
[FOR QUERY n]
[LIMIT row_count [OFFSET offset]]
type:
ALL
| BLOCK IO
| CONTEXT SWITCHES
| CPU
| IPC
| MEMORY
| PAGE FAULTS
| SOURCE
| SWAPS
以上的16rows是針對非常簡單的select語句的資源資訊,對于較複雜的SQL語句,會有更多的行和字段,比如converting
HEAP to MyISAM 、Copying to tmp
table等等,由于以上的SQL語句不存在複雜的表操作,是以未顯示這些字段。通過profiling資源耗費資訊,我們可以采取針對性的優化措施。
測試完畢以後
,關閉參數:mysql> set profiling=0
2
索引及查詢優化
索引的類型
Ø 普通索引:這是最基本的索引類型,沒唯一性之類的限制。
Ø 唯一性索引:和普通索引基本相同,但所有的索引列值保持唯一性。
Ø 主鍵:主鍵是一種唯一索引,但必須指定為”PRIMARY
KEY”。
Ø 全文索引:MYSQL從3.23.23開始支援全文索引和全文檢索。在MYSQL中,全文索引的索引類型為FULLTEXT。全文索引可以在VARCHAR或者TEXT類型的列上建立。
大多數MySQL索引(PRIMARY
KEY、UNIQUE、INDEX和FULLTEXT)使用B樹中存儲。空間列類型的索引使用R-樹,MEMORY表支援hash索引。
單列索引和多列索引(複合索引)
索引可以是單列索引,也可以是多列索引。對相關的列使用索引是提高SELECT操作性能的最佳途徑之一。
多列索引:
MySQL可以為多個列建立索引。一個索引可以包括15個列。對于某些列類型,可以索引列的左字首,列的順序非常重要。
多列索引可以視為包含通過連接配接索引列的值而建立的值的排序的數組。一般來說,即使是限制最嚴格的單列索引,它的限制能力也遠遠低于多列索引。
最左字首
多列索引有一個特點,即最左字首(Leftmost
Prefixing)。假如有一個多列索引為key(firstname lastname
age),當搜尋條件是以下各種列的組合和順序時,MySQL将使用該多列索引:
firstname,lastname,age
firstname,lastname
firstname
也就是說,相當于還建立了key(firstname
lastname)和key(firstname)。
索引主要用于下面的操作:
Ø 快速找出比對一個WHERE子句的行。
Ø 删除行。當執行聯接時,從其它表檢索行。
Ø 對具體有索引的列key_col找出MAX()或MIN()值。由預處理器進行優化,檢查是否對索引中在key_col之前發生所有關鍵字元素使用了WHERE key_part_# = constant。在這種情況下,MySQL為每個MIN()或MAX()表達式執行一次關鍵字查找,并用常數替換它。如果所有表達式替換為常量,查詢立即傳回。例如:
SELECT
MIN(key2), MAX (key2) FROM tb WHERE key1=10;
Ø 如果對一個可用關鍵字的最左面的字首進行了排序或分組(例如,ORDER
BY key_part_1,key_part_2),排序或分組一個表。如果所有關鍵字元素後面有DESC,關鍵字以倒序被讀取。
Ø 在一些情況中,可以對一個查詢進行優化以便不用查詢資料行即可以檢索值。如果查詢隻使用來自某個表的數字型并且構成某些關鍵字的最左面字首的列,為了更快,可以從索引樹檢索出值。
SELECT key_part3 FROM tb WHERE key_part1=1
有時MySQL不使用索引,即使有可用的索引。一種情形是當優化器估計到使用索引将需要MySQL通路表中的大部分行時。(在這種情況下,表掃描可能會更快些)。然而,如果此類查詢使用LIMIT隻搜尋部分行,MySQL則使用索引,因為它可以更快地找到幾行并在結果中傳回。例如:
合理的建立索引的建議:
(1)
越小的資料類型通常更好:越小的資料類型通常在磁盤、記憶體和CPU緩存中都需要更少的空間,處理起來更快。
(2)
簡單的資料類型更好:整型資料比起字元,處理開銷更小,因為字元串的比較更複雜。在MySQL中,應該用内置的日期和時間資料類型,而不是用字元串來存儲時間;以及用整型資料類型存儲IP位址。
(3)
盡量避免NULL:應該指定列為NOT
NULL,除非你想存儲NULL。在MySQL中,含有空值的列很難進行查詢優化,因為它們使得索引、索引的統計資訊以及比較運算更加複雜。你應該用0、一個特殊的值或者一個空串代替空值
這部分是關于索引和寫SQL語句時應當注意的一些瑣碎建議和注意點。
1. 當結果集隻有一行資料時使用LIMIT
