函數 genfis1
格式 fismat = genfis1(data)
fismat = genfis1(data,numMFs,inmftype, outmftype)
說明 genfis1為anfis訓練生成一個Sugeno型作為初始條件的FIS結構(初始隸屬函數)。genfis1(data,numMFs,inmftype, outmftype)使用對資料的網格分割方法,從訓練資料集生成一個FIS結構。Data是訓練資料矩陣,除最後一清單示單一輸出資料外,它的其它各清單示輸入資料。NumMFs是一個向量,它的坐标指定與每一輸入相關的隸屬函數的數量。如果你想使用每個輸入相關的相同數量的隸屬函數,那麼隻須使numMFs成為一個數就足夠了。Inmftype是一個字元串數組,它的每行指定與每個輸入相關的隸屬函數類型。outmftype是一個字元串數組,它的指定與每個輸出相關的隸屬函數類型
例6-19
>>data = [rand(10,1) 10*rand(10,1)-5 rand(10,1)];
>>numMFs = [3 7];
>>mfType = str2mat('pimf','trimf');
>>fismat = genfis1(data,numMFs,mfType);
>> [x,mf] = plotmf(fismat,'input',1);
>>subplot(2,1,1), plot(x,mf);
>>xlabel('input 1 (pimf)');
>>[x,mf] = plotmf(fismat,'input',2);
>>subplot(2,1,2), plot(x,mf);
>>xlabel('input 2 (trimf)');
結果為圖6-21。
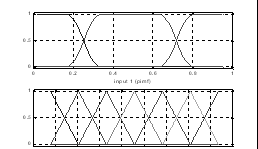
圖6-21
函數 genfis2
格式 fismat = genfis2(Xin,Xout,radii)
fismat = genfis2(Xin,Xout,radii,xBounds)
fismat = genfis2(Xin,Xout,radii,xBounds,options)
說明 Xin是一個矩陣,它的每一行包含一個資料點的輸入值;Xout是一個矩陣,它的每一行包含一個資料點的輸出值;randi是一個向量,它指定一個聚類中心在一個資料維上作用的範圍,這裡假定資料位于一個機關超立方體内:xBounds是一個2×N可選矩陣,它用于指定如何将Xin和Xout中的資料映射到一個超立方體内,這裡是資料的維數(行數); options是一個可選向量,它指定的值用于覆寫算法參數的預設值。
例6-20
fismat = genfis2(Xin,Xout,0.5)
這是使用此函數所需的最小變量數。這裡對所有資料維指定0.5的作用範圍。
fismat = genfis2(Xin,Xout,[0.5 0.25 0.3])
這裡假定組合的維數是3。假設Xin有兩維、Xout有一維,那麼,0.5和0.25是Xin資料維中每一維的作用範圍,0.3是Xout資料維的作用範圍。
fismat = genfis2(Xin,Xout,0.5,[-10 -5 0; 10 5 20])
這裡指定了如何将Xin和Xout中的資料規範化為[0 1]區間中的值來進行處理。假設Xin有兩維、Xout有一維,那麼Xin第一列中的資料是從[-10 +10]比例變換後的值,Xin第二列中的資料是從[-5 +5]比例變換後的值,Xout中的資料是從[0 20]比例變換後的值。
函數 gensurf
格式 gensurf(fis) %使用前兩個輸入和第一個輸出來生成給定模糊推理系統(fis)的輸出曲面
gensurf(fis,inputs,output) %使用分别由向量input和标量output給定的輸入(一個或兩個)和輸出(隻允許一個)來生成一個圖形。
gensurf(fis,inputs,output,grids) %指定X(第一、水準)和Y(第二、垂直)方向的網格數。如果是二進制向量,X和Y方向上的網格可以獨立設定。
gensurf(fis,inputs,output,grids,refinput) %用于多于兩個的輸入,refinput向量的長度與輸入相同:
·将對應于要顯示的輸入的refinput項,設定為NaN;
·對其它輸入的固定值設定為雙精度實标量。
[x,y,z]=gensurf(…) %傳回定義輸出曲面的變量并且删除自動繪圖。
例6-21
>>a = readfis('tipper');
>>gensurf(a)
結果為圖6-22。

圖6-22
函數 mam2sug
格式 sug_fis=mam2sug(mam_fis)
