端到端目标檢測模型
事實上,Sparse R-CNN 很多地方是借鑒了去年 Facebook 釋出的 DETR,當時應該也算是驚豔衆人。其有兩點:
無需 nms 進行端到端的目标檢測
将 NLP 中的 Transformer 引入到了 CV 領域(關于 Transformer 我在這裡有提到。)
然而 DETR 需要每個目标的 query 和全局語義資訊進行 interact(這裡可以了解為進行相關性的計算),DETR 這種密集(dense)計算的性質使得其訓練時間長,而且限制了它成為一個徹底的稀疏(sparse)的目标檢測算法。Sparse R-CNN 則認為 sparse 性質在于兩方面:
sparse boxes:是指小數量的 starting boxes(初始的 boxes),這已經足以預測一張圖中的所有目标了。
sparse features:暗指每個 box 的 feature 不需要和全圖中所有其他的 features 進行 interact。
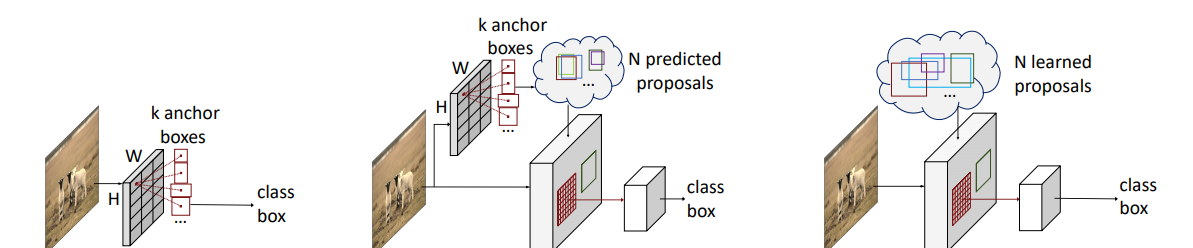
目前主流的目标檢測算法可以分為:一階段和兩階段的目标檢測算法,兩階段的目标檢測算法常常是有先驗框(anchor-based)的,而一階段又分為 anchor-based 和 anchor-free 兩種。如果根據定義 object candidates 的方式來分:
♠ Dense object candidates
這類算法常常是一階段的,它們采用密集的候選目标進行預測。比如,anchor-based 會根據特征圖的大小鋪設先驗框,假如特征圖大小是 \(B \times C \times 8 \times 8\)。這張特征圖最終會預測出 \(8 \times 8 \times K\) 個先驗框的偏移(因為這 64 個位置上,每個位置有預設不同長寬比的 K 個先驗框,每個先驗框有 4 個參數,是以它等于預測了原圖上的 64 位置上所有先驗框的偏移),先驗框根據預測偏移得到最後的預測框。在訓練階段預測框根據預測框與真值框的比較(可能是 IoU 或其他标準)進行正樣本的确定,在測試階段通過後處理來過濾掉多餘的框。
同理 anchor-free 的算法,同樣也是根據這樣網格點式的去預測,不同的是它沒有先驗框了,可能會直接預測角點的坐标或者中心點偏移長寬或格點到四條邊的距離。總之,最後每個格點會得到一個框,選取正樣本也許跟 anchor-based 一樣,也許就直接根據格點離真值框中心來确定。預測部分是一樣的。
♣ Dense to sparse object candidates
這類算法一般是兩階段的,在第一階段它們像 Dense object candidates 進行預測,但是每個位置不預測類别,隻預測是前景還是背景。然後選出可能機率在 top 2k 的框,對特征圖或者原圖進行截取,通過 roi-aligned 等操作調整到統一的大小,進行第二階段的預測。第二階段主要預測每個框的具體類别與位置資訊的再次調整。
♥ sparse object candidates
這類算法直接提出 k 個區域或者說 boxes,例如 DETR、Deformable-DETR、Sparse-RCNN。訓練的時候通過匈牙利算法進行一對一的比對,預測的時候隻需設定分數進行過濾就行了。
在上述分類中,無論是第一類還是第二類都存在以下的問題:
産生太多備援的結果和十分接近的結果,是以而不得不使用 NMS,而 NMS 會産生很多問題(比如在單階段的算法中因為分類和回歸不一緻影響算法表現;物體密集時,将正确的結果給抑制掉了)
在訓練中多對一的配置設定規則使得網絡對啟發式配置設定規則十分敏感
性能表現極大受到尺寸、縱橫比和先驗框的數量影響
正是以,sparse 類的網絡不斷提出,實作 one-to-one 的比對原則,去除了人工預設的先驗框與複雜的後處理。

首先使用 resnet + fpn 進行特征圖的提取,然後使用初始化的 proposal boxes 和 proposal features 進行疊代式地對 proposal boxes 進行修正。
文章的 backbone + neck 是使用的 Resnet50 + FPN 或者 Resnet101 + FPN。其中 Resnet 部分是将 res2 - res5 的輸出輸入到 FPN 之中,FPN 的最頂層是用 LastLevelMaxPool 得到,但最後隻使用了 p2 - p5 (eg. p2 是由 res2 得到的),輸出特征的通道均為 256。
首先,使用 Embedding 的權重獲得 shape 為 (num_proposals, 4) 的初始化 proposal boxes(這裡 boxes 的第二維是中心點坐标和寬高在的原圖的比例),并将 proposal boxes 初始值設定為 (0.5, 0.5, 1, 1),也就是說最初始的 proposal boxes 在圖檔中心,寬高與圖檔相同。作者也提供了其他初始化的方式,比如均勻分布在圖檔上,沒有采用,應該是這個效果最好),proposal features 則是直接采用 shape 為 (num_proposals, proposal_dim) 的 Embedding 的權重。(在文中 num_proposals 為 100/300 即建議框的數量)
