最近一個客戶找到我說是所有的SQL Server 伺服器的記憶體都被用光了,然後截圖給我看了一台伺服器的任務管理器。如圖
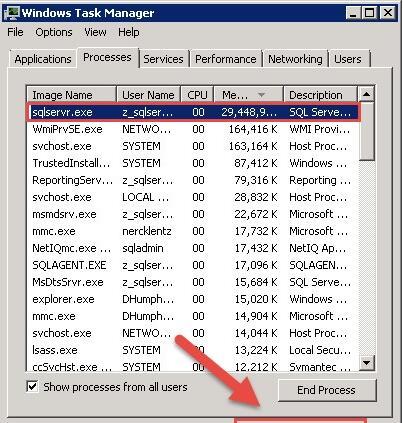
這裡要說明一下任務管理器不會完整的告訴真的記憶體或者CPU的使用情況,也就是說這裡隻能得到非精确的資訊,有可能就是一個假警報。
為了讓我的客戶放心,我檢查了伺服器并且檢視了很多性能名額。我所看到的就是CPU和硬碟使用都是很低的隻有記憶體是高的,這恰恰是我們期望的SQLServer 伺服器的狀态。SQL Server會盡可能的使用記憶體,通過緩存盡可能多的磁盤來改善性能。當然如果OS需要它也會立即釋放資源回來。
SQL Server 對記憶體是“貪得無厭”的,它會持有所有配置設定給它的記憶體,不論是否使用。而這也是我們想要它去做的。因為它會存儲資料和執行計劃在緩存中,然後當使用完這些記憶體時,它不會釋放這些記憶體,緩存到記憶體中,除非兩種情況才會釋放緩存的資料記憶體:1) SQL Server 重新開機或者記憶體不足 2) 作業系統需要記憶體
預設的記憶體設定就是使用所有記憶體(安裝時設定),當作業系統需要記憶體時,它也會大量釋放記憶體。然後等到有記憶體時在重新大量持有。但是這種不是最佳實踐,最好還是設定一個最大記憶體限制,這樣作業系統就會保證一定量的記憶體永遠為SQL Server 使用。

當看到資料總管,Available MB 的記憶體有兩部分組成Standby--備用和Free--可用,這Standby 的空間系統已經把它緩存了,而Free的記憶體意味着沒有被使用。它們都叫做可利用記憶體。是以針對一開始那個客戶擔憂我們大可不必太擔心。當然我們還需要健康其他的性能計數器,查明是否存在記憶體影響性能的隐患。需要關注的名額如下:
Page Life Expectancy
Available Bytes
Buffer Cache Hit Ratio
Target & Total Server Memory
Memory Grants Pending
Pages/sec (Hard Page Faults)
Batch Requests/sec & Compilations/sec
介紹下這些性能參數:
這個性能計數器記錄了資料頁(非鎖定)在緩沖池中的平均時間。在生産高峰這個數值可能比較低,但是一般要保持這個資料在300s以上,資料待在緩沖中時間越長,那麼SQL的IO操作越少。
如果長期這個數值在300s以下,可以考慮增加記憶體,當然由于現在記憶體越來越大,這個值也變得不那麼重要了,但是對于中小系統依然可以作為一個标準門檻值。
由于這個門檻值基于32位系統的4G記憶體,那麼标準算法可以大緻可以推算:記憶體大小(GB)/4*300。
也可以使用下面的語句來查詢該計數器:
該計數器監測還有多少可用記憶體,是否作業系統存在記憶體壓力。一般我們調查是否這個計數器持續在500MB以下,這說明記憶體過低。如果持續低于500則說明你需要增加更多的記憶體。
這個計數器不能通過T-SQL查詢,隻能通過性能螢幕觀察。
緩沖命中率,這個計數器記錄平均多少頻率從緩沖池中取得資料。我們在OLTP資料庫中一般這個比率是90%-95%(該數值經由@MSSQL123 指出發現是錯誤的,再次進行修改)。由于sqlserver 把預讀也作為緩沖比例,是以導緻該值很高,是以該計數器隻做了解,不能作為真實性能瓶頸參考了。如果該計數器持續低于90%,則需要增加記憶體。
在可以使用下面的T-SQL語句查詢:
伺服器目前總記憶體(buffer)以及目标記憶體,在緩沖池初始化增加記憶體的時候,總記憶體會比目标記憶體稍低一點。這個比例會逐漸接近1,如果總記憶體沒有增長很快,就會顯著低于目标記憶體,這就表示如下兩點:
1) 你可以配置設定盡可能多的記憶體,SQL能緩存整個資料庫到記憶體中,然後如果資料庫小于機器記憶體,記憶體不會完全用光,在這種情況下,總記憶體将永遠小于目标記憶體。
2) SQL不能增加緩沖池,比如系統記憶體有壓力。如果這種情況你需要增加最大伺服器記憶體,或者增加記憶體來改善性能。
這個計數器測量等待記憶體授予的SQL的程序數量。一般推薦門檻值為1或者更少。如果大于1這說明記憶體不足按順序等待記憶體釋放再操作SQL。
一般工作中出現這種等待可能是由于糟糕的查詢,缺失索引,排序或者哈希引起的。為了查明原因可以查詢DMV --sys.dm_exec_query_memory_grants 這個視圖,将會展示哪一個查詢需要記憶體授予執行。
如果不是以上原因引起的記憶體等待,則需要增加記憶體來解決這個問題。此時就有理由增加硬體了。查詢的T-SQL語句如下:
這裡也使用資料庫級别計數器:當需要讀取或寫入的頁不在記憶體中,需要到磁盤中讀取時計數。這個計數器是一個記錄讀和寫的總和并且不能直接在記憶體中擷取隻能從因盤中讀取(導緻resulting in hard page faults),這個問題是由于作業系統必須交換檔案在磁盤上,當通路記憶體時,記憶體不足則需要交換檔案到磁盤上,由于磁盤讀寫速度遠低于記憶體,性能就會受到嚴重影響。
對于這個計數器,推薦門檻值為<50(或者某個穩定值),如果看到高于這個值,不過需要注意,隻要這個值能夠穩定在一個較低的水準,沒有持續性的大批量資料的寫入(磁盤)于讀取(從磁盤載入記憶體),都可以接受。相反,如果長期在一個高位水準,并且觀察到PLE不能穩定在參考值範圍内,說明記憶體可能存在瓶頸。當然,如果資料庫備份或者還原,包括導出、導入資料以及記憶體中映射檔案等等這些也會導緻性能計數器超出某個穩定值。
該計數器包含兩個檢查
SQL Server: SQL Statistics – Batch Request/Sec. 傳入查詢的數量(批處理數量)
SQL Server: SQL Statistics - Compilations/Sec. 建立立的執行計劃數量
如果Compilations/sec是25%或者相對Batch Requests/sec更高,則執行計劃将被放到緩存中,但是永遠不會重用執行計劃。寶貴的記憶體就被浪費了,而不是緩存資料。這是糟糕的實踐,我們要做的就是阻止這種情況,
如果Compilation/sec 很高比如100,表示有大量的即席查詢正在運作。這時可以啟用“optimize for ad hoc”把執行計劃緩存,但是隻有在第二次查詢時才能被使用。
使用如下T-SQL可以得到相應的名額:
同樣可以獲得比率:
推薦門檻值:一般來說,我都是采用10%用于作業系統其它90%配置設定給資料庫。當然如果記憶體很大可以調整這個比例小于1/9,對于記憶體較小的通常我都預留4-6G左右給作業系統。
在性能螢幕中看一下這個計數器,我們可以看到這個伺服器處于健康狀态下,有11GB的可用空間,沒有PageFaults(I/O隻從緩存中沒有交換到磁盤),緩沖的比率為100%,PLE超過20000s,沒有記憶體等待,充足的總記憶體和較低的編譯比率(編譯數/查詢數).
這個測量資料很容易了解,這要比任務管理器更具有作用,能依據此做出判斷是否有足夠的記憶體在這台SQL Server伺服器上。
如果隻根據任務管理器來做出判斷,我們很容易出現錯誤決定。因為不管系統多少記憶體,SQL Server 會盡可能的使用占用記憶體,這不是bug。緩存資料在記憶體中有很好的效果,意味着伺服器是健康的,也為使用者提供了更好的執行效率。在實際資料庫環境中,一般突然遇到的性能問題多半是因為T-SQL語句引起的,就如我前面提到糟糕的查詢(缺失索引、排序、哈希等等),這個時候通過語句優化可以很好的解決突發問題,這裡就不詳解了。如果伺服器普遍存在文章中出現的記憶體性能計數器問題,那就寫報告送出記憶體增加需求吧。