l 主機作業系統:Windows 64位,雙核4線程,主頻2.2G,10G記憶體
l 虛拟軟體:VMware® Workstation 9.0.0 build-812388
l 虛拟機作業系統:CentOS6.5 64位,單核
l 虛拟機運作環境:
Ø JDK:1.7.0_55 64位
Ø Hadoop:2.2.0(需要編譯為64位)
Ø Scala:2.10.4
Ø Spark:1.1.0(需要編譯)
Ø Hive:0.13.1(源代碼編譯,參見1.2)
本次實驗環境隻需要hadoop1一台機器即可,網絡環境配置如下:
序号
IP位址
機器名
類型
使用者名
目錄
1
192.168.0.61
hadoop1
NN/DN
hadoop
/app 程式所在路徑
/app/scala-...
/app/hadoop
/app/complied
這裡選擇下載下傳的版本為hive-0.13.1,這個版本需要到apache的歸檔伺服器下載下傳,下載下傳位址:http://archive.apache.org/dist/hive/hive-0.13.1/,選擇apache-hive-0.13.1-src.tar.gz檔案進行下載下傳:
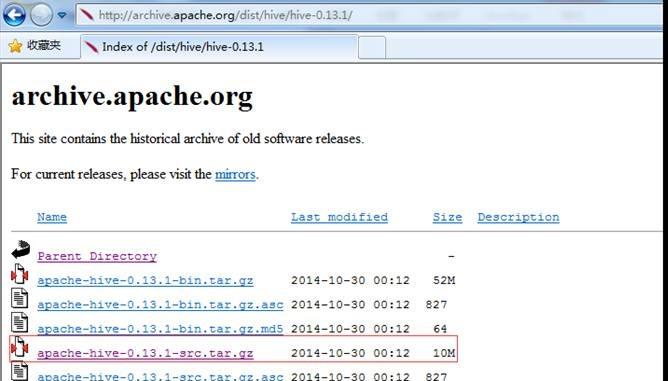
把下載下傳的hive-0.13.0.tar.gz安裝包,使用SSH Secure File Transfer工具(參見第2課《Spark編譯與部署(上)--基礎環境搭建》1.3.1介紹)上傳到/home/hadoop/upload 目錄下。
到上傳目錄下,用如下指令解壓縮hive安裝檔案:
$cd /home/hadoop/upload
$tar -zxf apache-hive-0.13.1-src.tar.gz
改名并移動到/app/complied目錄下:
$sudo mv apache-hive-0.13.1-src /app/complied/hive-0.13.1-src
$ll /app/complied
編譯Hive源代碼的時候,需要從網上下載下傳依賴包,是以整個編譯過程機器必須保證在聯網狀态。編譯執行如下腳本:
$cd /app/complied/hive-0.13.1-src/
$export MAVEN_OPTS="-Xmx2g -XX:MaxPermSize=512M -XX:ReservedCodeCacheSize=512m"
$mvn -Phadoop-2,dist -Dmaven.test.skip=true clean package

在編譯過程中可能出現速度慢或者中斷,可以再次啟動編譯,編譯程式會在上次的編譯中斷處繼續進行編譯,整個編譯過程耗時與網速緊密相關,網速較快的情況需要1個小時左右(上圖的時間是多次編譯後最後成功的界面)。最終編譯的結果為$HIVE_HOME/packaging/target/apache-hive-0.13.1-bin.tar.gz
通過如下指令檢視最終編譯完成整個目錄大小,可以看到大小為353.6M左右
$du -s /app/complied/hive-0.13.1-src
【注】已經編譯好的Hive包在本系列配套資源/install/6.hive-0.13.1-src.tar.gz,讀者直接使用
由于首次運作hive-console需要在Spark源代碼進行編譯,關于Spark源代碼的擷取可以參考第二課《Spark編譯與部署(下)--Spark編譯安裝》方式進行擷取,連接配接位址為 http://spark.apache.org/downloads.html,擷取源代碼後把Spark源代碼移動到/app/complied目錄,并命名為spark-1.1.0-hive
第一步 使用如下指令打開/etc/profile檔案:
$sudo vi /etc/profile
第二步 設定如下參數:
export HADOOP_HOME=/app/hadoop/hadoop-2.2.0
export HIVE_HOME=/app/complied/hive-0.13.1-src
export HIVE_DEV_HOME=/app/complied/hive-0.13.1-src
第三步 生效配置并驗證
$echo $HIVE_DEV_HOME
運作hive/console不需要啟動Spark,需要進入到Spark根目錄下使用sbt/sbt hive/console進行首次運作編譯,編譯以後下次可以直接啟動。編譯Spark源代碼的時候,需要從網上下載下傳依賴包,是以整個編譯過程機器必須保證在聯網狀态。編譯指令如下:
$cd /app/complied/spark-1.1.0-hive
$sbt/sbt hive/console
