線上預覽:https://github.lesschina.com/python/base/concurrency/3.并發程式設計-線程篇.html
示例代碼:https://github.com/lotapp/BaseCode/tree/master/python/5.concurrent/Thread
終于說道線程了,心酸啊,程序還有點東西下次接着聊,這周4天外出,是以注定發文少了<code>+_+</code>
用過Java或者Net的重點都線上程這塊,Python的重點其實在上篇,但線程自有其獨到之處~比如資源共享(更輕量級)
這次采用循序漸進的方式講解,<code>先使用,再深入,然後擴充,最後來個案例</code>,呃.呃.呃.先這樣計劃~歡迎糾正錯誤
官方文檔:https://docs.python.org/3/library/threading.html
程序是由若幹線程組成的(一個程序至少有一個線程)
用法和<code>Process</code>差不多,咱先看個案例:<code>Thread(target=test, args=(i, ))</code>
輸出:(同一個程序ID)
注意一點:Python裡面的線程是Posix Thread
如果想給線程設定一個Div的名字呢?:
輸出:(你指定有特點的名字,沒指定就使用預設指令【聯想古時候奴隸名字都是編号,主人賜名就有名了】)
類的方式建立線程
輸出:(和Thread初始化的name沖突了【變量名得注意哦】)
輸出:
對上面代碼,項目裡面一般都會這麼優化:(并行這塊線程後面會講,不急)
代碼改動很小(循環換成了map)性能提升很明顯(密集型操作)
Thread初始化參數:
daemon:是否為背景線程(主線程退出後,背景線程就退出了)
Thread執行個體對象的方法:
isAlive(): 傳回線程是否活動的
getName(): 傳回線程名
setName(): 設定線程名
isDaemon():是否為背景線程
setDaemon(True):設定背景線程
threading子產品提供的一些方法:
threading.currentThread(): 傳回目前的線程執行個體
threading.enumerate(): 傳回一個包含正在運作的線程List(線程啟動後、結束前)
threading.activeCount(): 傳回正在運作的線程數量,與len(threading.enumerate())有相同的結果
看一個小案例:
下次就以<code>multiprocessing.dummy</code>子產品為例了,API和<code>threading</code>幾乎一樣,進行了一些并發的封裝,成本效益更高
其實以前的<code>Linux中</code>是沒有線程這個概念的,<code>Windows</code>程式員經常使用線程,這一看~友善啊,然後可能是當時程式員偷懶了,就把程序子產品改了改(這就是為什麼之前說Linux下的多程序程式設計其實沒有Win下那麼“重量級”),弄了個精簡版程序==><code>線程</code>(核心是分不出<code>程序和線程</code>的,反正<code>PCB</code>個數都是一樣)
多線程和多程序最大的不同在于,多程序中,同一個變量,各自有一份拷貝存在于每個程序中,互不影響,而多線程中,所有變量都由所有線程共享(全局變量和堆 ==> 線程間共享。程序的棧 ==> 線程平分而獨占)
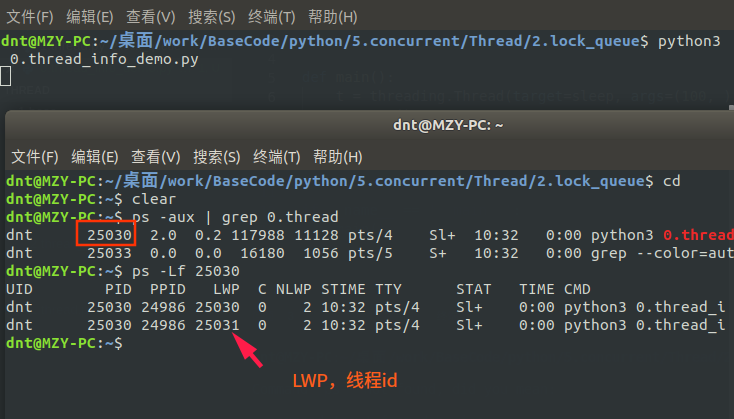
還記得通過<code>current_thread()</code>擷取的線程資訊嗎?難道線程也沒個id啥的?一起看看:(通過<code>ps -Lf pid 來檢視LWP</code>)
回顧:程序共享的内容:(回顧:http://www.cnblogs.com/dotnetcrazy/p/9363810.html)
代碼(.text)
檔案描述符(fd)
記憶體映射(mmap)
線程之間共享資料的确友善,但是也容易出現資料混亂的現象,來看個例子:
輸出:(應該是<code>500000</code>,發生了資料混亂,隻剩下<code>358615</code>)
<code>共享資源+CPU排程==>資料混亂==解決==>線程同步</code> 這時候<code>Lock</code>就該上場了
互斥鎖是實作線程同步最簡單的一種方式,讀寫都加鎖(讀寫都會串行)
先看看上面例子怎麼解決調:
輸出:<code>time python3 1.thread.2.py</code>
lock設定為全局或者局部,性能幾乎一樣。循環換成map後性能有所提升(測試案例在Code中)
<code>time python3 1.thread.2.py</code>
本來多線程通路共享資源的時候可以并行,加鎖後就部分串行了(沒擷取到的線程就阻塞等了)
【項目中可以多次加鎖,每次加鎖隻對修改部分加(盡量少的代碼) 】(以後會說協程和Actor模型)
補充:以前都是這麼寫的,現在支援<code>with</code>托管了(有時候還會用到,是以了解下):【net是直接<code>lock大括号包起來</code>】
擴充知識:(GIL在擴充篇會詳說)
GIL的作用:多線程情況下必須存在資源的競争,GIL是為了保證在解釋器級别的線程唯一使用共享資源(cpu)。
同步鎖的作用:為了保證解釋器級别下的自己編寫的程式唯一使用共享資源産生了同步鎖
lock.locked():判斷 lock 目前是否上鎖,如果上鎖,傳回True,否則傳回False【上鎖失敗時候的處理】
看個場景:小明欠小張2000,欠小周5000,現在需要同時轉賬給他們:(規定:幾次轉賬加幾次鎖)

小明啥也沒管,直接撸起袖子就寫Code了:(錯誤Code示意)
小明寫完代碼就出去了,這可把小周和小張等急了,打了N個電話來催,小明心想啥情況?
