一、ES分片
1、分片是ES中最小的工作單元。
2、是一個Lucence的Index
二、反向索引的不可變性
1、反向索引采用的是Immutable Design,一旦生成不可更改。
2、不可變性,帶來的好處如下:
2.1、不需要考慮并發寫檔案的問題,避免了鎖機制帶來的性能問題
2.2、一旦讀入核心的檔案系統緩存,便留在那裡,隻要檔案系統有足夠的空間,大部分請求就會直接請求記憶體,不會命中磁盤,極大的提高了性能
2.3、緩存容易生成和為何,并且資料可以被壓縮
3、不可變性,也帶來了挑戰: 如果需要讓一個新的文檔可以被搜尋,需要重建整個索引
三、Lucene Index
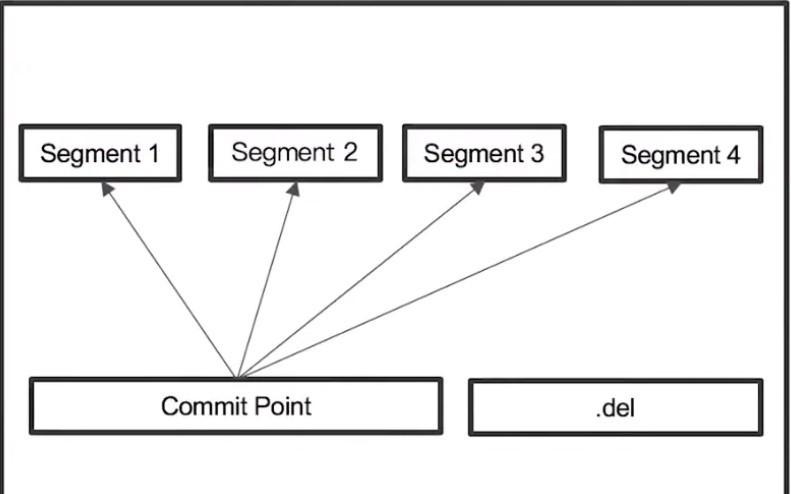
1、一個ES中的shard就是Lucene中的Index(An ES Shard=A Lucene Index)
2、在Lucene中,單個反向索引檔案被稱為Segment;Segment是自包含的,不可變的,多個Segment彙總在一起,稱為Lucene的Index;
3、當有新文檔寫入時,會生成新segment;查詢是會同時查詢所有的segments,并且對結果彙總。
4、Lucene中有一個檔案,用來記錄所有segment資訊,叫做commit point.
5、删除的文檔資訊,儲存在.del檔案中。
四、Refresh

1、将Index Buffer寫入Segment的過程叫做Refresh,當執行Refresh的時候不執行fsync操作
2、Refresh頻率:預設1s發生一次,可通過參數index.refresh_interval配置,refresh後資料就可以被搜尋到了,這也是ES被稱為近實時搜尋(NRT)
3、如果有大量的資料寫入,就會産生很多的segment;
4、Index Buffer被占滿是,就會觸發refresh,index buffer預設大小是JVM的10%;
五、Transaction Log
1、segment寫入磁盤的過程相對耗時,借助檔案系統緩存,refresh的時候,先将segment寫入檔案系統緩存,以開放查詢。
2、為了保證資料不會丢失,在寫入文檔時,同時寫入Transcation Log,高版本開始,預設transaction log預設落盤;
3、每個分片都有一個transaction log;
4、在ES refresh的時候,index buffer被清空,transaction Log不會清空。
5、在發生斷電的時候,因為有transaction Log的落盤,資料不會丢失。
六、ES Flash和Lucene Commit
1、調用Refresh,Index Buffer清空并且Refresh
2、調用fsync,将緩存中的segments寫入磁盤
3、清空(删除)transaction log
4、預設30分鐘調用一次
5、transaction log 滿(預設512M)
七、Merge
1、Segment很多,需要被定期合并。可以減少segments和删除已經删除的文檔
2、ES和Lucene會自動進行merge操作。如果手動執行,可以通過使用以下API進行操作:POST my_index/_forcemerge