linux監控平台搭建-記憶體
上一篇文章說的硬碟。就寫一下。更加重要的東西。在手機上面是RAM。機器是memory。記憶體是按照位元組編址。每個位址的存儲單元可以存放8bit的資料、cpu 通過記憶體位址擷取一條指令和資料。記憶體溢出out-of-memory killer 負責終止使用記憶體過多的程序。詳細的細節請檢視/var/log/messages檔案。建立索引常會發生這種情況。管理者可以限制服務不被OOM。資料的預熱。壓力測定時。自動化測試。灰階釋出。監控采集。
每一個記憶體都是程序産生的。到底什麼是記憶體。其實程序是有自己的虛拟位址空間。虛拟位址空間對應的才是記憶體。
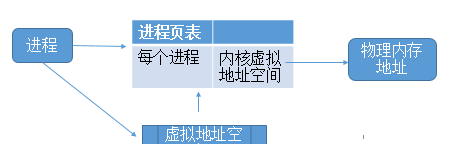
虛拟位址對應的實體位址不在實體記憶體中。産生缺頁中斷、真正配置設定實體位址,同時更新程序頁表
如果實體記憶體存在,但是被耗盡。則根據記憶體替換算法淘汰部門頁面至實體磁盤中。
程序的虛拟位址空間是有幾個概念。如下圖:

從作業系統角度來看,程序配置設定記憶體有兩種方式,分别由兩個系統調用完成:brk和mmap(不考慮共享記憶體)。
1、小于128k。brk是将資料段(.data)的最高位址指針_edata往高位址推;
2、大于128K。mmap是在程序的虛拟位址空間中(堆和棧中間,稱為檔案映射區域的地方)找一塊空閑的虛拟記憶體。
這兩種方式配置設定的都是虛拟記憶體,沒有配置設定實體記憶體。在第一次通路已配置設定的虛拟位址空間的時候,發生缺頁中斷,作業系統負責配置設定實體記憶體,然後建立虛拟記憶體和實體記憶體之間的映射關系
cat /proc/cpuinfo
64位的系統。是2^48虛拟位址空間是48、40位是實體位址
ps -o maj_flt,min_flt -p pid 檢視寫資料子產品。能看到大量的缺頁中斷
發成缺頁中斷後,執行了那些操作?
當一個程序發生缺頁中斷的時候,程序會陷入核心态,執行以下操作:
1、檢查要通路的虛拟位址是否合法
2、查找/配置設定一個實體頁
3、填充實體頁内容(讀取磁盤,或者直接置0,或者啥也不幹)
4、建立映射關系(虛拟位址到實體位址)
重新執行發生缺頁中斷的那條指令
如果第3步,需要讀取磁盤,那麼這次缺頁中斷就是majflt,否則就是minflt。
答:程式退出了,記憶體就會被系統慢慢釋放掉,系統有記憶體清理機制,
就算是new出來的程式中沒有釋放,程式停止後也會釋放的。但是new出來的對象沒用後,程式員都應該手動釋放掉,像C語言如果不釋放,長時間運作必然會有記憶體不足。Java程式雖然jvm有垃圾回收機制,但是如果超出了垃圾回收機制的範圍也會經常出現記憶體不足
記憶體溢出 out of memory,是指程式在申請記憶體時,沒有足夠的記憶體空間供其使用,出現out of memory;比如申請了一個integer,但給它存了long才能存下的數,那就是記憶體溢出。
記憶體洩露 memory leak,是指程式在申請記憶體後,無法釋放已申請的記憶體空間,一次記憶體洩露危害可以忽略,但記憶體洩露堆積後果很嚴重,無論多少記憶體,遲早會被占光。
memory leak會最終會導緻out of memory!