如上圖所示,RCNNHead 主要接收三個輸入 fpn features, proposal boxes, proposal features,其中後面兩個輸入使用上述 initial 方式作為初始值,之後使用預測的 boxes 和 features 作為下一個 RCNNHead 的輸入。是以這裡是一個不斷疊代不斷修正的過程。首先使用 fpn features 和 proposal boxes 經過 roi-align 得到 roi features,然後和 proposal features 進行 instance interactive(這裡比較容易了解這個名字,因為 roi features 和 proposal features 都是 num_proposals 個 proposal 的 feature。輸出為 pred_class, pred_boxes, proposal_features 後兩者會被送入下一個 RCNNHead。(值得注意的是 boxes 是脫離了計算圖後被送入的)
DynamicConv 的作用就是将 roi features 和 proposal features 進行 instance interactive,如上圖具體的做法就是 proposal features 通過 fc 層得到相應 params。文章代碼是将得到的 params 分為兩部分,然後先後與 roi features 進行矩陣相乘,最後經過全連接配接層得到 features,再送入 RCNNHead 進行 class 和 boxes 的預測。
♥ Learnable proposal boxes
關于 proposal boxes 需要注意以下幾點:
除了最開始初始化的 proposal boxes,後面都是用的前一個 RCNNHead 預測的 boxes 作為的 proposal boxes。主要作用是擷取 fpn features 上相應區域的 features。
最初始的 boxes 是相對于圖檔歸一化的資料,但是送入網絡前會被調整為真實大小,預測的實際上偏移量,同樣會被調整為經偏移量調整後的 boxes。
RPN 的 proposals 與目前的圖檔強相關并且提供粗糙的位置資訊,然而文章認為後面階段的 RCNNHead 來 refine 初始的 boxes 代價是很大的,是以文章認為将包含所有潛在目标的位置統計資訊(即整張圖)讓網絡直接去選擇,會更加有效。
♦ Learnable proposal features
文章考慮到 4 維的 proposal box 雖然能簡單明了地描述 objects,但是很多語義資訊、目标的形狀、目标的姿勢等都丢失了。是以,使用了更高維的 tensor 來編碼豐富的執行個體特征。
♠ 其他細節
Each RoI feature is fed into its own exclusive head for object location and classification, where each head is conditioned on specific proposal feature
這裡圖看起來是一個并行的結構,實際上代碼實作的是一個疊代的過程,上一個 head 預測的 boxes 和 proposal features 送入下一個 head,進入 head 後使用 boxes 獲得該 head 的 RoI feature。需要注意的是,boxes 雖然使用上一個 head 的結果,但是會和上一個 head 的計算圖分離,不會進行梯度回傳,proposal boxes 則是會梯度回傳到上一個 head。
The proposal feature generates kernel parameters of convolution, then RoI feature is processed by the generated convolution to obtain the final feature.
這裡就是上文提到也是上圖展示的 proposal features 會通過 fc 得到 param,這個 param 會當作卷積的 kernel。而且文章使用矩陣相乘的形式來實作這種卷積。
Sparse R-CNN 實際上沿用的 DETR 的 loss 和正樣本比對方式即:使用 Hungarian 算法。
\[\mathcal{L} = \lambda_{cls} \cdot \mathcal{L}_{cls} + \lambda_{L1} \cdot \mathcal{L}_{L1} + \lambda_{giou} \cdot \mathcal{L}_{giou}
\]
其中 \(\lambda\) 是權重因子,上式的權重因子分别為:2.0,5.0,2.0。我覺得這樣設定的原因在于 boxes 的 l1 loss 是歸一化後進行計算的,如果按照百分之一的誤差,那麼 boxes 會降到 0.04(因為有 4 個參數的 l1 loss)。此時分類 loss 和 giou loss 肯定在 0.1 及其以上,這樣的話 boxes l1 占比很小,不會作為主要優化的一項,也就不可能降到 0.1 了,便到不到百分之一的誤差了。論文的 l1 loss 是計算的左上角和右下角 xyxy 與真值的絕對值之和,而 DETR 則是使用的中心點坐标加上寬高。另外論文使用了 focal loss 作為分類損失函數,DETR 使用的多類别交叉熵。
優化器選擇了 AdamW 使用了 0.0001 的權重衰減,batch-size 為 16,8 塊 GPU,學習率為 0.000025, 并在 epoch 為 27 或者 33 時進行十倍的減少。預訓練權重是在 ImageNet 上訓練的,其餘的層都使用 Xavier 進行初始化。采用了多尺度訓練和預測。
唯一的後處理是将無效的 boxes 進行移除,然後将 boxes 調整為适合原圖大小的尺寸(因為圖檔進行了 resize)。eval 的時候直接全部送入 coco 裡面,根據作者介紹 coco 的計算方式會比對分數最高的 boxes ,其餘的不會産生影響。在測試階段,設定一個分數(因為隻有有物體的框分數才比較高)這裡 DETR 設定的 0.7。
可以看到其隻用了 36 epoch 達到了比 DETR 500 epoch 還好的效果。
官方代碼位置
Pytorch 代碼位置
Paddle 代碼位置