一看代碼楞住了,改了改代碼,輕輕松松把錢轉出去了:
就這麼算了嗎?不不不,不符合小明性格,于是小明研究了下,發現~還有個遞歸鎖<code>RLock</code>呢,正好解決他的問題:
RLock内部維護着一個<code>Lock和一個counter</code>變量,<code>counter記錄了acquire</code>的次數,進而使得資源可以被多次<code>require</code>。直到一個線程所有的<code>acquire都被release</code>,其他的線程才能獲得資源
小明想到了之前說的(互斥鎖<code>Lock</code>讀寫都加鎖)就把代碼拆分研究了下:
輸出發現:(第二次加鎖的時候,變成阻塞等了【死鎖】)
這種方式,Python提供的RLock就可以解決了
看個場景:小明和小張需要流水帳,經常互刷~<code>小明給小張轉賬1000,小張給小明轉賬1000</code>
一般來說,有幾個共享資源就加幾把鎖(小張、小明就是兩個共享資源,是以需要兩把<code>Lock</code>)
先描述下然後再看代碼:
正常流程 小明給小張轉1000:小明自己先加個鎖==>小明-1000==>擷取小張的鎖==>小張+1000==>轉賬完畢
死鎖情況 小明給小張轉1000:小明自己先加個鎖==>小明-1000==>準備擷取小張的鎖。可是這時候小張準備轉賬給小明,已經把自己的鎖擷取了,在等小明的鎖(兩個人互相等,于是就一直死鎖了)
代碼模拟一下過程:
輸出:(卡在這邊了)
項目中像這類的情況,一般都是這幾種解決方法:(還有其他解決方案,後面會繼續說)
按指定順序去通路共享資源
trylock的重試機制(<code>Lock(False)</code>)
在通路其他鎖的時候,先把自己鎖解了
得不到全部鎖就先放棄已經擷取的資源
比如上面的情況,我們如果規定,不管是誰先轉賬,先從小明開始,然後再小張,那麼就沒問題了。或者誰錢多就誰(權重高的優先)
PS:<code>lock.locked()</code>:判斷 lock 目前是否上鎖,如果上鎖,傳回True,否則傳回False【上鎖失敗時候的處理】
條件變量一般都不是鎖,能阻塞線程,進而減少不必要的競争,Python内置了<code>RLock</code>(不指定就是RLock)
看看源碼:
再看看可不可以進行with托管:(支援)
看個生産消費者的簡單例子:(生産完就通知消費者)
輸出:(list之類的雖然可以不加global标示,但是為了後期維護友善,建議加上)
通知方法:
notify() :發出資源可用的信号,喚醒任意一條因 wait()阻塞的程序
notifyAll() :發出資源可用信号,喚醒所有因wait()阻塞的程序
記得當時在分析<code>multiprocessing.Queue</code>源碼的時候,有提到過(點我回顧)
同程序的一樣,<code>semaphore</code>管理一個内置的計數器,每當調用<code>acquire()</code>時内置函數<code>-1</code>,每當調用<code>release()</code>時内置函數<code>+1</code>
通俗講就是:在互斥鎖的基礎上封裝了下,實作一定程度的并行
舉個例子,以前使用互斥鎖的時候:(廁所就一個坑位,必須等裡面的人出來才能讓另一個人上廁所)
使用信号量之後:廁所坑位增加到5個(自己指定),這樣可以5個人一起上廁所了==>實作了一定程度的并發
舉個例子:(Python在文法這點特别爽,不用你記太多異同,功能差不多基本上代碼也就差不多)
可能看了上節回顧的會疑惑:源碼裡面明明是<code>BoundedSemaphore</code>,搞啥呢?
其實<code>BoundedSemaphore</code>就比<code>Semaphore</code>多了個在調用<code>release()</code>時檢查計數器的值是否超過了計數器的初始值,如果超過了将抛出一個異常
以上一個案例說事:你換成<code>BoundedSemaphore</code>和上面效果一樣==><code>sem = BoundedSemaphore(5)</code>
之前有人問<code>Semaphore</code>信号量在項目中有什麼應用?<code>(⊙o⊙)…額</code>,這個其實從概念就推出場景了,控制并發嘛~舉個例子:
比如說我們調用免費API的時候經常看見機關時間内限制并發數在30以内,想高并發==>給錢<code>( ⊙ o ⊙ )捂臉</code>
再比如我們去爬資料的時候控制一下爬蟲的并發數(<code>避免觸發反爬蟲的一種方式</code>,其他部分後面會逐漸引入)
這些虛的說完了,來個控制并發數的案例,然後咱們就繼續并發程式設計的衍生了:
輸出圖示:
運作分析:
性能全圖:
在多線程程式中,死鎖問題很大一部分是由于線程同時擷取多個鎖造成的,eg:一個線程擷取了第一個鎖,然後在擷取第二個鎖的 時候發生阻塞,那麼這個線程就可能阻塞其他線程的執行,進而導緻整個程式假死。
解決死鎖問題的一種方案是為程式中的每一個鎖配置設定一個唯一的id,然後隻允許按照升序規則來使用多個鎖,當時舉了個小明小張轉賬的簡單例子,來避免死鎖,這次咱們再看一個案例:(這個規則使用上下文管理器非常簡單)
先看看源碼,咱們怎麼使用:
翻譯成代碼就是這樣了:(簡化)
基礎忘記了可以點我(lambda)
以上面小明小張轉賬案例為例子:(不用再管鎖順序之類的了,直接全部丢進去:<code>with lock_manager(...)</code>)
再來個驗證,在他們互刷的過程中,小潘還了1000元給小明
先看看場景:五個外國哲學家到中國來吃飯了,因為不了解行情,每個人隻拿了一雙筷子,然後點了一大份的面。礙于面子,他們不想再去拿筷子了,于是就想通過腦子來解決這個問題。
每個哲學家吃面都是需要兩隻筷子的,這樣問題就來了:(隻能拿自己兩手邊的筷子)
如果大家都是先拿自己筷子,再去搶别人的筷子,那麼就都等着餓死了(死鎖)
如果有一個人打破這個正常,先拿别人的筷子再拿自己的,那麼肯定有一個人可以吃到面了
5個筷子,意味着最好的情況 ==> 同一時刻有2人在吃(0人,1人,2人)
把現實問題轉換成代碼就是:
哲學家--線程
筷子--資源(幾個資源對應幾把鎖)
吃完一口面就放下筷子--lock的釋放
有了上面基礎這個就簡單了,使用死鎖避免機制解決哲學家就餐問題的實作:(不用再操心鎖順序了)
PS:這個一般都是作業系統的算法,了解下就可以了,上面哲學家吃面用的更多一點(歡迎投稿~)
我們可以把作業系統看作是銀行家,作業系統管理的資源相當于銀行家管理的資金,程序向作業系統請求配置設定資源相當于使用者向銀行家貸款。 為保證資金的安全,銀行家規定:
當一個顧客對資金的最大需求量不超過銀行家現有的資金時就可接納該顧客;
顧客可以分期貸款,但貸款的總數不能超過最大需求量;
當銀行家現有的資金不能滿足顧客尚需的貸款數額時,對顧客的貸款可推遲支付,但總能使顧客在有限的時間裡得到貸款;
當顧客得到所需的全部資金後,一定能在有限的時間裡歸還所有的資金.