記憶體溢出就是你要求配置設定的記憶體超出了系統能給你的,系統不能滿足需求,于是産生溢出。
記憶體洩漏是指你向系統申請配置設定記憶體進行使用(new),可是使用完了以後卻不歸還(delete),結果你申請到的那塊記憶體你自己也不能再通路(也許你把它的位址給弄丢了),而系統也不能再次将它配置設定給需要的程式。一個盤子用盡各種方法隻能裝4個果子,你裝了5個,結果掉倒地上不能吃了。這就是溢出!比方說棧,棧滿時再做進棧必定産生空間溢出,叫上溢,棧空時再做退棧也産生空間溢出,稱為下溢。就是配置設定的記憶體不足以放下資料項序列,稱為記憶體溢出。
計算方法:讀取/proc/meminfo 中的内容,其中的mem.memfree是free+buffers+cached,mem.memused=mem.memtotal-mem.memfree。使用者具體可以參考free指令的輸出和幫助文檔來了解
mem.memtotal:記憶體總大小
mem.memused:使用了多少記憶體
mem.memused.percent:使用的記憶體占比
mem.memfree
mem.memfree.percent
mem.swaptotal:swap總大小
mem.swapused:使用了多少swap
mem.swapused.percent:使用的swap的占比
mem.swapfree
mem.swapfree.percent
#dmidecode | grep -A16 "Memory Device$"
檢視每個記憶體大小
#dmidecode | grep -A16 "Memory Device$" | grep -i "Size" | grep -v "No"
top -d 1
free -m
1、找出系統性能瓶頸(包括硬體瓶頸和軟體瓶頸);
2、提供性能優化的方案(更新硬體?改進系統系統結構?);
3、達到合理的硬體和軟體配置;
4、使系統資源使用達到最大的平衡。(一般情況下系統良好運作的時候恰恰各項資源達到了一個平衡體,任何一項資源的過渡使用都會造成平衡體系破壞,進而造成系統負載極高或者響應遲緩。比如CPU過渡使用會造成大量程序等待CPU資源,系統響應變慢,等待會造成程序數增加,程序增加又會造成記憶體使用增加,記憶體耗盡又會造成虛拟記憶體使用,使用虛拟記憶體又會造成磁盤IO增加和CPU開銷增加)
1、記憶體(實體記憶體不夠時會使用交換記憶體,使用swap會帶來磁盤I0和cpu的開銷)
2、使用常見的性能分析工具(vmstat、top、free、iostat等)
vmstat是一個很全面的性能分析工具,可以觀察到系統的程序狀态、記憶體使用、虛拟記憶體使用、磁盤的IO、中斷、上下文切換、CPU使用等。對于 Linux 的性能分析,100%了解 vmstat 輸出内容的含義,并能靈活應用,那對系統性能分析的能力就算是基本掌握了。
下面是vmstat指令的輸出結果: vmstat 1 5
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
1 0 0 191908 188428 1259328 0 0 10 27 61 92 0 1 98 0 0
0 0 0 191892 188428 1259360 0 0 0 0 117 226 0 0 100 0 0
對輸出解釋如下:
a.r清單示運作和等待CPU時間片的程序數,這個值如果長期大于系統CPU個數,就說明CPU資源不足,可以考慮增加CPU;
b.b清單示在等待資源的程序數,比如正在等待I/O或者記憶體交換等。
a.swpd清單示切換到記憶體交換區的記憶體數量(以KB為機關)。如果swpd的值不為0或者比較大,而且si、so的值長期為0,那麼這種情況一般不用擔心,不會影響系統性能;
b.free清單示目前空閑的實體記憶體數量(以KB為機關);
c.buff清單示buffers cache的記憶體數量,一般對塊裝置的讀寫才需要緩沖;
d.cache清單示page cached的記憶體數量,一般作檔案系統的cached,頻繁通路的檔案都會被cached。如果cached值較大,就說明cached檔案數較多。如果此時IO中的bi比較小,就說明檔案系統效率比較好。
a.si清單示由磁盤調入記憶體,也就是記憶體進入記憶體交換區的數量;
b.so清單示由記憶體調入磁盤,也就是記憶體交換區進入記憶體的數量
c.一般情況下,si、so的值都為0,如果si、so的值長期不為0,則表示系統記憶體不足,需要考慮是否增加系統記憶體。
a.bi清單示從塊裝置讀入的資料總量(即讀磁盤,機關KB/秒)
b.bo清單示寫入到塊裝置的資料總量(即寫磁盤,機關KB/秒)
這裡設定的bi+bo參考值為1000,如果超過1000,而且wa值比較大,則表示系統磁盤IO性能瓶頸。
a.in清單示在某一時間間隔中觀察到的每秒裝置中斷數;
b.cs清單示每秒産生的上下文切換次數。
上面這兩個值越大,會看到核心消耗的CPU時間就越多。
a.us列顯示了使用者程序消耗CPU的時間百分比。us的值比較高時,說明使用者程序消耗的CPU時間多,如果長期大于50%,需要考慮優化程式啥的。
b.sy列顯示了核心程序消耗CPU的時間百分比。sy的值比較高時,就說明核心消耗的CPU時間多;如果us+sy超過80%,就說明CPU的資源存在不足。
c.id列顯示了CPU處在空閑狀态的時間百分比;
d.wa清單示IO等待所占的CPU時間百分比。wa值越高,說明IO等待越嚴重。如果wa值超過20%,說明IO等待嚴重。
e.st列一般不關注,虛拟機占用的時間百分比。 (Linux 2.6.11)
1、先說說什麼是swap分區以及它的作用?
