一、基本概念與模型
1、大資料
結構化資料:有嚴格定義
半結構化資料:html、json、xml等,有結構但沒有限制的文檔
非結構化資料:沒有中繼資料,比如說日志類文檔
搜尋引擎:ELK,搜尋元件、索引元件組成,用來搜尋資料,儲存在分布式存儲中
爬蟲程式:搜尋的是半結構化和非結構化資料
需要+高效存儲能力、高效的分析處理平台
2、Hadoop
Hadoop是用Java語言開發的,是對谷歌公司這3篇論文開發出來的山寨版
2003年:The Google File System -->HDFS
2004年:MapReduce:Simplified Data Processing On Large Cluster -->MapReduce
2006年:BigTable:A Distributed Storage System for Structure Data -->Hbase
HDFS+MapReduce=Hadoop
HDFS:Hadoop的分布式檔案系統,有中心節點式存儲資料
MapReduce:面向大資料并行處理的計算模型、架構和平台
HBase:Hadoop的database資料庫
官方網址:hadoop.apache.org
二、HDFS
1、HDFS問題
存在名稱節點:NN:NameNode和第二名稱節點SNN:Secondary NameNode
NN資料存儲在記憶體中,由于資料在記憶體中變化十分快,硬碟存儲跟不上記憶體的變化速度,是以通過類似于資料庫事務日志的機制,向硬碟存儲映像檔案,在此過程中 ,追加日志不斷被清空不斷被寫入,是以當NN伺服器挂了,至少不會丢失太多檔案,但是由于檔案中繼資料在當機後可能有不統一的情況造成檔案校驗,資料量過大會花費大量時間。
SNN為輔助名稱節點,NN的追加日志放到了共享存儲上,使SNN能通路,當NN當機後,SNN會可以根據追加日志及時啟動,至少優化了隻有一個NN時候的檔案校驗時間。
在Hadoop2或者HBase2版本之後,可以将資料共享存放到zookeeper,幾個節點通過zookeeper同時擷取到視圖,很好的解決了剛才的問題,也能夠進行高可用設定了。
2、HDFS資料節點工作原理:
存在資料節點:DN:DataNode
當有資料存儲時,HDFS檔案系統除了存儲DN,會再尋找兩個資料節點進行存儲作為副本,資料節點之間以鍊式相連,即有第一份才有第二份,有第二份才有第三份,每次存儲結束後節點會向前資料點報告,向中繼資料塊或者伺服器報告自己的狀态和資料塊清單。當某一點資料丢失,此時鍊式資料會重新啟動,補足丢失的資料塊。
三、MapReduce
1、JobTracker:作業追蹤器
每一個負責運作作業的節點,在MapReduce裡叫任務追蹤器,TaskTracker
2、每一個節點都要運作兩類程序:
DataNode:負責存儲或者删除資料等資料管理操作
TaskTracker:負責完成隊列處理,屬于Hadoop叢集
3、程式特點
傳統程式方案:程式在哪,資料就加載在哪
Hadoop方案:資料在哪,程式就在哪裡跑
4、Hadoop分布式運作處理架構
任務送出可能會同時由N個人送出N個作業,每個人的作業不一定運作在所有節點上,有可能是在一部分節點上,甚至可能是一個節點上,為了能夠限制一個節點上不要接入過多的任務,是以我們通過task slot,任務槽,來确定一個節點最多隻能運作多少份任務
5、函數式程式設計:MapReduce參考了這種運作機制
Lisp,ML函數式程式設計語言:高階函數
map,fold
map:把一個任務映射為多個任務,把一個函數當作為一個參數,并将其應用于清單中的
所有元素,會生成一個結果清單,即可映射為多個函數。
map(f())
fold:不斷地把得到的結果折疊到函數上,接收兩個參數:函數,初始值。
fold(g(),init):首先結合init初始值,通過函數g()得到g(init)的結果,然後将得到的結果g(init)在第二輪将作為初始值,通過函數g()得到g(g(init))的結果,以此類推最後會得到一個最終結果。