作業系統按照銀行家制定的規則為程序配置設定資源,當程序首次申請資源時,要測試該程序對資源的最大需求量,如果系統現存的資源可以滿足它的最大需求量則按目前的申請量配置設定資源,否則就推遲配置設定。當程序在執行中繼續申請資源時,先測試該程序本次申請的資源數是否超過了該資源所剩餘的總量。若超過則拒絕配置設定資源,若能滿足則按目前的申請量配置設定資源,否則也要推遲配置設定。
通俗講就是:當一個程序申請使用資源的時候,銀行家算法通過先試探配置設定給該程序資源,然後通過安全性算法判斷配置設定後的系統是否處于安全狀态,若不安全則試探配置設定廢棄,讓該程序繼續等待。
參考連結:
Python裡面沒找到讀寫鎖,這個應用場景也是有的,先簡單說說這個概念,你可以結合<code>RLock</code>實作讀寫鎖(了解下,用到再研究)
讀寫鎖(一把鎖):
讀共享:A加讀鎖,B、C想要加讀鎖==>成功(并行操作)
寫獨占:A加寫鎖,B、C想要讀(寫)==>阻塞等
讀寫不能同時(寫優先級高):A讀,B要寫,C要讀,D要寫==>A讀了,B在寫,C等B寫完讀,D等C讀完寫(讀寫不能同時進行)
擴充參考:
http://xiaorui.cc/?p=2384
https://www.jb51.net/article/82999.htm
https://blog.csdn.net/11b202/article/details/11478635
https://blog.csdn.net/vcbin/article/details/51181121
上次說了鎖相關,把問題稍微彙聚提煉一下~重點在思想,語言無差别
正常執行線程任務沒什麼好說的,可以通過<code>isAlive</code>判斷目前線程狀态,對于耗時操作可以設定逾時時間<code>t.join(timeout=1)</code>+重試機制
但是背景線程<code>Thread(daemon=True)</code>就沒那麼好控制了:這些線程會在主線程終止時自動銷毀。除了如上所示的兩個操作,并沒有太多可以對線程做的事情(無法結束一個線程,無法給它發送信号,無法調整它的排程,也無法執行其他進階操作)
比如說,如果你需要在不終止主線程的情況下殺死線程,那麼這個線程就不能通過<code>daemon</code>的方式了,必須通過程式設計在某個特定點輪詢來退出:
輸出:(再提醒一下,輪循必須根據業務來,不管是重試機制還是其他,這邊隻是舉個例子)
上面這種方式,比較好了解,但是比較依賴<code>threading.Thread</code>,項目裡面一般這麼改下:
輸出:(<code>ShutdownTask</code>就解耦了,不依賴<code>threading</code>庫了,你放在程序中使用也沒事了)
是不是心想着現在都妥妥的了?但是遺憾的是~如果遇到了IO阻塞的情況,輪循形同虛設,這時候就需要逾時時間來解決了:
join(timeout)是一種方式
socket的逾時機制也是一種方式(後面會探讨)
僞代碼實作:(加上重試機制更完善)
由于全局解釋鎖(GIL)的原因,Python 的線程被限制到同一時刻隻允許一個線程執行這樣一個執行模型。是以,Python 的線程更适用于處理I/O和其他需要并發執行的阻塞操作(比如等待I/O、等待從資料庫擷取資料等等),而不是需要多處理器并行的計算密集型任務。【這也是為什麼我說Python和其他語言并發程式設計的重點不一樣:<code>程序+協程</code>】
Python程序<code>Process</code>可以通過:<code>terminate()</code> or <code>signal</code>的方式終止:(點我回顧)
<code>terminate</code>聯合<code>signal</code>進行退出前處理:
還有一種方式,通過程序間狀态共享(點我回顧),實作優雅的退出子程序
這塊上面說很多了,再介紹幾種:
CAS原子類(Java比較常用)
Thread Local(常用場景:存各種的連接配接池)
Lock,互斥鎖,可重入鎖(遞歸鎖),信号量,條件變量(上面都在說這些)
在多線程環境下,每個線程都有自己的資料,想要互不幹擾又不想定義成局部變量傳來傳去,怎麼辦?
一開始是這麼解決的:
但這麼搞也很麻煩,于是就有了<code>ThreadLocal</code>:
輸出:(同樣存的是name屬性,不同線程間互不影響)
再來談談常用的兩種死鎖解決思路:(這次不僅僅局限在<code>Python</code>了)
"順序鎖"
<code>tryLock</code>
說說順序鎖的算法:<code>hash Sort</code>(3種情況),先看看幾種hash的對比吧:
In [1]:
In [2]:
In [3]:
In [4]:
如果是一般的順序死鎖,那麼程式代碼改改邏輯基本上就可以避免了。比如調試的時候就知曉,或者借助類似于<code>jstack</code> or 開發工具檢視:
怕就怕在動态上==>舉個例子:(還是小明小張互刷的案例)
有人實踐後很多疑問,說明明我就按照順序加鎖了啊,先加轉出賬号,再加鎖轉入賬号?
其實...換位思考就懂了==>僞代碼
這個雖然按照了所謂的順序,但是轉帳人其實在變,也就變成了動态的,是以也會出現死鎖:
輸出:(死鎖了,聯想哲學家吃面~每個人先拿自己的筷子再搶人的筷子)
解決方案~僞代碼思路:
完整Python代碼示意:
<code>Python</code>上下文管理器我就不說了,上面說過了,思路和“順序鎖”基本一樣:
大家都聽說過死鎖deadlock,但是很少有人聽說過活鎖livelock。活鎖主要由兩個線程過度謙讓造成,兩個線程都想讓對方先幹話,結果反而都無法繼續執行下去。因為兩個線程都在活躍狀态,故稱活鎖。
<code>trylock</code>可以解決死鎖問題,但是用不好也會出現少見的活鎖問題:
輸出:(沒有<code>sleep(random()) # 随機睡[0,1)s</code>就是一個活鎖了)
可以思考一下,為什麼<code>trylock</code>的時候<code>p_from.money -= money</code>和<code>p_to.money += money</code>都要放在code最裡面
線程同步這塊,之前講了鎖系列,現在把剩下的也說說
Queue大家都很熟悉,應用場景很多很多,不僅僅局限線上(進)程同步,很多業務場景都在使用。
在開始之前先看一個秒殺場景:一般都使用樂觀鎖,也就是大家經常提的CAS機制來實作,資料所在的記憶體值,預期值,新值。當需要更新時,判斷目前記憶體值與之前取到的值是否相等,若相等,則用新值更新,若失敗則不斷重試(<code>sleep(random)</code>)
從資料庫層面控制就是這樣:(原子性操作)
我們用代碼模拟一下:(Python裡面沒有<code>CountDownLatch</code>,我們用之前學的條件變量實作一個)
模拟:
輸出:(沒錯,沒用鎖一樣高并發~)
如果你把<code>if count > 0:</code>注釋掉:(瞬間呵呵哒了)
如果你在修改的時候加個鎖:
在這裡說,其實沒有多大意義,了解下即可(資料庫最大連接配接數是有瓶頸的,後端項目裡面一般都是使用緩存的<code>CAS機制</code>,比如<code>Redis</code>的<code>watch</code>、<code>memcached</code>的<code>gets</code>和<code>cas</code>,還有就是我們下面要介紹的<code>Queue</code>了)
後面會說,引入部分不用深究,記住兩個即可:
資料庫層面的CAS機制(樂觀鎖)
Java裡面<code>CountDownLatch</code>的模拟
Queue在講程序的時候就有說過(程序間通信),線程用法也差不多,看個經典案例:
輸出圖示:(非阻塞可以使用<code>put_nowait</code>和<code>get_nowait</code>)
Queue是線程安全的放心使用,我們來看看Queue源碼:(條件變量<code>Condition</code>和<code>Lock</code>的綜合使用)
來個場景,廠家倒閉(任務清單完成了)怎麼通知消費者不用等待了?
