這篇文章通過模拟動态推薦實驗,研究了閱聽人人數不平衡、模型偏差、位置偏差、閉環回報四種因素對推薦系統中流行度偏差的影響,認為閱聽人人數不平衡和模型偏差是造成流行度偏差的主要因素。并提出了兩種方法來去除動态場景下的popularity bias。
模拟實驗設計比較新穎,但去偏方法稍顯粗糙,缺乏真實資料集的實驗驗證。
Authors: Ziwei Zhu, Yun He, Xing Zhao, James Caverlee
KDD'21 Texas A&M University
論文連結:http://people.tamu.edu/~zhuziwei/pubs/Ziwei_KDD_2021.pdf
本文連結:https://www.cnblogs.com/zihaojun/p/15721359.html
目錄
Popularity Bias in Dynamic Recommendation
0. 總結
1. 問題背景
2. 本文貢獻點
3. 問題定義
3.1 動态推薦
3.2 流行度偏差
4. 實驗分析
4.1 實驗設計
4.2 流行度偏差的變化情況
4.3 四種因素對流行度偏差的影響
4.3.1 position bias
4.3.2 Closed Feedback Loop(CFL)
4.3.3 Model Bias
4.3.4 Inherent Audience Size Imbalance
4.3.5 總結
4.4 兩種負采樣政策的比較
5. 去偏方法
5.1 動态調整debias強度
5.2 利用曝光未點選資料
6. 實驗
Weakness
流行度偏差是推薦系統中長期存在的一種問題,它是指推薦系統更傾向于推薦流行的物品,導緻推薦結果中流行物品的占比過高,産生馬太效應,不利于推薦結果的個性化和多樣化,同時損害使用者體驗和商家的利益。
現有關于流行度偏差的工作都将物品的流行度視為靜态的,但是物品的流行度是會随着時間發生很大變化的。尤其是在推薦這種閉環場景下,推薦結果會影響使用者點選,而使用者點選又會作為訓練資料影響推薦模型。如圖一所示,在這個循環過程中,有以下四個因素影響物品流行度:
潛在的使用者群體規模:即使推薦結果是完全沒有流行度偏差的,使用者的點選也肯定不是均勻的,有些物品就是更受歡迎一些,這是物品本身的品質等差異導緻的。
模型偏差:推薦系統本身會放大這種流行度差異,即推薦結果中,流行物品的比例比訓練資料中更高。
位置偏差:推薦結果的展示順序也會影響物品流行度,排在前面的更容易被點選到。(這個仿佛也是推薦系統本身的行為,感覺可以歸為模型偏差?)
閉環回報效應:由于使用者的點選資料又會作為訓練資料參與模型訓練,這種流行度差異會不斷被放大。
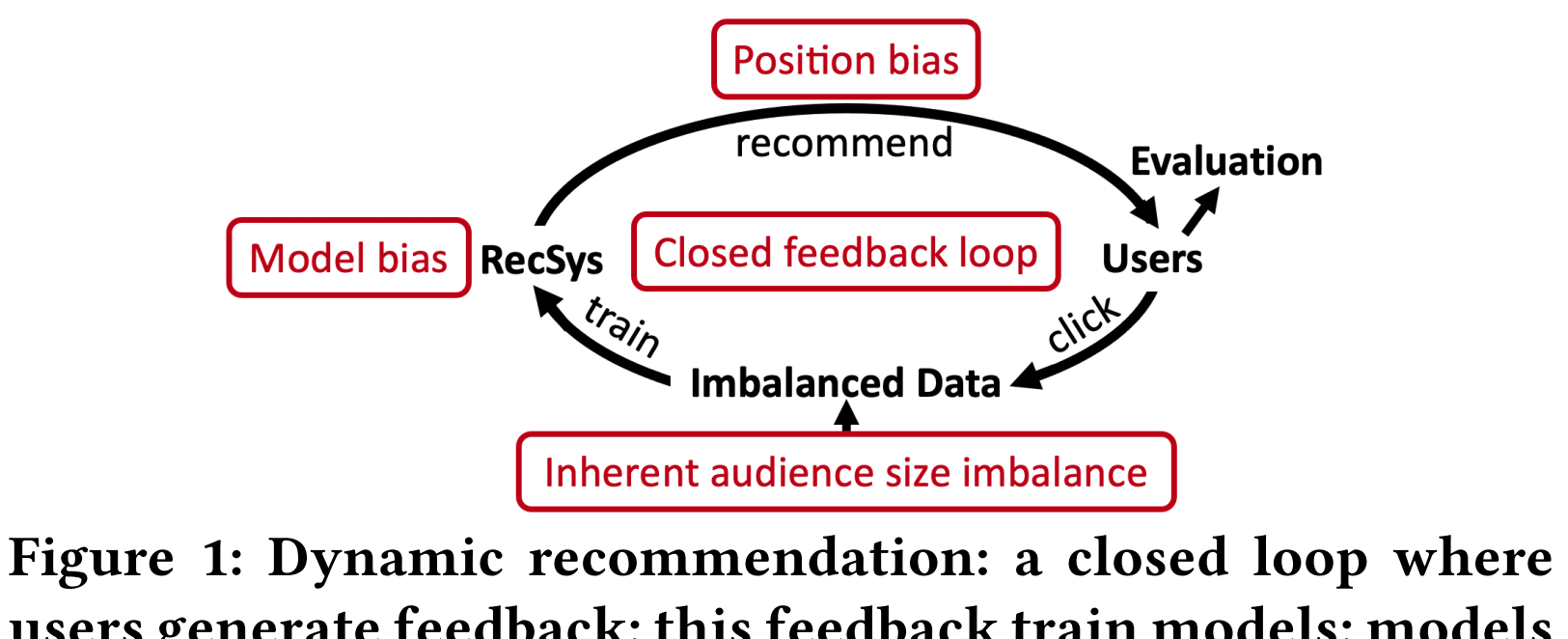
通過模拟實驗,研究了流行度的演變情況,發現潛在使用者群體數量和模型偏差是導緻流行度變化的最重要因素。
提出了解決動态流行度偏差的方法,包括将靜态流行度偏差方法應用到動态場景和一個模型無關的僞正樣本糾正算法,可以被整合進其他debias方法,進一步提高性能。
實驗證明了本文提出方法的有效性。
動态推薦是指,在一個推薦平台上,每當一個使用者登陸上來,都會給出個性化的長度為K的推薦清單,使用者會從中選擇自己喜歡的物品進行互動。每當收集L個使用者的互動之後,推薦系統就會重新訓練,以利用最新的互動資料做出更好的推薦結果。