6、MapReduce過程
<1>mapper:每一個mapper就是每一個執行個體,每一個mapper處理完會生成一個清單,相當于map函數的過程,mapper接收資料如果是鍵值資料則直接使用,如果不是鍵值資料會先轉換為鍵值資料
<2>reducer:當所有mapper運作完以後才會進行reducer,相當于fold函數的過程,reducer可能不止一個,reducer隻處理鍵值型資料,接收到的資料做折疊
<3>reducer在折疊後的資料依舊是鍵值型資料,折疊過程叫做shuttle and sort,此過程十分重要
便于了解:同濟一本書每個單詞出現的次數:
mapper:每100頁一個機關,比如說5 mappers,用于拆分成為單詞,比如說this 1,is 1,this 1,how 1,單詞逐個拆分,mapper處理後的為k-v型資料
reducer:reducer隻處理鍵值型資料,将拆分出來的單詞傳遞進reducer中進行統計處理與排序,将鍵相同的資料發往同一個reducer中,最後的結果this 500,is 200等等,結果依舊為kv型資料
shuffle and sort:接收mapper後,reducer将單詞出現的次數進行鍵值資料統計計算的過程叫做shuffle and sort
7、Hadoop資料圖
Hadoop隻提供了資料存儲平台,任何作業、任何資料程式處理必須由Hadoop開發人員寫MapReduce程式調用才可供使用,mapper的具體任務是什麼,reducer用什麼,都取決于開發人員的定義是什麼。
(1)partitioner:分區器,具備決定将mapper鍵值通過shuffle and sort過程發送給哪個reducer的功能
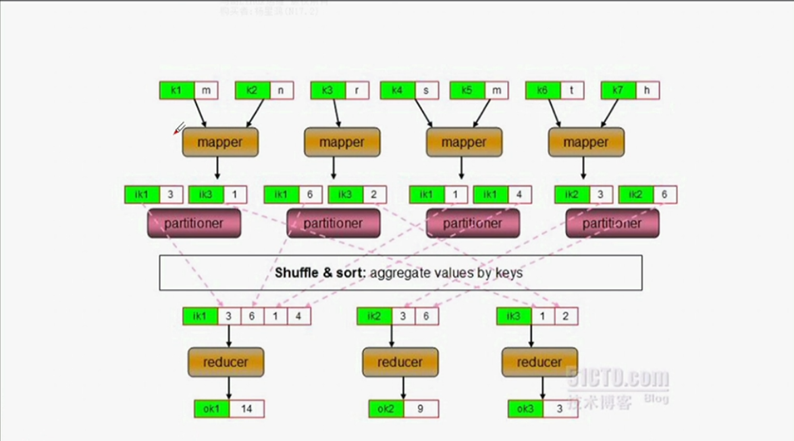
(2)combiner:如果mapper産生的鍵值資料中的鍵相同,那麼将合并鍵,否則不合并,分散發送,同樣由hadoop開發人員開發。其輸入鍵和輸出鍵必須保證一緻。

(3)多個reduce時:
sort:每一個map在本地排序叫做sort
(4)單個reduce時:
(5)shuffle and sort階段:
(6)作業送出請求過程:
(7)JobTracker内部結構
作用:作業排程、管理監控等等,是以運作時JobTracker會非常繁忙,它由此也成為了性能瓶頸,不過在MRv2版本後,作業排程、管理和監控功能被切割
(8)版本更疊
MRv1(Hadoop2) --> MRv2(Hadoop2)
MRv1:叢集資料總管、資料處理程式
MRv2:
YARN:叢集資料總管
MRv2:資料處理程式
Tez:執行引擎
MR:批處理作業
RT Stream Graph:實時流式圖處理,圖狀算法資料結構
(9)第二代hadoop資源任務運作流程
mapreduce把 資源管理和任務運作二者隔離開了,程式運作由自己的Application Master負責,而資源配置設定由Resource Manager進行。是以當一個用戶端送出一個任務時,Resource Manager會詢問每一個Node Manager有沒有空閑的容器來運作程式。如果有,它去找有的這個節點,來啟動這個主要程序Application Master。然後App Mstr向Resource Manager申請資源任務,Resource Manager配置設定好資源任務後會告訴App Mstr,之後App Mstr可以使用contrainer來運作作業了。
每一個container在運作過程中都會将回報自己的作業任務給App Mstr,當container中有任務結束了,App Mstr也會報告給Resource Manager,Resource Manager會将資源收回來
RM:Resource Manager
NM:Node Manager
AM:Application Manager