回顧一下使用協程是怎麼解決的:協程yield實作多任務排程
當使用<code>Queue</code>時,協調生産者和消費者的關閉問題可以在隊列中放置一個特殊的值,當消費者讀到這個值的時候,終止執行:
如果讀到特殊值沒有再放進隊列就不能保證所有消費者都退出任務~Queue裡面的資料取出來就沒了 輸出:(你可以把上面那句注釋調看結果)
在上面案例裡面,你把<code>uuid.uuid1()</code>換成<code>object()</code>,然後比較部分的<code>==</code>換成<code>is</code>也是可以的,但是分布式系統的話還是使用<code>UUID</code>吧
如果想在<code>Queue</code>的基礎上擴充,可以自定義資料結構并添加所需的鎖和同步機制(eg:<code>Condition</code>)來實作線程間通信(同步)
寫demo前說說理論:
二叉樹 ==> 每個節點最多有兩個子樹的樹結構
滿二叉樹 ==> 除了最底層葉結點外,每一個結點都有左右子葉
二叉堆 ==> 本質上是一種完全二叉樹,它分為兩個類型:
最大堆:最大堆任何一個父節點的值,都大于等于它左右子節點的值,根節點是最大值
最小堆:最小堆任何一個父節點的值,都小于等于它左右子節點的值,根節點是最小值
以最小堆為例,畫個圖示範一下:
插入新節點
排序後的二叉樹
準備删除節點2
把最後一個節點拿過來充數(維護二叉樹穩定)
進行比較排序,把左右節點最小的拉上來
建構二叉堆:把一個無序的完全二叉樹調整為二叉堆(<code>讓所有非葉子節點依次下沉</code>)
來個亂序的二叉樹
從最後一個非葉子節點開始,和最小的子節點交換位置(8和1交換)
右邊的也走一波(6和4交換)
節點5和1互換
現在根節點最小了(3和1互換)
從上往下再排個序,這時候就是最小堆了
看個<code>完全二叉樹</code>的規律:若從上至下、從左至右編号,則編号為i的結點:
左孩子編号為<code>2i+1</code>,其右孩子編号=<code>2i+2</code>
父節點編号=<code>i/2</code>(根節點沒有父節點)
把上面二叉樹轉換成數組:
這時候再去了解優先隊列就簡單了:
最大優先隊列,無論入隊順序,目前最大的元素優先出隊
最小優先隊列,無論入隊順序,目前最小的元素優先出隊
Python提供了一個<code>heapq</code>的子產品:https://docs.python.org/3/library/heapq.html
來看個最小二叉堆的案例:
In [5]:
Out[5]:
In [6]:
Out[6]:
舉個使用<code>Condition</code>+<code>二叉堆</code>實作一個優先級隊列:
<code>multiprocessing.dummy</code>上面隻列舉了常用的子產品,Queue這塊就兩個:<code>Queue</code>和<code>JoinableQueue</code>。既然提到了就順便說幾句,之前寫程序篇的時候因為外出,急急忙忙就收尾了,像上面的<code>Semaphore</code>和<code>Condition</code>以及下面準備說的<code>Event</code>和<code>Barrier</code>等程序和線程都是通用的
如果要是非要找點不同,那麼Queue這塊還真有點不同,eg:<code>Queue</code>裡面沒有<code>task_done</code>和<code>join</code>方法,而<code>JoinableQueue</code>擴充了,而線程的<code>Queue</code>是有<code>task_done</code>和<code>join</code>的,其他常用的程序api和線程基本上一樣,用到的時候查下源碼或者看看官方文檔即可~
程序的<code>Queue</code>與<code>JoinableQueue</code>:
線程的<code>Queue</code>:
<code>threading</code>:
<code>multiprocessing.dummy</code>:
<code>multiprocessing.dummy</code>可以了解為<code>multiprocessing</code>的輕量級并發庫:api基本上和<code>multiprocessing</code>一緻,很多都是在<code>threading</code>的基礎上修改下或者直接使用(<code>multiprocessing</code>在<code>Process</code>基礎上修改)比如:
看看内部實作:(比我們實作的還精簡,秒懂)
看個上面<code>MaxPriorityQueue</code>的案例:(想要大數字優先級高就變負數)
輸出:(如果功能不夠用還是自己設計吧,設計的太簡單調用的時候會比較麻煩)
一看好像很高大上,翻翻源碼:(其實就是基于List封裝了個類,看來<code>multiprocessing.dummy</code>重寫這個是有原因的)
看個使用案例:(完全可以直接使用List...)
<code>SimpleQueue</code> 就不說了,和Queue使用基本上一樣。線程和程序有點不一樣,注意下:(<code>程序間通信手段畢竟比線程少</code>)
<code>threading</code>中的<code>SimpleQueue</code>是<code>FIFO</code>簡單隊列
<code>multiprocessing</code>中的<code>SimpleQueue</code>是在<code>PIPE</code>管道的基礎上封裝版
<code>JoinableQueue</code> 在<code>multiprocessing.dummy</code>就是<code>Queue</code>:(等會直接使用<code>Queue</code>即可)
相關源碼:(下面會和<code>Queue</code>對比舉例)
在<code>multiprocessing</code>中的<code>Queue</code>沒有<code>task_done</code>和<code>join</code>方法,是以有了<code>JoinableQueue</code>:
使用隊列來進行線程間通信是一個單向、不确定的過程。通常情況下,沒法知道接收資料的線程是什麼時候接收到資料并開始工作的。這時候就可以使用<code>Queue</code>提供的<code>task_done()</code>和<code>join()</code>了~
之前通知消費者退出是使用發一個消息的方式,這次換種思路~直接設定背景線(進)程,然後使用<code>Queue</code>的<code>join</code>方法:
程序案例見:/BaseCode/tree/master/python5.concurrent/Thread/2.lock_queue/3.queue/6.JoinableQueue.py
PS:其實Queue的完整寫法應該是每次收到消息的時候調用一下<code>q.task_done()</code>,便于記錄未完成狀态,大家程序的<code>Queue</code>用多了,也就不太寫了。現在<code>task_done</code>講過了,以後用線程的<code>Queue</code>和程序的<code>JoinableQueue</code>記得加上哦~
再擴充一下,看看<code>queue.join</code>源碼:(如果還不清楚,下面還有一個手寫線程池的demo)
Queue對象的方法:
<code>q.full()</code>:判斷隊列是否已滿
<code>q.empty()</code>:判斷隊列是否為空
<code>q.qsize()</code>:傳回目前隊列中的元素個數
<code>q.get_nowait()</code>:非阻塞擷取消息,等價于<code>q.get(block=Flase)</code>
<code>q.put_nowait()</code>:非阻塞發送消息,等價于<code>q.put(block=Flase)</code>
<code>q.join()</code>:等待所有任務完成
<code>q.task_done()</code>:在Queue中标記任務完成
PS:<code>q.qsize()</code>、<code>q.full()</code>、<code>q.empty()</code>等方法可以擷取一個隊列的目前大小和狀态。但要注意,這些方法都不是線程安全的。