2. 避免SELECT
*,始終指定你需要的列
從表中讀取越多的資料,查詢會變得更慢。他增加了磁盤需要操作的時間,還是在資料庫伺服器與WEB伺服器是獨立分開的情況下。你将會經曆非常漫長的網絡延遲,僅僅是因為資料不必要的在伺服器之間傳輸。
3. 使用連接配接(JOIN)來代替子查詢(Sub-Queries)
連接配接(JOIN).. 之是以更有效率一些,是因為MySQL不需要在記憶體中建立臨時表來完成這個邏輯上的需要兩個步驟的查詢工作。
4. 使用ENUM、CHAR 而不是VARCHAR,使用合理的字段屬性長度
5. 盡可能的使用NOT
NULL
6. 固定長度的表會更快
7. 拆分大的DELETE 或INSERT 語句
8. 查詢的列越小越快
Where條件
在查詢中,WHERE條件也是一個比較重要的因素,盡量少并且是合理的where條件是很重要的,盡量在多個條件的時候,把會提取盡量少資料量的條件放在前面,減少後一個where條件的查詢時間。
有些where條件會導緻索引無效:
Ø where子句的查詢條件裡有!=,MySQL将無法使用索引。
Ø where子句使用了Mysql函數的時候,索引将無效,比如:select
* from tb where left(name, 4) = ‘xxx’
Ø 使用LIKE進行搜尋比對的時候,這樣索引是有效的:select
* from tbl1 where name like ‘xxx%’,而like ‘%xxx%’ 時索引無效
三、 配置優化
安裝MySQL後,配置檔案my.cnf在
/MySQL安裝目錄/share/mysql目錄中,該目錄中還包含多個配置檔案可供參考,有my-large.cnf ,my-huge.cnf,
my-medium.cnf,my-small.cnf,分别對應大中小型資料庫應用的配置。win環境下即存在于MySQL安裝目錄中的.ini檔案。
下面列出了對性能優化影響較大的主要變量,主要分為連接配接請求的變量和緩沖區變量。
1. 連接配接請求的變量:
1)
max_connections
MySQL的最大連接配接數,增加該值增加mysqld
要求的檔案描述符的數量。如果伺服器的并發連接配接請求量比較大,建議調高此值,以增加并行連接配接數量,當然這建立在機器能支撐的情況下,因為如果連接配接數越多,介于MySQL會為每個連接配接提供連接配接緩沖區,就會開銷越多的記憶體,是以要适當調整該值,不能盲目提高設值。
數值過小會經常出現ERROR
1040: Too many connections錯誤,可以過’conn%’通配符檢視目前狀态的連接配接數量,以定奪該值的大小。
show
variables like ‘max_connections’ 最大連接配接數
show
status like ‘max_used_connections’響應的連接配接數
如下:
show variables like ‘max_connections‘;
+———————–+——-+
|
Variable_name | Value |
max_connections | 256 |
show status like ‘max%connections‘;
Variable_name | Value |
+—————————-+——-+
max_used_connections | 256|
max_used_connections
/ max_connections * 100% (理想值≈ 85%)
如果max_used_connections跟max_connections相同
那麼就是max_connections設定過低或者超過伺服器負載上限了,低于10%則設定過大。
2) back_log
MySQL能暫存的連接配接數量。當主要MySQL線程在一個很短時間内得到非常多的連接配接請求,這就起作用。如果MySQL的連接配接資料達到max_connections時,新來的請求将會被存在堆棧中,以等待某一連接配接釋放資源,該堆棧的數量即back_log,如果等待連接配接的數量超過back_log,将不被授予連接配接資源。
back_log值指出在MySQL暫時停止回答新請求之前的短時間内有多少個請求可以被存在堆棧中。隻有如果期望在一個短時間内有很多連接配接,你需要增加它,換句話說,這值對到來的TCP/IP連接配接的偵聽隊列的大小。
當觀察你主機程序清單(mysql>
show full processlist),發現大量264084 | unauthenticated user | xxx.xxx.xxx.xxx |
NULL | Connect | NULL | login | NULL 的待連接配接程序時,就要加大back_log 的值了。