說明 該函數将一個mamdani型FIS結構(不必是單輸出)mam_fis轉化為一個sugeno型結構sug_fis。傳回的sugeno型系統具有常值輸出隸屬度函數。這些常值由原來mamdani型系統的後件的隸屬度函數的面積中心法來确定。前件仍保持不變。
函數 evalfis
格式 output= evalfis(input,fismat)
output= evalfis(input,fismat, numPts)
[output, IRR, ORR, ARR]= evalfis(input,fismat)
[output, IRR, ORR, ARR]= evalfis(input,fismat, numPts)
說明 input:指定輸入值的一個數或一個矩陣,如果輸入是一個M×N矩陣,其中N是輸入變量數,那麼evalfis使用 input的每一行作為一個輸入向量,并且為變量output傳回M×L矩陣,該矩陣每一行是一個向量并且L是輸出變量數;
fismat:要計算的一個FIS結構;
numPts:一個可選變量,它表示在輸入或輸出範圍内的采樣點數,在這些點上計算隸屬函數,如果 不使用此變量,就使用101點的預設值。
Evalfis的值域如下:
Output:大小為ML的輸出矩陣,這裡M表示前面指定的輸入值的數量, L表示FIS的輸出變量數。
evalfis的可選值域變量隻有當input是一個行向量時才計算這些可選值域變量是:
IRR:通過隸屬函數計算的輸入變量的結果,這是一個大小為numRulesN的矩陣,這裡numRules是規則條數,N是輸入變量數。
ORR:通過隸屬函數計算的輸出變量的結果,這是一個大小為numPtsnumRulesL的矩陣,這裡numRules是規則條數,L是輸出變量數,此矩陣的第一組numRules列,對應于第一個輸出,第二組numRules 對應于第二個輸出,依次類推。
ARR:對每個輸出,在輸出值域中,numPts處采樣合成值的numPtsL矩陣,當隻有一個值域變量調用時,該函數使用由結構fismat指定的模糊推理系統,由标量或矩陣inout指定的輸入值計算輸出向量output。
例6-22
>>fismat = readfis('tipper');
>>out = evalfis([2 1; 4 9],fismat)
結果為
out =
7.0169
19.6810
函數 fcm
格式 [center,U,obj_fcn] = fcm(data,cluster_n)
說明 對給定的資料集應用模糊c均值聚類方法進行聚類
data:要聚類的資料集,每行是一個采樣資料點;
cluster_n:聚類中心的個數(大于1)
center:疊代後得到的聚類中心的矩陣,這裡每行給出聚類中心的坐标;
U:得到的所有點對聚類中心的模糊分類矩陣或隸屬度函數矩陣;
Obj_fcn:疊代過程中,目标函數的值;
fcm(data,cluster_n,options)使用可選的變量options控制聚類參數。包括停止準則,和/或設定疊代資訊顯示:
options(1):分類矩陣U的指數,預設值是2.0;
options(2):最大疊代次數,預設值是100;
options(3):最小改進量,即疊代停止的誤差準則,預設值是1e-5;
option(4):疊代過程中顯示資訊,預設值是1。
如果任意一項為NaN,這些選項就使用預設值;當達到最大疊代次數時,或目标函數兩次連續疊代的改進量小于指定的最小改進量,即滿足停止誤差準則時,聚類過程結束。
例6-23
>>data = rand(100, 2);
>>[center,U,obj_fcn] = fcm(data, 2);
>>plot(data(:,1), data(:,2),'o');
>>maxU = max(U);
>>index1 = find(U(1,:) == maxU);
>>index2 = find(U(2, :) == maxU);
>>line(data(index1,1), data(index1, 2), 'linestyle', 'none', 'marker', '*', 'color', 'g');
>>line(data(index2,1), data(index2, 2), 'linestyle', 'none', 'marker', '*', 'color', 'r');
結果為圖6-23。
函數 findcluster
格式 findcluster
findcluster('file.dat')
說明 findcluster産生一個GUI上的Method下的下拉式标簽,可以實作模糊C均值(fcm)或模糊減法聚類(subtractiv),使用Load Data按鈕輸入資料,剛進入GUI時,對每種方法的選項都設定為預設值。