可能你對一個隊列使用<code>empty()</code>判斷出這個隊列為空,但同時另外一個線程可能已經向這個隊列中插入一個資料項。是以,你最好不要在你的代碼中使用這些方法。
queue子產品定義的異常類:
<code>queue.Full</code>:非阻塞發送消息時,如果隊列滿了~抛異常
<code>queue.Empty</code>:非阻塞擷取消息時,如果隊列為空~抛異常
eg:
基于簡單隊列編寫多線程程式線上程安全隊列的底層實作來看,你無需在你的代碼中使用鎖和其他底層的同步機制,使用隊列這種基于消息的通信機制可以被擴充到更大的應用範疇,比如,你可以把你的程式放入多個程序甚至是分布式系統而無需改變底層的隊列結構。
使用線程隊列有一個要注意的問題:向隊列中添加資料項時并不會複制此資料項,線程間通信實際上是線上程間傳遞對象引用。如果擔心對象的共享狀态,那最好隻傳遞不可修改的資料結構(如:整型、字元串或者元組)或者一個對象的深拷貝<code>copy.deepcopy(data)</code>
和網絡整合版的線程池後面再說,<code>ThreadPoolExecutor</code>深入篇後會說,先模仿官方<code>Pool</code>來個精簡版:
調用和官方風格一緻:
輸出:(有些偶爾用的子產品可以用的時候再導入【别放循環裡,雖然重複導入子產品不怎麼耗時,但是總歸有損耗的】)
線程的一個關鍵特性是每個線程都是獨立運作且狀态不可預測。如果程式中的其他線程需要通過判斷某個線程的狀态來确定自己下一步的操作,這時線程同步問題就比較麻煩。這時候我們就可以使用<code>Event</code>了~eg:(類比JQ裡面的事件~eg:單擊事件)
常用方法:
<code>event.clear()</code>:恢複event的狀态值為False(并發場景下有大用)
<code>event.wait()</code>:如果<code>event.is_set()==False</code>将阻塞線程
<code>event.set()</code>: 設定<code>event</code>的狀态值為<code>True</code>,所有阻塞池的線程激活進入就緒狀态, 等待作業系統排程
<code>event.is_set()</code>:傳回<code>event</code>的狀态值(如果想非阻塞等可以使用這個先判斷)線程有個重命名的方法叫<code>isSet</code>。PS:程序線程中都有<code>is_set</code>方法
<code>Event</code>對象包含一個可由線程設定的信号标志,它允許線程等待某些事件的發生:
在初始情況下,<code>Event</code>對象中的信号标志被設定為假。等待<code>Event</code>對象的線程将會被一直阻塞至标志為真。
當一個線程将一個<code>Event</code>對象的信号标志設定為真,它将喚醒所有等待這個<code>Event</code>對象的線程。等待<code>Event</code>的線程将忽略這個事件, 繼續執行
再來個簡單版的生産消費者的案例:
輸出:(是不是又感覺多了種消費者安全退出的方式?)
PS:while條件換成:<code>while not (len(global_list) == 0 and stop_event.is_set()):</code>也行
如果一個線程需要在一個“消費者”線程處理完特定的資料項時立即得到通知,你可以把要發送的資料和一個<code>Event</code>一起使用,這樣“生産者”就可以通過這個<code>Event</code>對象來監測處理的過程了
輸出:(程序隻需微微改動即可使用)
來看看<code>Event</code>到底是何方神聖:(本質就是基于<code>Condition</code>封裝了一個辨別位,來标記事件是否完成)
其實應用場景很多,用起來比<code>Condition</code>友善,比如在連接配接遠端資料庫或者通路api的時候設定一個重試機制,成功後再執行SQL或者資料處理:
動态輸出:
利用<code>Pool</code>提供的<code>callback</code>和<code>error_callback</code>:
如果想要簡單的并行并且傳回結果統一處理,可以把:
換成:
輸出:(聯想一條條插入資料和批量插入資料)
先看一個簡單案例:
運作圖示:
咱們看看源碼是怎麼回事:
原來<code>timer</code>是線上程的基礎上封裝了一下。利用<code>Event</code>來标記<code>完成/取消</code>與否,與之前講的定時器不太一樣(點我回顧:Signal信号)
Timer類是Thread的子類。Timers和線程的啟動方式一樣,調用其start()方法。timer可以在動作執行前調用其cancel()取消其執行。imer有點像定時器,啟動一個線程,定時執行某個任務。此外,Timer還可以處理各種逾時情況~比如終結subprocess建立的程序(<code>p.kill()</code>)
再來個定時執行的案例:
輸出:(可以思考比死循環好在哪?提示:<code>wait</code>)
官方文檔:<code>https://docs.python.org/3/library/threading.html#barrier-objects</code>
提供了一個簡單的同步原語(機制),供需要互相等待的固定數量的線程使用。每個線程都試圖通過調用<code>wait()</code>方法來傳遞屏障,并将阻塞直到所有線程都進行了<code>wait()</code>調用。此時,線程同時釋放。
看一個官方案例:(同步用戶端和伺服器線程)
說到這個不得不提一下我們<code>Queue</code>引入篇自己模拟的<code>僞CountDownLatch</code>,兩者異同之處不少,下面貼了參考連結可以課外拓展一下,大體差別是一個是等待線程組且不可重用,另一個是等待多個線程且可重用(<code>Barrier</code>)。有點像跑步比賽,大家都準備好(全都調用了<code>wait</code>),才允許一起跑(執行)【差別無非是一組起跑還是多組起跑】
很顯然,上面那個模拟并發的例子使用<code>Barrier</code>更簡單和應景(也是基于<code>Condition</code>封裝的,比我們封裝的更完美)
輸出:(如果使用<code>Pool</code>,記得指定線程數,不然就給自己挖坑了)
<code>class threading.Barrier(parties, action=None, timeout=None)</code>
<code>parties</code>指定需要等待的線程數
<code>action</code>是一個可調用的,當它被提供時,它們将在它們全部進入屏障之後并且在釋放所有線程之前由其中一個線程調用。
如果提供<code>timeout</code>,則将其用作所有後續<code>wait()</code>調用的預設值
常見方法:
<code>bar.parties</code>:同步的線程數
<code>bar.wait(timeout=None)</code> 等待線程大部隊到齊
<code>bar.reset()</code>:重置Barrier。所有處于等待的線程都會收到<code>BrokenBarrierError</code>異常
<code>bar.abort()</code>:将屏障置于終止狀态。這會導緻調用wait()的線程引發BrokenBarrierError(為了防止某一個程序意外終止,會造成整個程序的死鎖。建議在建立Barrier指定逾時時間)
<code>bar.n_waiting</code>:有多少個線程處于等待狀态
<code>bar.broken</code>:如果屏障處于損壞狀态,則為布爾值為True
參考文章:
什麼都先不說,先看一個對比案例來引入:
Python:
運作後HTOP資訊:<code>python3 1.GIL_Test.py</code>
有人可能會反駁了,這是啥測試,多線程都沒用到怎麼展現多核?不急,再看一個案例:(注意看<code>htop</code>顯示的<code>commad</code>)
看看核心使用情況~乍一看,好像是利用了多核,好好算一下==>加起來差不多就是<code>單核CPU的100%</code>嘛...