預設數值是50,可調優為128,對于Linux系統設定範圍為小于512的整數。
3) interactive_timeout
一個互動連接配接在被伺服器在關閉前等待行動的秒數。一個互動的客戶被定義為對mysql_real_connect()使用CLIENT_INTERACTIVE
選項的客戶。
預設數值是28800,可調優為7200。
2. 緩沖區變量
全局緩沖:
4)
key_buffer_size
key_buffer_size指定索引緩沖區的大小,它決定索引處理的速度,尤其是索引讀的速度。通過檢查狀态值Key_read_requests和Key_reads,可以知道key_buffer_size設定是否合理。比例key_reads
/ key_read_requests應該盡可能的低,至少是1:100,1:1000更好(上述狀态值可以使用SHOW STATUS LIKE
‘key_read%’獲得)。
key_buffer_size隻對MyISAM表起作用。即使你不使用MyISAM表,但是内部的臨時磁盤表是MyISAM表,也要使用該值。可以使用檢查狀态值created_tmp_disk_tables得知詳情。
舉例如下:
show variables like ‘key_buffer_size‘;
+——————-+————+
Variable_name | Value |
+———————+————+
key_buffer_size | 536870912 |
+————
———-+————+
key_buffer_size為512MB,我們再看一下key_buffer_size的使用情況:
show global status like ‘key_read%‘;
+————————+————-+
Variable_name | Value |
Key_read_requests| 27813678764 |
Key_reads | 6798830 |
一共有27813678764個索引讀取請求,有6798830個請求在記憶體中沒有找到直接從硬碟讀取索引,計算索引未命中緩存的機率:
key_cache_miss_rate
=Key_reads / Key_read_requests * 100%,設定在1/1000左右較好
預設配置數值是8388600(8M),主機有4GB記憶體,可以調優值為268435456(256MB)。
5)
query_cache_size
使用查詢緩沖,MySQL将查詢結果存放在緩沖區中,今後對于同樣的SELECT語句(區分大小寫),将直接從緩沖區中讀取結果。
通過檢查狀态值Qcache_*,可以知道query_cache_size設定是否合理(上述狀态值可以使用SHOW
STATUS LIKE
‘Qcache%’獲得)。如果Qcache_lowmem_prunes的值非常大,則表明經常出現緩沖不夠的情況,如果Qcache_hits的值也非常大,則表明查詢緩沖使用非常頻繁,此時需要增加緩沖大小;如果Qcache_hits的值不大,則表明你的查詢重複率很低,這種情況下使用查詢緩沖反而會影響效率,那麼可以考慮不用查詢緩沖。此外,在SELECT語句中加入SQL_NO_CACHE可以明确表示不使用查詢緩沖。
與查詢緩沖有關的參數還有query_cache_type、query_cache_limit、query_cache_min_res_unit。
query_cache_type指定是否使用查詢緩沖,可以設定為0、1、2,該變量是SESSION級的變量。
query_cache_limit指定單個查詢能夠使用的緩沖區大小,預設為1M。
query_cache_min_res_unit是在4.1版本以後引入的,它指定配置設定緩沖區空間的最小機關,預設為4K。檢查狀态值Qcache_free_blocks,如果該值非常大,則表明緩沖區中碎片很多,這就表明查詢結果都比較小,此時需要減小query_cache_min_res_unit。
show global status like ‘qcache%‘;
+——————————-+—————–+
Variable_name | Value |
Qcache_free_blocks | 22756 |
Qcache_free_memory | 76764704 |
Qcache_hits | 213028692 |
Qcache_inserts | 208894227 |
Qcache_lowmem_prunes | 4010916 |
Qcache_not_cached | 13385031 |
Qcache_queries_in_cache | 43560 |