Swap分區,即交換區,Swap空間的作用可簡單描述為:當系統的實體記憶體不夠用的時候,就需要将實體記憶體中的一部分空間釋放出來,以供目前運作的程式 使用。
那些被釋放的空間可能來自一些很長時間沒有什麼操作的程式,這些被釋放的空間被臨時儲存到Swap空間中,等到那些程式要運作時,再從Swap中恢 複儲存的資料到記憶體中。
這樣,系統總是在實體記憶體不夠時,才進行Swap交換。 其實,Swap的調整對Linux伺服器,特别是Web伺服器的性能至關重要。通過調整Swap,有時可以越過系統性能瓶頸,節省系統更新費用。
配置設定太多的Swap空間會浪費磁盤空間,而Swap空間太少,則系統會發生錯誤。
如果系統的實體記憶體用光了,系統就會跑得很慢,但仍能運作;如果Swap空間用光了,那麼系統就會發生錯誤。
例如,Web伺服器能根據不同的請求數量衍生 出多個服務程序(或線程),如果Swap空間用完,則服務程序無法啟動,通常會出現“application is out of memory”的錯誤,嚴重時會造成服務程序的死鎖。
是以Swap空間的配置設定是很重要的。
通常情況下,Swap空間應大于或等于實體記憶體的大小,最小不應小于64M,通常Swap空間的大小應是實體記憶體的2-2.5倍。
但根據不同的應用,應有不同的配置:如果是小的桌面系統,則隻需要較小的Swap空間,而大的伺服器系統則視情況不同需要不同大小的Swap空間。
特别是資料庫伺服器和Web服 務器,随着通路量的增加,對Swap空間的要求也會增加,具體配置參見各伺服器産品的說明。
另外,Swap分區的數量對性能也有很大的影響。因為Swap交換的操作是磁盤IO的操作,如果有多個Swap交換區,Swap空間的配置設定會以輪流的方式 操作于所有的Swap,這樣會大大均衡IO的負載,加快Swap交換的速度。
如果隻有一個交換區,所有的交換操作會使交換區變得很忙,使系統大多數時間處 于等待狀态,效率很低。用性能監視工具就會發現,此時的CPU并不很忙,而系統卻慢。這說明,瓶頸在IO上,依靠提高CPU的速度是解決不了問題的
看了這麼多,再想想有時在論壇中的有的人說的他們的記憶體很大而沒必要使用swap分區,别人10台機器能解決的問題,我們若合理使用swap分區,使用8台機器能解決的問題,何樂而不為呢 ?
1.首先,做到盡量使用分區而非檔案,記住除非萬不得已
2.當然也可能是空間太小,那麼就自己添加swap分區
3.特别注意的的是使用分區号較小的分區
4.分布到不同裝置上可以實作輪循
5.若真的有多個swap分區,也可以指定優先級,意思也就是優先使用性能較好的分區
注意在配置檔案/etc/fstab中的書寫:(數字越大,優先級越高,也可以使用swapon -p 來指定)
/dev/hda1 swap swap defaults,pri=10 0 0
/dev/hda5 swap swap defaults,pri=5 0 0
6.一個重要的參數:
sysctl -a | grep vm.swa
linux核心調優過程有幾個特殊的值,包括這個,不是具體的百分比,而是一個期望值,在這裡越接近0盡量使用cache,越接近100盡量使用swap,隻是個趨向值。現在預設是60,DBA通常是90以上
7.兩個一般不調節的值:
vm.swap_token_timeout = 300 時間間隔
vm.page-cluster = 3 一次性寫入swap的頁面數2^3*4K = 32K
linux下記憶體配置設定的管理主要通過核心參數來控制:
以下參數位于 proc 檔案系統的 /proc/sys/vm/ 目錄中。
overcommit_memory :規定決定是否接受超大記憶體請求的條件。這個參數有三個可能的值:
* 0 預設設定。核心執行啟發式記憶體過量使用處理,方法是估算可用記憶體量,并拒絕明顯無效的請求。遺憾的是因為記憶體是使用啟發式而非準确算法計算進行部署,這個設定有時可能會造成系統中的可用記憶體超載。不讓過度使用,直接報錯
* 1 核心執行無記憶體過量使用處理。使用這個設定會增大記憶體超載的可能性,但也可以增強大量使用記憶體任務的性能。應用程式在需要時配置設定,允許過度使用
* 2 記憶體拒絕等于或者大于總可用 swap 大小以及 overcommit_ratio 指定的實體 RAM 比例的記憶體請求。如果您希望減小記憶體過度使用的風險,這個設定就是最好的。 将swap直接使用,使用的記憶體 = swap + ram * 50%
注意:隻為 swap 區域大于其實體記憶體的系統推薦這個設定overcommit_ratio,将 overcommit_memory 設定為 2 時,指定所考慮的實體 RAM 比例。預設為 50。
記憶體不足(OOM)指的是所有可用記憶體,包括 swap 空間都已被配置設定的計算狀态。預設情況下,這個狀态可造成系統 panic,并停止如預期般工作。但将 /proc/sys/vm/panic_on_oom 參數設定為 0 會讓核心在出現 OOM 時調用 oom_killer 功能。通常 oom_killer 可殺死偷盜程序,并讓系統正常工作。
可在每個程序中設定以下參數,提高您對被 oom_killer 功能殺死的程序的控制。它位于 proc 檔案系統中 /proc/pid/ 目錄下,其中 pid 是程序 ID。oom_adj定義 -16 到 15 之間的一個數值以便幫助決定某個程序的 oom_score。oom_score 值越高,被 oom_killer 殺死的程序數就越多。将 oom_adj 值設定為 -17 則為該程序禁用 oom_killer。
注意:由任意調整的程序衍生的任意程序将繼承該程序的 oom_score。例如:如果 sshd 程序不受 oom_killer 功能影響,所有由 SSH 會話産生的程序都将不受其影響。這可在出現 OOM 時影響 oom_killer 功能救援系統的能力。
參考:
http://blog.51cto.com/asinego/1905622
做有積累的事~~