來看看為什麼不影響:(改成5)【要想把N核CPU的核心全部跑滿,就必須啟動N個死循環線程】
效果:(還是單核CPU充分利用)
那其他語言是不是也這樣?以<code>NetCore</code>為例:<code>dotnet new console -o testGIL</code>
運作後HTOP資訊:<code>dotnet testGIL.dll</code>
現在Java和Python都在模仿Net的一些優雅新文法,比如異步這塊。如果你用的還是那麼繁瑣低效那真的好好反思一下了
如果記不得Net的知識可以點我回顧:https://www.cnblogs.com/dotnetcrazy/p/9426279.html#NetCore并發程式設計
最常見方法:線程變程序,因為是Linux,程序和線程不像Win那樣性能相差那麼大,其實上面代碼都可以不動,就改一個地方:<code>multiprocessing.dummy</code>=><code>multiprocessing</code>
現在看看效果:
很多人程式設計都隻是利用了單核,對于今天這個多核遍布的時代,着實有點可惜了(自己買的雲伺服器基本上都是1核1G或者1核2G的,程式設計語言性能相差不大,企業用就得深入探讨優化了~)
Code:<code>https://github.com/lotapp/BaseCode/tree/master/python/5.concurrent/Thread/3.GIL</code>
盡管Python完全支援多線程程式設計, 但是解釋器的C語言實作部分在完全并行執行時并不是線程安全的,是以這時候才引入了GIL
解釋器被一個全局解釋器鎖保護着,它確定任何時候都隻有一個Python線程執行(保證C實作部分能線程安全) GIL最大的問題就是Python的多線程程式并不能利用多核CPU的優勢 (比如一個使用了多個線程的計算密集型程式隻會在一個單CPU上面運作)
注意:GIL隻會影響到那些嚴重依賴CPU的程式(比如計算型的)如果你的程式大部分隻會涉及到I/O,比如網絡互動,那麼使用多線程就很合适 ~ 因為它們大部分時間都在等待(線程被限制到同一時刻隻允許一個線程執行這樣一個執行模型。GIL會根據執行的位元組碼行數和時間片來釋放GIL,在遇到IO操作的時候會主動釋放權限給其他線程)
是以Python的線程**更适用于處理`I/O`和其他需要并發執行的阻塞操作,而不是需要多處理器并行的計算密集型任務**(對于IO操作來說,多程序和多線程性能差别不大)【計算密集現在可以用Python的`Ray`架構】
網上摘取一段關于<code>IO密集和計算密集</code>的說明:(IO密集型可以結合異步)
其實用不用多程序看你需求,不要麻木使用,Linux下還好點,Win下程序開銷就有點大了(好在伺服器基本上都是Linux,程式員開發環境也大多Linux了)這邊隻是簡單測了個啟動時間差距就來了,其他的都不用測試了
測試Code:
運作時間:
作業系統幾千個程序開銷還是有點大的(畢竟程序是有上線的)<code>ulimit -a</code>
<code>multiprocessing.dummy</code>裡面的Process上面也說過了,就是線上程基礎上加點東西使得用起來和<code>multiprocessing</code>的<code>Process</code>程式設計風格基本一緻(本質還是線程)
測試Code:
其實Redis就是使用單線程和多程序的經典,它的性能有目共睹。所謂性能無非看個人能否充分發揮罷了。不然就算給你轟炸機你也不會開啊?紮心不老鐵~
PS:線程和程序各有其好處,無需一棍打死,具體啥好處可以回顧之前寫的程序和線程篇~
GIL是Python解釋器設計的曆史遺留問題,多線程程式設計,模型複雜,容易發生沖突,必須用鎖加以隔離,同時,又要小心死鎖的發生。Python解釋器由于設計時有GIL全局鎖,導緻了多線程無法利用多核。計算密集型任務要真正利用多核,除非重寫一個不帶GIL的解釋器(<code>PyPy</code>)如果一定要通過多線程利用多核,可以通過C擴充來實作(Python很多子產品都是用C系列寫的,是以用C擴充也就不那麼奇怪了)
隻要用C系列寫個簡單功能(不需要深入研究高并發),然後使用<code>ctypes</code>導入使用就行了:
編譯成共享庫:<code>gcc 2.test.c -shared -o libtest.so</code>
使用Python運作指定方法:(<code>太友善了,之前一直以為C#調用C系列最友善,用完Python才知道更簡方案</code>)
看看這時候HTOP的資訊:(充分利用多核)【ctypes在調用C時會自動釋放GIL】
利用Go寫個死循環,然後編譯成so動态連結庫(共享庫):
**非常重要的事情:`//export test`一定要寫,不然就被自動改成其他名字(我當時被坑過)**
Python調用和上面一樣:
效果:<code>go build -buildmode=c-shared -o libtestgo.so 2.test.go</code>
題外話~如果想等CPython的GIL消失可以先看一個例子:MySQL把大鎖改成各個小鎖花了5年。在是在MySQL有專門的團隊和公司前提下,而Python完全靠社群重構就太慢了
速度方面微軟除外,更新快本來是好事,但是動不動斷層更新,這學習成本就太大了(這也是為什麼Net能深入的人比較少的原因:人家剛深入一個,你就淘汰一個了...)