Qcache_total_blocks | 111212 |
show variables like ‘query_cache%‘;
+————————————–+————–+
Variable_name | Value |
+————————————–+———–+
query_cache_limit | 2097152 |
query_cache_min_res_unit | 4096 |
query_cache_size | 203423744 |
query_cache_type | ON |
query_cache_wlock_invalidate | OFF |
+————————————–+—————+
查詢緩存碎片率=
Qcache_free_blocks / Qcache_total_blocks * 100%
如果查詢緩存碎片率超過20%,可以用FLUSH
QUERY CACHE整理緩存碎片,或者試試減小query_cache_min_res_unit,如果你的查詢都是小資料量的話。
查詢緩存使用率=
(query_cache_size – Qcache_free_memory) / query_cache_size * 100%
查詢緩存使用率在25%以下的話說明query_cache_size設定的過大,可适當減小;查詢緩存使用率在80%以上而且Qcache_lowmem_prunes
> 50的話說明query_cache_size可能有點小,要不就是碎片太多。
查詢緩存命中率=
(Qcache_hits – Qcache_inserts) / Qcache_hits * 100%
示例伺服器查詢緩存碎片率=20.46%,查詢緩存使用率=62.26%,查詢緩存命中率=1.94%,命中率很差,可能寫操作比較頻繁吧,而且可能有些碎片。
每個連接配接的緩沖
6) record_buffer_size
每個進行一個順序掃描的線程為其掃描的每張表配置設定這個大小的一個緩沖區。如果你做很多順序掃描,你可能想要增加該值。
預設數值是131072(128K),可改為16773120
(16M)
7) read_rnd_buffer_size
随機讀緩沖區大小。當按任意順序讀取行時(例如,按照排序順序),将配置設定一個随機讀緩存區。進行排序查詢時,MySQL會首先掃描一遍該緩沖,以避免磁盤搜尋,提高查詢速度,如果需要排序大量資料,可适當調高該值。但MySQL會為每個客戶連接配接發放該緩沖空間,是以應盡量适當設定該值,以避免記憶體開銷過大。
一般可設定為16M
8)
sort_buffer_size
每個需要進行排序的線程配置設定該大小的一個緩沖區。增加這值加速ORDER
BY或GROUP BY操作。
預設數值是2097144(2M),可改為16777208
(16M)。
9) join_buffer_size
聯合查詢操作所能使用的緩沖區大小
record_buffer_size,read_rnd_buffer_size,sort_buffer_size,join_buffer_size為每個線程獨占,也就是說,如果有100個線程連接配接,則占用為16M*100
10)
table_cache
表高速緩存的大小。每當MySQL通路一個表時,如果在表緩沖區中還有空間,該表就被打開并放入其中,這樣可以更快地通路表内容。通過檢查峰值時間的狀态值Open_tables和Opened_tables,可以決定是否需要增加table_cache的值。如果你發現open_tables等于table_cache,并且opened_tables在不斷增長,那麼你就需要增加table_cache的值了(上述狀态值可以使用SHOW
‘Open%tables’獲得)。注意,不能盲目地把table_cache設定成很大的值。如果設定得太高,可能會造成檔案描述符不足,進而造成性能不穩定或者連接配接失敗。
1G記憶體機器,推薦值是128-256。記憶體在4GB左右的伺服器該參數可設定為256M或384M。
11)
max_heap_table_size
使用者可以建立的記憶體表(memory
table)的大小。這個值用來計算記憶體表的最大行數值。這個變量支援動态改變,即set @max_heap_table_size=#
這個變量和tmp_table_size一起限制了内部記憶體表的大小。如果某個内部heap(堆積)表大小超過tmp_table_size,MySQL可以根據需要自動将記憶體中的heap表改為基于硬碟的MyISAM表。
12)
tmp_table_size
通過設定tmp_table_size選項來增加一張臨時表的大小,例如做進階GROUP