通常,衡量推薦結果的流行度偏差是基于推薦次數的,但本文采用流行度-機會偏差的定義,即衡量不同流行度物品得到的點選機會是否平等。這種定義會考慮物品本身品質不同帶來的使用者潛在群體規模不同,這樣不會像傳統的定義一樣,強行把不同物品的推薦次數拉平,不考慮使用者規模不同。
本文用True positive rate(TPR)和audience size之間的基尼系數來衡量推薦系統的popularity bias,其中\(TPR_i = C_i^t/A_i\),\(C_i^t\)表示物品i在t時刻被點選的次數,\(A_i\)表示物品i的潛在使用者群體規模。
這個TPR可以了解為,喜歡每個物品的使用者,被推薦到這個物品的幾率是否是一緻的。從後文中Figure 4可以看出,喜歡流行物品的使用者基本都得到了推薦,而喜歡小衆物品的使用者很少會得到推薦。也就是說,流行物品店TPR很高,冷門物品的TPR很低,這是不公平的,喜歡小衆物品的使用者更難獲得準确的推薦,商家也難以獲得公平的曝光。
\[Gini_ {t} = \frac {\sum _ {i\in I}(2i-M-1)TPR_ {i}}{M\sum _ {i\in I}TPR_ {i}}
\]
基尼系數的取值範圍在-1到1之間,越接近1,表示使用者規模大的物品獲得的點選機會越多,流行度偏差越大。如果基尼系數為0,則表示基本所有物品獲得的被點選機會是比較均勻的。
為了驗證四種因素對流行度偏差的影響,本文設計了仿真實驗,探究哪種因素影響比較大,有助于針對性地消除流行度偏差。
線上進行重複實驗是不太現實的,本文參照之前的工作,對ML1M和ciao兩個資料集的打分矩陣進行了補全,這樣,每個物品就有一個明确的潛在閱聽人群體。通過計算潛在閱聽人群體人數的基尼系數,可以看出item之間,閱聽人人數差異還是比較大的(分别達到了0.64和0.44)。
為了研究閱聽人人數差異程度對流行度偏差的影響,本文通過改變生成機制,得到了四種差異程度不同的補全矩陣。

仿真實驗設計:
通過推薦模型,給目前使用者\(u_t\)推薦K個物品
使用者在其中點選自己感興趣的物品,互動記錄回報給系統
重複1-2 L步,然後使用點選資料重新訓練推薦模型。
重複1-3 ,直到推薦T次
實驗中,取\(K = 20, L = 50, T = 40,000\)。負采樣是從推薦但未點選的物品中采樣的。
為了模拟position bias帶來的影響,使用一種降級方法,使得排在前面的被點選的機率較大。
使用MF、popular、random三種政策給出推薦結果,并統計累積點選數量和點選機會的基尼系數。點選數量可以反映推薦的準确度,基尼系數可以反映系統的流行度偏差。
可以看出,MF的推薦精度最高,Random得到的點選數量會線性增長,而popular政策産生的點選很快便達到瓶頸,不再提升。
基尼系數:
popular的基尼系數最高,接近1。這是因為隻推薦了最流行的物品,不流行的物品幾乎沒有被點選的機會。
MF的基尼系數也迅速上升到了很高的水準,比較出乎意料。這說明設計方法來消除推薦系統中的流行度偏差是非常重要的。