編譯時間會很長,在編譯過程中可能出現速度慢或者中斷,可以再次啟動編譯,編譯程式會在上次的編譯中斷處繼續進行編譯,整個編譯過程耗時與網速緊密相關。
通過如下指令檢視最終編譯完成整個目錄大小,可以看到大小為267.9M左右
$du -s /app/complied/spark-1.1.0-hive
【注】已經編譯好的Spark for hive-console包在本系列配套資源/install/6.spark-1.1.0-hive.tar.gz,可直接使用
進入到spark根目錄下,使用如下指令啟動hive-console
可以使用:help檢視幫助内容
scala>:help
可以使用tab鍵檢視所有可使用指令、函數
首先定義Person類,在該類中定義name、age和state三個列,然後把該類注冊為people表并裝載資料,最後通過查詢到資料存放到query中
scala>case class Person(name:String, age:Int, state:String)
scala>sparkContext.parallelize(Person("Michael",29,"CA")::Person("Andy",30,"NY")::Person("Justin",19,"CA")::Person("Justin",25,"CA")::Nil).registerTempTable("people")
scala>val query= sql("select * from people")
scala>query.printSchema
scala>query.collect()
scala>query.queryExecution
scala>query.queryExecution.logical
scala>query.queryExecution.analyzed
scala>query.queryExecution.optimizedPlan
scala>query.queryExecution.sparkPlan
scala>query.toDebugString
上面常用操作裡介紹了源自RDD的資料, SparkSQL也可以源自多個資料源:jsonFile、parquetFile和Hive等。
第一步 Json測試資料
Json檔案支援嵌套表,SparkSQL也可以讀入嵌套表,如下面形式的Json資料,可以使用jsonFile讀入SparkSQL。該檔案可以在配套資源/data/class6中找到,在以下測試中把檔案放到 /home/hadoop/upload/class6 路徑中
{
"fullname": "Sean Kelly",
"org": "SK Consulting",
"emailaddrs": [
{"type": "work", "value": "[email protected]"},
{"type": "home", "pref": 1, "value": "[email protected]"}
],
"telephones": [
{"type": "work", "pref": 1, "value": "+1 214 555 1212"},
{"type": "fax", "value": "+1 214 555 1213"},
{"type": "mobile", "value": "+1 214 555 1214"}
"addresses": [
{"type": "work", "format": "us",
"value": "1234 Main StnSpringfield, TX 78080-1216"},
{"type": "home", "format": "us",
"value": "5678 Main StnSpringfield, TX 78080-1316"}
"urls": [
{"type": "work", "value": "http://seankelly.biz/"},
{"type": "home", "value": "http://seankelly.tv/"}
]
}
第二步 讀入Json資料
使用jsonFile讀入資料并注冊成表jsonPerson,然後定義一個查詢jsonQuery
scala>jsonFile("/home/hadoop/upload/class6/nestjson.json").registerTempTable("jsonPerson")
scala>val jsonQuery = sql("select * from jsonPerson")
第三步 檢視jsonQuery的schema
scala>jsonQuery.printSchema
第四步 檢視jsonQuery的整個運作計劃
scala>jsonQuery.queryExecution