BY操作生成的臨時表。如果調高該值,MySQL同時将增加heap表的大小,可達到提高聯接查詢速度的效果,建議盡量優化查詢,要確定查詢過程中生成的臨時表在記憶體中,避免臨時表過大導緻生成基于硬碟的MyISAM表。
show global status like ‘created_tmp%‘;
+——————————–+———+
Variable_name | Value |
+———————————-+———+
Created_tmp_disk_tables | 21197 |
Created_tmp_files | 58 |
Created_tmp_tables | 1771587 |
+——————————–+———–+
每次建立臨時表,Created_tmp_tables增加,如果臨時表大小超過tmp_table_size,則是在磁盤上建立臨時表,Created_tmp_disk_tables也增加,Created_tmp_files表示MySQL服務建立的臨時檔案檔案數,比較理想的配置是:
Created_tmp_disk_tables
/ Created_tmp_tables * 100% <= 25%比如上面的伺服器Created_tmp_disk_tables /
Created_tmp_tables * 100% =1.20%,應該相當好了
預設為16M,可調到64-256最佳,線程獨占,太大可能記憶體不夠I/O堵塞
13) thread_cache_size
可以複用的儲存在中的線程的數量。如果有,新的線程從緩存中取得,當斷開連接配接的時候如果有空間,客戶的線置在緩存中。如果有很多新的線程,為了提高性能可以這個變量值。
通過比較
Connections和Threads_created狀态的變量,可以看到這個變量的作用。
預設值為110,可調優為80。
14)
thread_concurrency
推薦設定為伺服器 CPU核數的2倍,例如雙核的CPU,
那麼thread_concurrency的應該為4;2個雙核的cpu, thread_concurrency的值應為8。預設為8
15)
wait_timeout
指定一個請求的最大連接配接時間,對于4GB左右記憶體的伺服器可以設定為5-10。
3. 配置InnoDB的幾個變量
innodb_buffer_pool_size
對于InnoDB表來說,innodb_buffer_pool_size的作用就相當于key_buffer_size對于MyISAM表的作用一樣。InnoDB使用該參數指定大小的記憶體來緩沖資料和索引。對于單獨的MySQL資料庫伺服器,最大可以把該值設定成實體記憶體的80%。
根據MySQL手冊,對于2G記憶體的機器,推薦值是1G(50%)。
innodb_flush_log_at_trx_commit
主要控制了innodb将log
buffer中的資料寫入日志檔案并flush磁盤的時間點,取值分别為0、1、2三個。0,表示當事務送出時,不做日志寫入操作,而是每秒鐘将log
buffer中的資料寫入日志檔案并flush磁盤一次;1,則在每秒鐘或是每次事物的送出都會引起日志檔案寫入、flush磁盤的操作,確定了事務的ACID;設定為2,每次事務送出引起寫入日志檔案的動作,但每秒鐘完成一次flush磁盤操作。
實際測試發現,該值對插入資料的速度影響非常大,設定為2時插入10000條記錄隻需要2秒,設定為0時隻需要1秒,而設定為1時則需要229秒。是以,MySQL手冊也建議盡量将插入操作合并成一個事務,這樣可以大幅提高速度。
根據MySQL手冊,在允許丢失最近部分事務的危險的前提下,可以把該值設為0或2。
innodb_log_buffer_size
log緩存大小,一般為1-8M,預設為1M,對于較大的事務,可以增大緩存大小。
可設定為4M或8M。
innodb_additional_mem_pool_size
該參數指定InnoDB用來存儲資料字典和其他内部資料結構的記憶體池大小。預設值是1M。通常不用太大,隻要夠用就行,應該與表結構的複雜度有關系。如果不夠用,MySQL會在錯誤日志中寫入一條警告資訊。
根據MySQL手冊,對于2G記憶體的機器,推薦值是20M,可适當增加。
innodb_thread_concurrency=8
推薦設定為 2*(NumCPUs+NumDisks),預設一般為8
| 作者:Agoly 出處:https://www.cnblogs.com/qmfsun/ 本文版權歸作者和部落格園共有,歡迎轉載,但未經作者同意必須保留此段聲明,且在文章頁面明顯位置給出原文連接配接,否則保留追究法律責任的權利。 如果文中有什麼錯誤,歡迎指出。以免更多的人被誤導。 |