此工具使用多元資料集,但隻顯示這些維數中的兩維。使用X-axis和Y-axis下的下拉式标簽選擇你想觀察的資料維。例如你有一個五維資料集,按照出現在資料集中的順序,此工具将資料标記為data_1,data_2,data_3,data_4,data_5, Start将完成聚類,Save Centre将儲存聚類中心。
當使用資料集file.data時,findcluster(file.dat)自動裝入資料集,并且隻繪制資料集中的前兩維。産生GUI後,你仍可以選擇要聚類資料的那兩維。
例6-24
>>findcluster('clusterdemo.dat')
結果為圖6-24。
函數 plotfis
格式 plotfis(fismat)
說明 此函數顯示由fismat指定的一個FIS的高層方框圖,輸入和它們的隸屬函數出現在結構特征圖的左邊,同時輸出和它們的隸屬函數出現在結構特征圖的右邊。
例6-25
>>plotfis(a)
結果為圖6-25。
圖6-24 圖6-25
函數 plotmf
格式 plotmf(fismat,varType,varIndex)
說明 此函數繪制與給定變量相關的稱為fismat的FIS中的所有隸屬函數曲線,變量的類型和索引分别由varType ('input' 或'output')和varIndex給出。此函數也可以與MATLAB函數subplot一起使用。
例6-26
>>plotmf(a,'input',1)
結果為圖6-26。
圖6-26
函數 readfis
格式 fismat = readfis('filename')
說明 從磁盤上的一個.fis檔案(由filename命名)讀出一個模糊推理系統,并将産生的FIS裝入目前的工作空間中。Fismat = readfis不帶輸入變量,即沒有指定檔案名時,使用uigetfile指令打開一個對話框,提示使用者指定檔案的名稱和目錄位置。
例6-27
>>getfis(fismat)
傳回結果
getfis(fismat)
Name = tipper
Type = mamdani
NumInputs = 2
InLabels =
service
food
NumOutputs = 1
OutLabels =
tip
NumRules = 3
AndMethod = min
OrMethod = max
ImpMethod = min
AggMethod = max
DefuzzMethod = centroid
ans =
tipper
函數 rmmf
格式 fis = rmmf(fis,'varType',varIndex,'mf',mfIndex)
說明 從與工作空間FIS結構fis相關的模糊推理系統中删除變量類型為varType,索引為varIndex的隸屬函數mfIndex。
字元串vartype必須是'input' 或'output'。
varIndex是表示變量索引的一個整數,此索引表示列出變量的順序;
變量'mf '是表示隸屬函數的一個字元串;
mfIndex是表示隸屬函數索引的一個整數,此索引表示列出隸屬函數的順序。
例6-28
>>a = newfis('mysys');
>>a = addvar(a,'input','temperature',[0 100]);
>>a = addmf(a,'input',1,'cold','trimf',[0 30 60]);
>>getfis(a,'input',1)
Name = temperature
NumMFs = 1
MFLabels =
cold
Range = [0 100]
[ ]
>>b = rmmf(a,'input',1,'mf',1);
>>getfis(b,'input',1)
傳回
Name = temperature
NumMFs = 0
函數 rmvar
格式 [fis2,errorStr] = rmvar(fis,'varType',varIndex)
fis2 = rmvar(fis,'varType',varIndex)
說明 fis2 = rmvar(fis,'varType',varIndex),)從與工作空間FIS結構fis相關的模糊推理系統中删除索引為varIndex的語言變量mfIndex,字元串vartype必須是'input' 或'output'。
varIndex是表示變量索引的一個整數,此索引表示列出變量的順序。
[fis2,errorStr] = rmvar(fis,'varType',varIndex) 将任何錯誤資訊傳回到字元串errorStr。
此指令自動更新規則清單以保證清單尺寸與目前變量數保持一緻,在删除語言變量之前,你必須從FIS删除任何包含要删除變量的規則,你無法删除在規則清單中正在使用的模糊變量。
例6-29
>>getfis(a)
傳回:
Name = mysys
NumInputs = 1
temperature
NumOutputs = 0
NumRules = 0
mysys
>>b = rmvar(a,'input',1);
>>getfis(b)
Name = mysys
NumInputs = 0
函數 setfis
格式 a = setfis(a,'fispropname','newfisprop')
a = setfis(a,'vartype',varindex,'varpropname','newvarprop')
a = setfis(a,'vartype',varindex,'mf',mfindex, 'mfpropname','newmfprop');
說明 可以使用三個、五個或七個輸入變量調用setfis指令,使用幾個輸入變量取決于是否設定整個結構的一個屬性,是否設定屬于該結構的一個特定變量,還是是否設定屬于這些變量之一的一個特定隸屬函數。這些變量是:
a:工作空間中FIS的一個變量名稱,
vartype:表示變量類型的一個字元串:input或output;
varindex:輸入或輸出變量的索引;
mf:調用setfis時,七個變量中的第四個變量所用的字元串,用語指明此變量是一個隸屬函數;
mfindex:屬于所選變量的隸屬函數的索引;
fispropname:表示你要設定FIS域屬性的一個字元串:name,type,andmethod, ormethod, impmethod,aggmethod,defuzzmethod;
newfisprop:你要設定的FIS的屬性或方法名稱的一個字元串;
varpropname:你要設定的變量域名稱的一個字元串:name或range;
newvarprop:你要設定的變量名稱的一個字元串(對name),或變量範圍的一個數組(對range),mfpropname—你要設定的隸屬函數名稱的一個字元串:name,type或params;
newmfprop:你要設定的隸屬函數名稱或類型域的一個字元串(對name或type)或者是參數範圍的一個數組(對params)。
例6-30 使用三個變量調用:
>>a2 = setfis(a, 'name', 'eating');
>>getfis(a2, 'name');
結果為:
eating
如果使用五個變量,setfis将更新兩個變量屬性:
>>a2 = setfis(a,'input',1,'name','help');
>>getfis(a2,'input',1,'name')
help
如果使用七個變量,setfis将更新七個隸屬函數的任意屬性:
>>a2 = setfis(a,'input',1,'mf',2,'name','wretched');
>>getfis(a2,'input',1,'mf',2,'name')
wretched
函數 showfis
格式 showfis(fismat)
說明 以分行方式顯示MATLAB工作空間FIS變量fismat,允許你檢視結構的每個域的意義和内容。
例6-31
>>showfis(a)
1. Name tipper
2. Type mamdani
3. Inputs/Outputs [2 1]
4. NumInputMFs [3 2]
5. NumOutputMFs 3
6. NumRules 3
7. AndMethod min
8. OrMethod max
9. ImpMethod min
10. AggMethod max
11. DefuzzMethod centroid
12. InLabels service
13. food
14. OutLabels tip
15. InRange [0 10]
16. [0 10]
17. OutRange [0 30]
18. InMFLabels poor
19. good
20. excellent
21. rancid
22. delicious
23. OutMFLabels cheap
24. average
25. generous
26. InMFTypes gaussmf
27. gaussmf
28. gaussmf
29. trapmf
30. trapmf
31. OutMFTypes trimf
32. trimf
33. trimf
34. InMFParams [1.5 0 0 0]
35. [1.5 5 0 0]
36. [1.5 10 0 0]
37. [0 0 1 3]
38. [7 9 10 10]
39. OutMFParams [0 5 10 0]
40. [10 15 20 0]
41. [20 25 30 0]
42. Rule Antecedent [1 1]
43. [2 0]