Random的基尼系數基本為0,對流行物品和不流行物品平等對待,大家的機會差不多。
将不同物品的TPR可視化,可以看出,TPR呈現長尾分布,大多數物品很少有機會可以被推薦給喜歡它的使用者。
通過在MF的訓練過程中使用IPS去偏算法,去除position bias對推薦模型帶來的影響,實驗結果如下:
去除position bias之後(藍色線),點選數量提高了,基尼系數降低了,說明position bias的存在會影響推薦精度,也會加強popularity bias。不過基尼系數隻下降了一點點,說明position bias不是造成popularity bias的主要因素。
回報閉環是指,目前推薦系統的推薦結果會影響使用者點選行為,進而影響未來推薦系統的訓練。
為了打破這個閉環,我們不能用推薦系統給出的推薦清單産生的點選資料作為訓練資料,而應該另外給一組随機曝光,并使用随機曝光産生的使用者點選資料來訓練推薦系統。
結果表明,去除CFL之後,基尼系數上升速度明顯變慢,但最終還是會逼近甚至超過有閉環回報的系統。是以,閉環回報也會帶來popularity bias,但也不是主要因素。
在Figure 6中,去除了position bias和CFL之後,系統中的popularity bias仍然很嚴重,這說明,剩下的兩個因素,即Model Bias和inherent audience size才是産生popularity bias的主要因素。
為了研究不同實驗設定對Model Bias的影響,這部分設計了兩組靜态實驗:
第一組,生成了五種不同的半合成補全矩陣\(I_1, I_2, I_3, I_4, I_5\),這五個矩陣中,物品的潛在閱聽人群體不平衡性不同,不同物品的閱聽人人數的基尼系數分别為0.37,0.45,0.51,0.57,0.64。
第一組的實驗結果見Figure 7左圖。随着閱聽人人數基尼系數上升,推薦結果的機會基尼系數也會上升,而且機會基尼系數遠高于閱聽人人數的基尼系數。這說明模型會放大物品直接的不平衡性,帶來嚴重的popularity bias。
第二組,生成8組不同規模的訓練資料,觀測模型推薦結果的popularity bias。
結果如Figure 7右圖所示,可見随着訓練資料量的增大,模型中的流行度偏差先增大,後減小。這可能是因為,随着資料規模的增大,模型中的bias和以及預測使用者興趣的能力都在增強。當規模超過一個門檻值時,預測使用者興趣的能力超過了模型bias增大的速度,使得系統popularity bias可以降低一點。
使用4.3.3所述的五種不同Imbalance程度的半合成ground truth,觀察随着動态推薦過程,不同程度的Imbalance對推薦精度和系統bias的影響。
Figure 8所示的結果表明,更高的Imbalance會使得推薦模型有更高的推薦準确率,同時,推薦系統的popularity bias也越嚴重。這是因為Imbalance越強,推薦越簡單——隻推流行的物品就可以收獲很多點選。
model bias和inherent audience size imbalance是産生popularity bias的最重要的兩個因素,另外兩個因素也會加強popularity bias,但影響不是很大。
