關注公衆号:大資料技術派,回複"資料",領取<code>1024G</code>資料。
這一課時我們将講解 Flink “精确一次”的語義實作原理,同時這也是面試的必考點。
Flink 的“精确一次”處理語義是,Flink 提供了一個強大的語義保證,也就是說在任何情況下都能保證資料對應用産生的效果隻有一次,不會多也不會少。
那麼 Flink 是如何實作“端到端的精确一次處理”語義的呢?
通常情況下,流式計算系統都會為使用者提供指定資料處理的可靠模式功能,用來表明在實際生産運作中會對資料處理做哪些保障。一般來說,流處理引擎通常為使用者的應用程式提供三種資料處理語義:最多一次、至少一次和精确一次。
最多一次(At-most-Once):這種語義了解起來很簡單,使用者的資料隻會被處理一次,不管成功還是失敗,不會重試也不會重發。
至少一次(At-least-Once):這種語義下,系統會保證資料或事件至少被處理一次。如果中間發生錯誤或者丢失,那麼會從源頭重新發送一條然後進入處理系統,是以同一個事件或者消息會被處理多次。
精确一次(Exactly-Once):表示每一條資料隻會被精确地處理一次,不多也不少。
Exactly-Once 是 Flink、Spark 等流處理系統的核心特性之一,這種語義會保證每一條消息隻被流處理系統處理一次。“精确一次” 語義是 Flink 1.4.0 版本引入的一個重要特性,而且,Flink 号稱支援“端到端的精确一次”語義。
在這裡我們解釋一下“端到端(End to End)的精确一次”,它指的是 Flink 應用從 Source 端開始到 Sink 端結束,資料必須經過的起始點和結束點。Flink 自身是無法保證外部系統“精确一次”語義的,是以 Flink 若要實作所謂“端到端(End to End)的精确一次”的要求,那麼外部系統必須支援“精确一次”語義;然後借助 Flink 提供的分布式快照和兩階段送出才能實作。
我們在之前的課程中講解過 Flink 的容錯機制,Flink 提供了失敗恢複的容錯機制,而這個容錯機制的核心就是持續建立分布式資料流的快照來實作。
同 Spark 相比,Spark 僅僅是針對 Driver 的故障恢複 Checkpoint。而 Flink 的快照可以到算子級别,并且對全局資料也可以做快照。Flink 的分布式快照受到 Chandy-Lamport 分布式快照算法啟發,同時進行了量身定做,有興趣的同學可以搜一下。
Flink 分布式快照的核心元素之一是 Barrier(資料栅欄),我們也可以把 Barrier 簡單地了解成一個标記,該标記是嚴格有序的,并且随着資料流往下流動。每個 Barrier 都帶有自己的 ID,Barrier 極其輕量,并不會幹擾正常的資料處理。
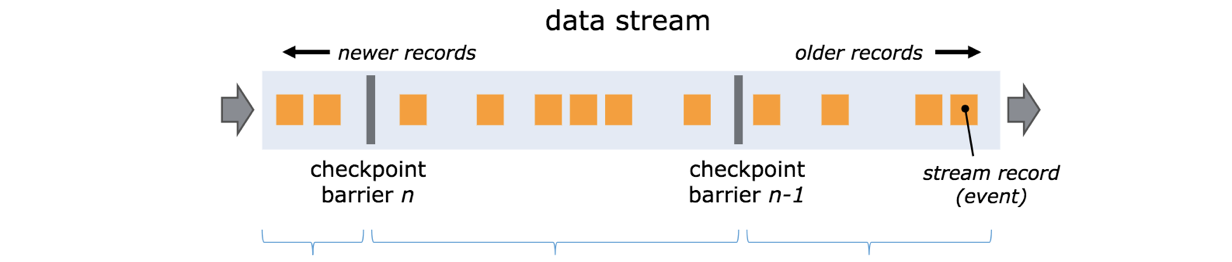
如上圖所示,假如我們有一個從左向右流動的資料流,Flink 會依次生成 snapshot 1、 snapshot 2、snapshot 3……Flink 中有一個專門的“協調者”負責收集每個 snapshot 的位置資訊,這個“協調者”也是高可用的。
Barrier 會随着正常資料繼續往下流動,每當遇到一個算子,算子會插入一個辨別,這個辨別的插入時間是上遊所有的輸入流都接收到 snapshot n。與此同時,當我們的 sink 算子接收到所有上遊流發送的 Barrier 時,那麼就表明這一批資料處理完畢,Flink 會向“協調者”發送确認消息,表明目前的 snapshot n 完成了。當所有的 sink 算子都确認這批資料成功處理後,那麼本次的 snapshot 被辨別為完成。
這裡就會有一個問題,因為 Flink 運作在分布式環境中,一個 operator 的上遊會有很多流,每個流的 barrier n 到達的時間不一緻怎麼辦?這裡 Flink 采取的措施是:快流等慢流。

拿上圖的 barrier n 來說,其中一個流到的早,其他的流到的比較晚。當第一個 barrier n到來後,目前的 operator 會繼續等待其他流的 barrier n。直到所有的barrier n 到來後,operator 才會把所有的資料向下發送。
按照上面我們介紹的機制,每次在把快照存儲到我們的狀态後端時,如果是同步進行就會阻塞正常任務,進而引入延遲。是以 Flink 在做快照存儲時,可采用異步方式。