可能還有人不清楚,貼下官方推薦技術吧(<code>NetCore</code>、<code>Orleans</code>、<code>EFCore</code>、<code>ML.Net</code>、<code>CoreRT</code>)
課外拓展:
先看最重要的一點,一旦運作在其他編譯器意味着很多Python第三方庫<code>可能</code>就不能用了,相對來說<code>PyPy</code>相容性是最好的了
如果是<code>Python2</code>系列我推薦谷歌的grumpy
如果是<code>Python3</code>系列,可以使用<code>PyPy</code> <code>PythonNet</code> <code>Jython3</code> <code>ironpython3</code>等等
PyPy:https://bitbucket.org/pypy/pypy
Net方向:
Java方向:
Other:
<code>經驗</code>:平時基本上多線程就夠用了,如果想多核利用-多程序基本上就搞定了(分布式走起)實在不行一般都是分析一下性能瓶頸在哪,然後寫個擴充庫
如果需要和其他平台互動才考慮上面說的這些項目。如果是Web項目就更不用擔心了,現在哪個公司還不是混用?<code>JavaScript and Python and Go or Java or NetCore</code>。基本上上點規模的公司都會用到Python,之前都是<code>Python and Java</code>搭配使用,這幾年開始慢慢變成<code>Python and Go or NetCore</code>搭配使用了~
下集預估:<code>Actor模型</code> and <code>消息釋出/訂閱模型</code>
可能有些朋友不清楚<code>Actor</code>是個啥?我們從場景來切入一下:
以之前小明小子互刷銀行流水記錄為例,開始是這麼寫:小明小張死鎖問題
乍一看好像沒問題,其實容易出現死鎖現象,比如小明給小張轉1000:
小明先擷取自己的鎖,然後準備擷取小張的鎖
這時候遇到小張給小明轉賬(小張把自己的鎖先擷取了)
于是就死鎖了,圖示:
解決也很簡單,前面也說了好幾種方法,這邊再說下Python獨有的快速解決法:(完整版點我)
調用就比較簡單了:(通用方法點我)
上面的引入用了線程的各種知識,很多新手都直接崩潰,又是<code>死鎖</code>又是<code>活鎖</code>接着還衍生出了<code>算法</code>以及<code>線程安全</code>、<code>線程通信</code>等等一大堆東西要掌握,那有沒有一種簡單的方法,把線程的概念隐藏起來,然後所有的操作都不用加鎖呢?這樣就是是新手也能快速上手了~有!這便是我們今天要說的<code>Actor</code>
那啥是<code>Actor</code>呢?咱們去PPT裡畫個簡化版的圖:
我存款就發個消息到<code>MailBox</code>裡面,我轉賬也發個消息到<code>MailBox</code>裡面。不管是有一個消息,還是有100個消息,我統統放到隊列中,然後讓<code>Actor</code>對象順序處理,這樣就我不用管什麼鎖不鎖的也不用管别人了~
别人需要接收我的轉賬就到我的<code>MailBox</code>裡面拉消息即可,要是我轉賬的時候餘額不夠了它就給我的<code>MailBox</code>裡面發送條餘額不夠的消息
可能有些人會說了,那我用隊列<code>Queue</code>不就得了,好像也差不多啊?看起來的确差不多,但是<code>Queue</code>是同步操作,就算用了異步發送消息也要監聽和重試,太麻煩了~
其實你也可以把<code>Actor</code>了解為封裝的<code>Queue</code>,要幹什麼就異步發個消息到<code>Actor</code>的<code>MailBox</code>裡,這樣就不是同步操作,而且也不用關注那些雜七雜八的東西了。
切換到程序也很友善,把<code>Actor</code>互相通信的<code>Queue</code>換成程序版的即可,想要分布式部署也一樣,換成<code>MQ</code>或者<code>Redis</code>就好了,代碼基本上不需要什麼改動
概念彙總:
<code>Actor</code>:<code>Actor</code>之間不共享狀态,但是會接收别的<code>Actor</code>發送的異步消息,處理的過程中,會改變内部狀态,也可能向别的<code>Actor</code>發送消息
<code>Message</code>:消息是不可變的, 它的發送都是異步的,<code>Actor</code>内部有個<code>MailBox</code>來緩存消息
<code>MailBox</code>:<code>Actor</code>内部緩存消息的郵箱,其他<code>Actor</code>發送的消息都放到這裡,然後被本<code>Actor</code>處理,類似有多個生産者和一個消費者的<code>Queue</code>
先定義一個含有<code>Actor、MailBox</code>的精簡版<code>Actor</code>:
輸出:(通過<code>send</code>發送消息,通過<code>recv</code>接收消息)
用生成器(<code>yield</code>)實作一個簡單版的:
完善:和線程結合定義一個簡單版的<code>Actor</code>(向使用者屏蔽繁瑣的線程):
In [7]:
現在再寫小明小張轉賬互刷的<code>Code</code>就簡單了:
輸出:(<code>都不用引入Queue、Thread這些了</code>)
<code>Actor</code>的魅力就在于它的簡單,你隻需要<code>send</code>和<code>recv</code>其他複雜的部分根本不用過問,擴充也比較友善,比如以元組形式傳遞标簽消息,讓actor執行不同的操作:
先不看怎麼寫,遇到這種需求首先看看平時怎麼用的,以Net為例,聯想到Task:
這樣大體思路就有了,我們需要一個<code>Actor</code>類來處理執行和一個<code>Result</code>類傳回最終結果:
<code>Actor</code>模型非常适用于多個元件獨立工作,互相之間僅僅依靠消息傳遞的情況 如果想在多個元件之間維持一緻的狀态,那就不友善了,需要使用一些<code>Actor</code>的架構
Java最出名的就是<code>Akka</code>,這幾年貌似 <code>Quasar</code> 用的挺多(如果有其他常用的Actor模型可以補充一下)
Net起初是用的<code>Akka.Net</code>,後來官方出了 <code>Orleans</code>
Golang現在是 <code>ProtoActor</code> 比較火,支援<code>Go、Net、Python、JS、Java</code>,一般混合程式設計的公司都會選擇這款
Python以前<code>Pykka</code>比較火,現在更推薦 <code>Ray</code> or <code>pulsar</code>
進一步了解Actor可以閱讀以下源碼:
上節回顧:線程篇~Actor專題
看個需求:你有一個基于線程通信的程式,想讓它們實作<code>釋出/訂閱</code>模式的消息通信
這個有點像生産消費者模型,但要實作釋出/訂閱的消息通信模式,通常要引入一個單獨的<code>網關</code>|<code>交換機</code>對象作為所有消息的中介
PS:我們一般不直接将消息從一個任務發送到另一個,而是将其發送給<code>網關</code>|<code>交換機</code>, 然後由它發送給一個或多個被關聯任務
通俗講:
一個交換機就是維護訂閱者的集合
提供綁定(<code>attach</code>)解綁(<code>detach</code>)發送(<code>send</code>)這些方法
每個交換機通過一個<code>key</code>來定位(<code>get_exchange(key)</code>傳回一個<code>Exchange</code>對象)
批量通知訂閱者可以把消息發送給一個指定<code>key</code>的交換機
然後交換機會将它們發送給被綁定的訂閱者
看個例子:
訂閱者可能和交換機不在同一個機器上,這時候想顯示<code>log</code>輸出就需要設定下:
其實也很簡單,在交換機這台PC上弄個訂閱者即可:
PS:注意一個交換機可能存在的Bug(對于訂閱者的正确綁定和解綁:為了正确的管理資源,每一個綁定的訂閱者必須最終要解綁)
這個和使用檔案、鎖等很像,如果怕忘記,可以借助<code>上下文管理器</code>在交換機上添加個方法
eg,以上面代碼為例,進行改造:
其實還可以各種擴充,比如:
交換機可以實作一整個消息通道集合或提供交換機名稱的模式比對規則
擴充到分布式計算程式中(eg:将消息路由到不同機器上的任務中)
上次說了這麼生成<code>so共享庫</code>,然後通過<code>ctypes</code>子產品來調用,簡單回顧下:線程深入篇之~GIL專題
之前有人問之前的方式是否跨平台,當時是在Ubuntu下的,我們現在去CentOS測試下:
首先確定系統是多核(單核測試沒有意義)
現在看下測試結果:(和Ubuntu效果一樣,不需要修改任何代碼)
PS:<code>CentOS7</code>沒有安裝<code>htop</code>的:
現在準備說的是用<code>C</code>來寫<code>Python</code>子產品(友善使用)先看下應用場景:
提升性能(突破GIL)
核心業務代碼保密
友善調用(比<code>ctypes</code>的方式友善)
大概流程:
編寫C系列代碼
為了調用友善,把<code>c</code>和<code>python</code>進行下類型轉換(包裹函數)
打包(<code>setup.py</code>)
Github位址:https://github.com/lotapp/BaseCode/tree/master/python/5.concurrent/Thread/3.GIL/Ext
1.先來個簡單的案例:(你可以把<code>C</code>系列的三個檔案放在一個裡面)
先測試下c檔案有沒有問題:<code>gcc [-Wall] dnt.c -o dnt</code>
2.把對應的頭檔案也寫一下:(這個可以參考<code>golang</code>生成動态庫時産生的<code>頭檔案</code>)
3.寫一個包裹函數:<code>pack.c</code>(和Python2略有不同)
PS:安裝過<code>python3-dev</code>才會有<code>python.h</code>(CentOS叫:<code>python-devel</code>)
格式代碼
Python類型
C系列類型
<code>i</code>
<code>int</code>
<code>l</code>
<code>long</code>
<code>d</code>
<code>float</code>
<code>double</code>
<code>c</code>
<code>str</code>
<code>char</code>
<code>s</code>
<code>char *</code>
<code>z</code>
<code>str/None</code>
<code>char */NULL</code>
<code>D</code>
<code>complex</code>
<code>Py_Complex *</code>
<code>O</code>
<code>Any</code>
<code>PyObject *</code>
<code>S</code>
<code>PyStringObject *</code>
4.寫一個<code>Python</code>的<code>Setup</code>:
5.編譯測試一下(<code>python3 setup.py build</code> <code>python3 setup.py install</code>)
Python C-API參考手冊:https://docs.python.org/3/c-api/index.html
用C系列擴充Python:https://docs.python.org/3/extending/extending.html
使用distutils建構C和C ++擴充:https://docs.python.org/3/extending/building.html
官方文檔:concurrent.futures--啟動并行任務
上次說到了<code>yield from</code>,這次講的這個就是基于<code>線程/程序</code>再結合<code>yield</code>的一個通用實作:(上節回顧:并發程式設計~協程演變過程)
這個是Python3.2開始有<code>concurrent.futures</code>子產品,我們主要使用就2個類:<code>ThreadPoolExecutor</code>和<code>ProcessPoolExecutor</code>(本質上是對<code>threading</code>和<code>multiprocessing</code>進行了進階别的抽象,友善我們實作異步調用)
PS:如果不談協程,那麼這個代碼就可以算是并發程式設計的通用代碼了
通過使用以及看源碼發現:傳參和之前稍微有點不同
先看個簡單的引入例子:(用法和Java一樣)
輸出:(可以通過<code>task.done()</code>檢視任務是否執行完成)
<code>PoolExecutor</code>可以指定線程|程序數,不指定預設是:
線程:cpu核數的5倍
程序:cpu核數
源碼看下就懂了:
來個批量請求的案例:
PS:如果需要URL,可以這樣搞:<code>tasks = {executor.submit(get_html, url): url for url in url_list}</code>
輸出:(取得時候<code>url = tasks[task]</code>)
上面的代碼用map可以快速實作:(靈活性比<code>as_completed</code>稍微差點,合适場景下倒是挺友善)
輸出:(性能比<code>as_completed</code>高點)
這種方式如果也想要擷取到<code>url</code>,可以借助<code>zip</code>:
和線程池用法一緻,就換個名字而已(<code>ProcessPoolExecutor</code>):
官方給的系統執行流程:<code>https://github.com/python/cpython/blob/3.7/Lib/concurrent/futures/process.py</code>
引用一下官方分析:
<code>executor.map</code>會建立多個<code>_WorkItem</code>對象,每個對象都傳入了新建立的一個<code>Future</code>對象
把每個<code>_WorkItem</code>對象然後放進一個叫做<code>Work Items</code>的<code>dict</code>中,鍵是不同的<code>Work Ids</code>
建立一個管理<code>Work Ids</code>隊列的線程 <code>Local worker thread</code> 它能做2件事:
從<code>Work Ids</code>隊列中擷取<code>Work Id</code>通過<code>Work Items</code>找到對應的<code>_WorkItem</code>如果這個<code>Item</code>被取消了,就從<code>Work Items</code>裡面把它删掉,否則重新打包成一個<code>_CallItem</code>放入<code>Call Q</code>隊列中,而<code>executor</code>的那些程序會從隊列中取<code>_CallItem</code>執行,并把結果封裝成<code>_ResultItems</code>放入<code>Result Q</code>隊列中
從<code>Result Q</code>隊列中擷取<code>_ResultItems</code>,然後從<code>Work Items</code>更新對應的<code>Future</code>對象并删掉入口
有了我們前面講的知識,你再讀<code>concurrent.futures</code>子產品真的很輕松,大家有空可以去看看
簡單看下<code>Future</code>對象:
<code>cancel()</code>:嘗試去取消調用。如果調用目前正在執行,不能被取消(<code>傳回False</code>)
成功傳回True,失敗傳回False
<code>cancelled()</code>:如果調用被成功取消傳回True
<code>running()</code>:如果目前是否正在執行
<code>done()</code>:執行成功|被取消後
<code>result(Timeout = None)</code>:拿到調用傳回的結果(<code>阻塞等</code>)
<code>exception(timeout=None)</code>:捕獲程式執行過程中的異常
<code>add_done_callback(fn)</code>:将fn綁定到future對象上。當future對象被取消或完成運作時,fn函數将會被調用
知識點其實就這麼多了,其他的後面結合協程會繼續說的,然後還有一個<code>wait</code>的用法簡單說說:
輸出:(<code>wait</code>預設是等待全部完成)
指定等待的參數:
輸出:(傳回值是 <code>done=true的set集合</code> 和 <code>done=false的set</code> 組成的元組)
來個案例:
有這幾種常見的異常:
<code>concurrent.futures.CancelledError</code>
<code>concurrent.futures.TimeoutError</code>
<code>concurrent.futures.process.BrokenProcessPool</code>
寫在最後的話:線程現在雖然說了很多東西,其實等講到了協程後,線程就基本上不太用了,基本上都是<code>程序+協程</code>
用線程和程序的話基本上也是用最後說的通用方法,而什麼時候用線程和程序這就看是否耗CPU(eg:<code>計算、圖檔處理這些程序處理可以充分發揮cpu性能</code>)
參考文檔:
作者:毒逆天
出處:https://www.cnblogs.com/dotnetcrazy
打賞:<b>18i4JpL6g54yAPAefdtgqwRrZ43YJwAV5z</b>
本文版權歸作者和部落格園共有。歡迎轉載,但必須保留此段聲明,且在文章頁面明顯位置給出原文連接配接!