Parquet資料放在配套資源/data/class6/wiki_parquet中,在以下測試中把檔案放到 /home/hadoop/upload/class6 路徑下
第一步 讀入Parquet資料
parquet檔案讀入并注冊成表parquetWiki,然後定義一個查詢parquetQuery
scala>parquetFile("/home/hadoop/upload/class6/wiki_parquet").registerTempTable("parquetWiki")
scala>val parquetQuery = sql("select * from parquetWiki")
有報錯但不影響使用
第二步 查詢parquetQuery的schema
scala>parquetQuery.printSchema
第三步 查詢parquetQuery的整個運作計劃
scala>parquetQuery.queryExecution
第四步 查詢取樣
scala>parquetQuery.takeSample(false,10,2)
在TestHive類中已經定義了大量的hive0.13的測試資料的表格式,如src、sales等等,在hive-console中可以直接使用;第一次使用的時候,hive-console會裝載一次。下面我們使用sales表看看其schema和整個運作計劃。
第一步 讀入測試資料并定義一個查詢hiveQuery
scala>val hiveQuery = sql("select * from sales")
第二步 檢視hiveQuery的schema
scala>hiveQuery.printSchema
第三步 檢視hiveQuery的整個運作計劃
scala>hiveQuery.queryExecution
第四步 其他SQL語句的運作計劃
scala>val hiveQuery = sql("select * from (select * from src limit 5) a limit 3")
scala>val hiveQuery = sql("select * FROM (select * FROM src) a")
scala>hiveQuery.where('key === 100).queryExecution.toRdd.collect
scala>sql("select name, age,state as location from people").queryExecution
scala>sql("select name from (select name,state as location from people) a where location='CA'").queryExecution
scala>sql("select sum(age) from people").queryExecution
scala>sql("select sum(age) from people").toDebugString
scala>sql("select state,avg(age) from people group by state").queryExecution
scala>sql("select state,avg(age) from people group by state").toDebugString
scala>sql("select a.name,b.name from people a join people b where a.name=b.name").queryExecution
scala>sql("select a.name,b.name from people a join people b where a.name=b.name").toDebugString
scala>sql("select distinct a.name,b.name from people a join people b where a.name=b.name").queryExecution
scala>sql("select distinct a.name,b.name from people a join people b where a.name=b.name").toDebugString
CombineFilters就是合并Filter,在含有多個Filter時發生,如下查詢:
sql("select name from (select * from people where age >=19) a where a.age <30").queryExecution