44. [3 2]
42. Rule Consequent 1
43. 2
44. 3
42. Rule Weigth 1
43. 1
44. 1
42. Rule Connection 2
44. 2
函數 fuzarith
格式 C = fuzarith(X, A, B, operator)
說明 使用區間算法,C = fuzarith(X, A, B, operator)傳回一個模糊集C作為結果,該算法使用由字元串operator表示的函數,并在采樣凸模糊集A和B上完成二進制運算;元素A和B由采樣值域變量X的凸函數産生;
A,B和X是相同維數的向量;
operator是下列串之一:'sum', 'sub', 'prod', and 'div';
該函數傳回的模糊集C是一個與X具有相同長度的列向量
例6-32
>>point_n = 101;% this determines MF's resolution
>>min_x = -20; max_x = 20;% universe is [min_x, max_x]
>>x = linspace(min_x, max_x, point_n)';
>>A = trapmf(x, [-10 -2 1 3]);% trapezoidal fuzzy set A
>>B = gaussmf(x, [2 5]);% Gaussian fuzzy set B
>>C1 = fuzarith(x, A, B, 'sum');
>>subplot(2,1,1);
>>plot(x, A, 'b--', x, B, 'm:', x, C1, 'c');
>>title('fuzzy addition A+B');
>>C2 = fuzarith(x, A, B, 'sub');
>>subplot(2,1,2);
>>plot(x, A, 'b--', x, B, 'm:', x, C2, 'c');
>>title('fuzzy subtraction A-B');
>>C3 = fuzarith(x, A, B, 'prod');
結果為圖6-27。
圖6-27
函數 parsrule
格式 fis2 = parsrule(fis,txtRuleList)
fis2 = parsrule(fis,txtRuleList,ruleFormat)
fis2 = parsrule(fis,txtRuleList,ruleFormat,lang)
說明 此函數為MATLAB工作空間FIS變量fis解析定義規則(txtRuleList)的文本,并且傳回添加了相應規則清單的一個FIS結構。如果原始輸入FIS結構fis有任意初始規則,他們将由新結構fis2替換。本函數支援三種不同的規則格式(由ruleFormat指定'verbose' (語言型)、'symbolic' (符号型)、'indexed' (索引型)。預設格式是'verbose' (語言型)。當使用可選語言變量lang時,規則以語言型格式進行解析,并采用語言變量lang中指定的關鍵字。語言必須是'english'、'francais'或 'deutsch'。英語關鍵字是if、then、is、AND、OR和NOT。
例6-33
>>ruleTxt = 'if service is poor then tip is generous';
>>a2 = parsrule(a,ruleTxt,'verbose');
>>showrule(a2)
1. If (service is poor) then (tip is generous) (1)
函數 ruleedit
格式 ruleedit('a')
ruleedit(a)
說明 當使用ruleedit('a')調用規則編輯器時,可用于修改存儲在檔案a.fis中的一個FIS結構的規則。它也可用于檢查模糊推理系統使用的規則。為使用編輯器建立規則,你必須首先用FIS編輯器定義要使用的所有輸入輸出變量,你可以使用清單框和檢查框選擇輸入、輸出變量,連接配接操作和權重來建立新規則。如圖所示,用ruleedit('tank')打開規則編輯器并裝入tank.fis中存儲的所有規則。
圖6-28
菜單項:在規則編輯器GUI上,有一個菜單棒允許你打開相關的GUI工具、打開和儲存系統等。File菜單與FIS編輯器上的File菜單功能相同。
·Edit菜單項包括:
Undo 用于恢複最近的改變;
·View菜單項包括:
Edit FIS properties… 調用FIS編輯器;
Edit membership functions… 調用隸屬度函數編輯器;
Edit rules… 調用規則編輯器;
View surface… 調用曲面觀察器。
·Options 菜單項包括:
Language 用于選擇語言:English、Deutsch和Francais;
Format 用于選擇格式
·Verbose 使用單詞“if”、“then”、“AND”、“OR”等建立實際語句。
·Symbolic 用某些符号代替Verbose模式中使用的單詞。例如:“if A AND
B then C”成為“A&B=>C”。
·indexed 表示規則如何在FIS結構中存儲。
函數 ruleview
格式 ruleview('a')
說明 使用ruleview('a') 調用規則觀察器時,将繪制在存儲檔案a.fis中的一個FIS的模糊推理框圖。它用于觀察從開始到結束整個蘊含過程。你可以移動對應輸入的訓示線,然後觀察系統重新調節并計算新的輸出。如圖6-29:ruleview('tank' )
圖6-29
菜單項:在規則編輯器GUI上,有一個菜單棒允許你打開相關的GUI工具、打開和儲存系統,等等。File菜單與FIS編輯器上的File菜單功能相同。
Rules display format 用于選擇顯示規則的格式。如果單擊模糊推理方框圖左邊的規則序号,與該序号相關的規則出現在規則觀察器底部的狀态棒中。
函數 writefis
格式 writefis(fismat)
writefis(fismat,'filename')
writefis(fismat,'filename','dialog')
說明 writefis将一個MATLAB工作空間FIS結構fismat用一個.fis檔案形式儲存到磁盤上;
writefis(fismat)産生一個對話框讓使用者輸入檔案的名稱和存放檔案的目錄;
writefis(fismat,'filename')将對應于FIS結構fismat的一個.fis檔案寫到一個稱為filename.fis的磁盤檔案中,不使用對話框該檔案被儲存在目前目錄中;
writefis(fismat,'filename','dialog')建立一個帶有提供的預設名為filename.fis的對話框;
若擴充名不存在,則隻為filename添加.fis擴充名。
例6-34
>>a = newfis('tipper');
>>a = addvar(a,'input','service',[0 10]);
>>a = addmf(a,'input',1,'poor','gaussmf',[1.5 0]);
>>a = addmf(a,'input',1,'good','gaussmf',[1.5 5]);
>>a = addmf(a,'input',1,'excellent','gaussmf',[1.5 10]);
>>writefis(a,'my_file')
結果為 ans =
my_file
函數 showrule
格式 showrule(fis)
showrule(fis,indexList)
showrule(fis,indexList,format)
showrule(fis,indexList,format,Lang)
說明 此指令用于顯示與給定系統相關的規則。
fis是必須提供的變量,這是一個FIS結構在MATLAB工作空間中的變量名;
indexList是你要顯示的規則向量(可選項);
format是一個表示傳回規則格式的字元串(可選項),showrule可以用三種不同格式的任意一種傳回規則:'verbose' (預設模式,此處English是預設語言), 'symbolic'和'indexed',它們用于隸屬度函數的索引引用;
若要使用第四個參數Lang,則Lang必須是verbose(語言)型的,并且下面這種調用showrule(fis,indexList,format,Lang)使用Lang給定的語言顯示規則,它們必須是'english','francais'或'deutsch'。
例6-35
>>showrule(a,1)
1. If (service is poor) or (food is rancid) then (tip is cheap) (1)
>>showrule(a,2)
2. If (service is good) then (tip is average) (1)
>>showrule(a,[3 1],'symbolic')
3. (service==excellent) | (food==delicious) => (tip=generous) (1)
1. (service==poor) | (food==rancid) => (tip=cheap) (1)
>>showrule(a,1:3,'indexed')
1 1, 1 (1) : 2
2 0, 2 (1) : 1
3 2, 3 (1) : 2
格式 showfis(fismat)
例6-36
44. 2matlab