此外,由于 checkpoint 是一個全局狀态,使用者儲存的狀态可能非常大,多數達 G 或者 T 級别。在這種情況下,checkpoint 的建立會非常慢,而且執行時占用的資源也比較多,是以 Flink 提出了增量快照的概念。也就是說,每次都是進行的全量 checkpoint,是基于上次進行更新的。
上面我們講解了基于 checkpoint 的快照操作,快照機制能夠保證作業出現 fail-over 後可以從最新的快照進行恢複,即分布式快照機制可以保證 Flink 系統内部的“精确一次”處理。但是我們在實際生産系統中,Flink 會對接各種各樣的外部系統,比如 Kafka、HDFS 等,一旦 Flink 作業出現失敗,作業會重新消費舊資料,這時候就會出現重新消費的情況,也就是重複消費。
針對這種情況,Flink 1.4 版本引入了一個很重要的功能:兩階段送出,也就是 TwoPhaseCommitSinkFunction。兩階段搭配特定的 source 和 sink(特别是 0.11 版本 Kafka)使得“精确一次處理語義”成為可能。
在 Flink 中兩階段送出的實作方法被封裝到了 TwoPhaseCommitSinkFunction 這個抽象類中,我們隻需要實作其中的beginTransaction、preCommit、commit、abort 四個方法就可以實作“精确一次”的處理語義,實作的方式我們可以在官網中查到:
beginTransaction,在開啟事務之前,我們在目标檔案系統的臨時目錄中建立一個臨時檔案,後面在處理資料時将資料寫入此檔案;
preCommit,在預送出階段,刷寫(flush)檔案,然後關閉檔案,之後就不能寫入到檔案了,我們還将為屬于下一個檢查點的任何後續寫入啟動新事務;
commit,在送出階段,我們将預送出的檔案原子性移動到真正的目标目錄中,請注意,這會增加輸出資料可見性的延遲;
abort,在中止階段,我們删除臨時檔案。
如上圖所示,我們用 Kafka-Flink-Kafka 這個案例來介紹一下實作“端到端精确一次”語義的過程,整個過程包括:
從 Kafka 讀取資料
視窗聚合操作
将資料寫回 Kafka
整個過程可以總結為下面四個階段:
一旦 Flink 開始做 checkpoint 操作,那麼就會進入 pre-commit 階段,同時 Flink JobManager 會将檢查點 Barrier 注入資料流中 ;
當所有的 barrier 在算子中成功進行一遍傳遞,并完成快照後,則 pre-commit 階段完成;
等所有的算子完成“預送出”,就會發起一個“送出”動作,但是任何一個“預送出”失敗都會導緻 Flink 復原到最近的 checkpoint;
pre-commit 完成,必須要確定 commit 也要成功,上圖中的 Sink Operators 和 Kafka Sink 會共同來保證。
目前 Flink 支援的精确一次 Source 清單如下表所示,你可以使用對應的 connector 來實作對應的語義要求:
資料源
語義保證
備注
Apache Kafka
exactly once
需要對應的 Kafka 版本
AWS Kinesis Streams
RabbitMQ
at most once (v 0.10) / exactly once (v 1.0)
Twitter Streaming API
at most once
Collections
Files
Sockets
如果你需要實作真正的“端到端精确一次語義”,則需要 sink 的配合。目前 Flink 支援的清單如下表所示:
寫入目标
HDFS rolling sink
依賴 Hadoop 版本
Elasticsearch
at least once
Kafka producer
at least once / exactly once
需要 Kafka 0.11 及以上
Cassandra sink
幂等更新
File sinks
Socket sinks
Standard output
Redis sink
由于強大的異步快照機制和兩階段送出,Flink 實作了“端到端的精确一次語義”,在特定的業務場景下十分重要,我們在進行業務開發需要語義保證時,要十分熟悉目前 Flink 支援的語義特性。
這一課時的内容較為晦澀,建議你從源碼中去看一下具體的實作。
猜你喜歡
Spark SQL知識點與實戰
Hive計算最大連續登陸天數
Hadoop 資料遷移用法詳解
數倉模組化分層理論
數倉模組化—寬表的設計