上面的查詢,在Optimized的過程中,将age>=19和age<30這兩個Filter合并了,合并成((age>=19) && (age<30))。其實上面還做了一個其他的優化,就是project的下推,子查詢使用了表的所有列,而主查詢使用了列name,在查詢資料的時候子查詢優化成隻查列name。
PushPredicateThroughProject就是project下推,和上面例子中的project一樣
sql("select name from (select name,state as location from people) a where location='CA'").queryExecution
ConstantFolding是常量疊加,用于表達式。如下面的例子:
sql("select name,1+2 from people").queryExecution
Spark是一個快速的記憶體計算架構,同時是一個并行運算的架構,在計算性能調優的時候,除了要考慮廣為人知的木桶原理外,還要考慮平行運算的Amdahl定理。
木桶原理又稱短闆理論,其核心思想是:一隻木桶盛水的多少,并不取決于桶壁上最高的那塊木塊,而是取決于桶壁上最短的那塊。将這個理論應用到系統性能優化上,系統的最終性能取決于系統中性能表現最差的元件。例如,即使系統擁有充足的記憶體資源和CPU資源,但是如果磁盤I/O性能低下,那麼系統的總體性能是取決于目前最慢的磁盤I/O速度,而不是目前最優越的CPU或者記憶體。在這種情況下,如果需要進一步提升系統性能,優化記憶體或者CPU資源是毫無用處的。隻有提高磁盤I/O性能才能對系統的整體性能進行優化。
Amdahl定理,一個計算機科學界的經驗法則,因吉恩·阿姆達爾而得名。它代表了處理器平行運算之後效率提升的能力。并行計算中的加速比是用并行前的執行速度和并行後的執行速度之比來表示的,它表示了在并行化之後的效率提升情況。阿姆達爾定律是固定負載(計算總量不變時)時的量化标準。可用公式:
來表示。式中
分别表示問題規模的串行分量(問題中不能并行化的那一部分)和并行分量,p表示處理器數量。當
時,上式的極限是
,其中
。這意味着無論我們如何增大處理器數目,加速比是無法高于這個數的。
SparkSQL作為Spark的一個元件,在調優的時候,也要充分考慮到上面的兩個原理,既要考慮如何充分的利用硬體資源,又要考慮如何利用好分布式系統的并行計算。由于測試環境條件有限,本篇不能做出更詳盡的實驗資料來說明,隻能在理論上加以說明。
SparkSQL在叢集中運作,将一個查詢任務分解成大量的Task配置設定給叢集中的各個節點來運作。通常情況下,Task的數量是大于叢集的并行度。比如前面第六章和第七章查詢資料時,shuffle的時候使用了預設的spark.sql.shuffle.partitions,即200個partition,也就是200個Task:
而實驗的叢集環境卻隻能并行3個Task,也就是說同時隻能有3個Task保持Running:
這時大家就應該明白了,要跑完這200個Task就要跑200/3=67批次。如何減少運作的批次呢?那就要盡量提高查詢任務的并行度。查詢任務的并行度由兩方面決定:叢集的處理能力和叢集的有效處理能力。
l對于Spark Standalone叢集來說,叢集的處理能力是由conf/spark-env中的SPARK_WORKER_INSTANCES參數、SPARK_WORKER_CORES參數決定的;而SPARK_WORKER_INSTANCES*SPARK_WORKER_CORES不能超過實體機器的實際CPU core;
l叢集的有效處理能力是指叢集中空閑的叢集資源,一般是指使用spark-submit或spark-shell時指定的--total-executor-cores,一般情況下,我們不需要指定,這時候,Spark Standalone叢集會将所有空閑的core配置設定給查詢,并且在Task輪詢運作過程中,Standalone叢集會将其他spark應用程式運作完後空閑出來的core也配置設定給正在運作中的查詢。
綜上所述,SparkSQL的查詢并行度主要和叢集的core數量相關,合理配置每個節點的core可以提高叢集的并行度,提高查詢的效率。
高效的資料格式,一方面是加快了資料的讀入速度,另一方面可以減少記憶體的消耗。高效的資料格式包括多個方面:
分布式計算系統的精粹在于移動計算而非移動資料,但是在實際的計算過程中,總存在着移動資料的情況,除非是在叢集的所有節點上都儲存資料的副本。移動資料,将資料從一個節點移動到另一個節點進行計算,不但消耗了網絡IO,也消耗了磁盤IO,降低了整個計算的效率。為了提高資料的本地性,除了優化算法(也就是修改spark記憶體,難度有點高),就是合理設定資料的副本。設定資料的副本,這需要通過配置參數并長期觀察運作狀态才能擷取的一個經驗值。
下面是Spark webUI監控Stage的一個圖:
lPROCESS_LOCAL是指讀取緩存在本地節點的資料
lNODE_LOCAL是指讀取本地節點硬碟資料
lANY是指讀取非本地節點資料
l通常讀取資料PROCESS_LOCAL>NODE_LOCAL>ANY,盡量使資料以PROCESS_LOCAL或NODE_LOCAL方式讀取。其中PROCESS_LOCAL還和cache有關。
對于要查詢的資料,定義合适的資料類型也是非常有必要。對于一個tinyint可以使用的資料列,不需要為了友善定義成int類型,一個tinyint的資料占用了1個byte,而int占用了4個byte。也就是說,一旦将這資料進行緩存的話,記憶體的消耗将增加數倍。在SparkSQL裡,定義合适的資料類型可以節省有限的記憶體資源。
對于要查詢的資料,在寫SQL語句的時候,盡量寫出要查詢的列名,如Select a,b from tbl,而不是使用Select * from tbl;這樣不但可以減少磁盤IO,也減少緩存時消耗的記憶體。
在查詢的時候,最終還是要讀取存儲在檔案系統中的檔案。采用更優的資料存儲格式,将有利于資料的讀取速度。檢視SparkSQL的Stage,可以發現,很多時候,資料讀取消耗占有很大的比重。對于sqlContext來說,支援 textFiile、SequenceFile、ParquetFile、jsonFile;對于hiveContext來說,支援AvroFile、ORCFile、Parquet File,以及各種壓縮。根據自己的業務需求,測試并選擇合适的資料存儲格式将有利于提高SparkSQL的查詢效率。
spark應用程式最糾結的地方就是記憶體的使用了,也是最能展現“細節是魔鬼”的地方。Spark的記憶體配置項有不少,其中比較重要的幾個是:
lSPARK_WORKER_MEMORY,在conf/spark-env.sh中配置SPARK_WORKER_MEMORY 和SPARK_WORKER_INSTANCES,可以充分的利用節點的記憶體資源,SPARK_WORKER_INSTANCES*SPARK_WORKER_MEMORY不要超過節點本身具備的記憶體容量;
lexecutor-memory,在spark-shell或spark-submit送出spark應用程式時申請使用的記憶體數量;不要超過節點的SPARK_WORKER_MEMORY;
lspark.storage.memoryFraction spark應用程式在所申請的記憶體資源中可用于cache的比例
lspark.shuffle.memoryFraction spark應用程式在所申請的記憶體資源中可用于shuffle的比例
在實際使用上,對于後兩個參數,可以根據常用查詢的記憶體消耗情況做适當的變更。另外,在SparkSQL使用上,有幾點建議:
l對于頻繁使用的表或查詢才進行緩存,對于隻使用一次的表不需要緩存;
l對于join操作,優先緩存較小的表;
l要多注意Stage的監控,多思考如何才能更多的Task使用PROCESS_LOCAL;
l要多注意Storage的監控,多思考如何才能Fraction cached的比例更多
對于SparkSQL,還有一個比較重要的參數,就是shuffle時候的Task數量,通過spark.sql.shuffle.partitions來調節。調節的基礎是spark叢集的處理能力和要處理的資料量,spark的預設值是200。Task過多,會産生很多的任務啟動開銷,Task多少,每個Task的處理時間過長,容易straggle。
優化的方面的内容很多,但大部分都是細節性的内容,下面就簡單地提提:
l 想要擷取更好的表達式查詢速度,可以将spark.sql.codegen設定為Ture;
l 對于大資料集的計算結果,不要使用collect() ,collect()就結果傳回給driver,很容易撐爆driver的記憶體;一般直接輸出到分布式檔案系統中;
l 對于Worker傾斜,設定spark.speculation=true 将持續不給力的節點去掉;
l 對于資料傾斜,采用加入部分中間步驟,如聚合後cache,具體情況具體分析;
l 适當的使用序化方案以及壓縮方案;
l 善于利用叢集監控系統,将叢集的運作狀況維持在一個合理的、平穩的狀态;
l 善于解決重點沖突,多觀察Stage中的Task,檢視最耗時的Task,查找原因并改善;
作者:石山園 出處:http://www.cnblogs.com/shishanyuan/
本文版權歸作者和部落格園共有,歡迎轉載,但未經作者同意必須保留此段聲明,且在文章頁面明顯位置給出原文連接配接,否則保留追究法律責任的權利。如果覺得還有幫助的話,可以點一下右下角的【推薦】,希望能夠持續的為大家帶來好的技術文章!想跟我一起進步麼?那就【關注】我吧。