另外,作者還發現,訓練資料越稠密,audience size imbalance越嚴重,則model bias就越嚴重。
本文的負采樣是在曝光未點選的資料上進行的,這種負采樣是不太常用的,一方面是缺乏曝光資料,另一方面,曝光未點選不一定能說明使用者就不喜歡,可能是因為使用者想看,但突然有事沒來得及,或者同時有好幾個想看的,沒來得及都看完。而在仿真實驗中,這些情況都不存在了,是以可以放心使用曝光未點選資料作為負樣本。
這部分,作者對随機負采樣(VanillaNS)和上述負采樣方法(BetterNS)做了比較。結果顯示,BetterNS政策得到的點選數更高,基尼指數明顯更低。
這是因為,BetterNS政策下,曝光未點選的物品會作為負樣本,而這些負樣本中,流行的物品占比會比較高。也就是說,流行的物品更容易作為負樣本,是以可以起到去除一些popularity bias的效果。也正是因為如此:
在MF的訓練過程中,基尼系數在達到峰值之後緩慢下降。
Figure 6中,ML1M上without feedback loop的方法的popularity bias最終超過了with feedback loop的方法。
w/o CFL的方法使用随機推薦政策産生的互動資料進行訓練,在這種資料上負采樣起不到抵消popularity bias的效果,是以隻剩下随着資料規模增大,popularity bias上升(後下降,見Figure 7 右圖)的效應。
一開始,模型沒訓練的時候,是沒有bias的。随着資料的增多,模型帶來的bias越來越大。是以,在動态推薦場景下,應該逐漸增加debias的強度。
靜态的debias方法一般都有這種超參數
如果一個物品i之前被推薦給了使用者u,但是沒有被點選,則應該降低後面再次被推薦的機率。
實驗也是采用前面一直在使用的仿真動态實驗設定,實驗驗證了提出的兩種方法加到現有的debias方法之後,可以提高推薦精度,降低系統中的popularity bias。
以下是個人見解,如有不妥之處還請不吝指出,歡迎大家一起讨論。
4.3.3 應該分析model bias對系統中popularity bias的影響,但是有點跑題了,變成了分析什麼因素會影響model bias。這部分應該分析model是如何放大了audience size本身帶來的bias,或者如何放大了訓練資料中的popularity bias。
4.3.3 可以考慮用沒有audience size imbalance的模拟使用者來做一下實驗,這樣就可以去除audience size imbalance的影響,隻看model如何産生popularity bias。
4.3.1 去除系統中的position bias,用的是在模型訓練時加IPS的方法。既然已經是模拟實驗了,完全可以把模拟實驗中,産生position bias的機制去掉,這樣可以完全去除position bias帶來的影響。加IPS畢竟是間接的方法,不一定去除的幹淨。
5.1提出的方法在實際場景下是不怎麼适用的,因為訓練資料雖然在不斷增加,但是初始的資料量就很大,不存在一點點累積起來的情況。
5.2提出的方法在實際的曝光未點選資料上不一定有這樣的效果,即本文缺乏真實資料集的實驗,都是在用模拟實驗驗證方法,而模拟場景和真實場景差别較大。