MongoDB是一個基于分布式檔案存儲的資料庫,最近兩年聲音變小了,但是在很多系統中仍然被廣泛使用。如果你的系統中用到了,不妨看看這篇文章。
按照官方的定義,Spark 是一個通用,快速,适用于大規模資料的處理引擎。
通用性:我們可以使用Spark SQL來執行正常分析, Spark Streaming 來流資料處理, 以及用Mlib來執行機器學習等。Java,python,scala及R語言的支援也是其通用性的表現之一。
快速:這個可能是Spark成功的最初原因之一,主要歸功于其基于記憶體的運算方式。當需要處理的資料需要反複疊代時,Spark可以直接在記憶體中暫存資料,而無需像Map Reduce一樣需要把資料寫回磁盤。官方的資料表明:它可以比傳統的Map Reduce快上100倍。
大規模:原生支援HDFS,并且其計算節點支援彈性擴充,利用大量廉價計算資源并發的特點來支援大規模資料處理。
那我們能用Spark來做什麼呢?場景數不勝數。
最簡單的可以隻是統計一下某一個頁面多少點選量,複雜的可以通過機器學習來預測。
個性化 是一個常見的案例,比如說,Yahoo的網站首頁使用Spark來實作快速的使用者興趣分析。應該在首頁顯示什麼新聞?原始的做法是讓使用者選擇分類;聰明的做法就是在使用者互動的過程中揣摩使用者可能喜歡的文章。另一方面就是要在新聞進來時候進行分析并确定什麼樣的使用者是可能的閱聽人。新聞的時效性非常高,按照正常的MapReduce做法,對于Yahoo幾億使用者及海量的文章,可能需要計算一天才能得出結果。Spark的高效運算可以在這裡得到充分的運用,來保證新聞推薦在數十分鐘或更短時間内完成。另外,如美國最大的有線電視商Comcast用它來做節目推薦,最近剛和滴滴聯姻的uber用它實時訂單分析,優酷則在Spark上實作了商業智能的更新版。
在我們開始談MongoDB 和Spark 之前,我們首先來了解一下Spark的生态系統。Spark 作為一個大型分布式計算架構,需要和其他元件一起協同工作。
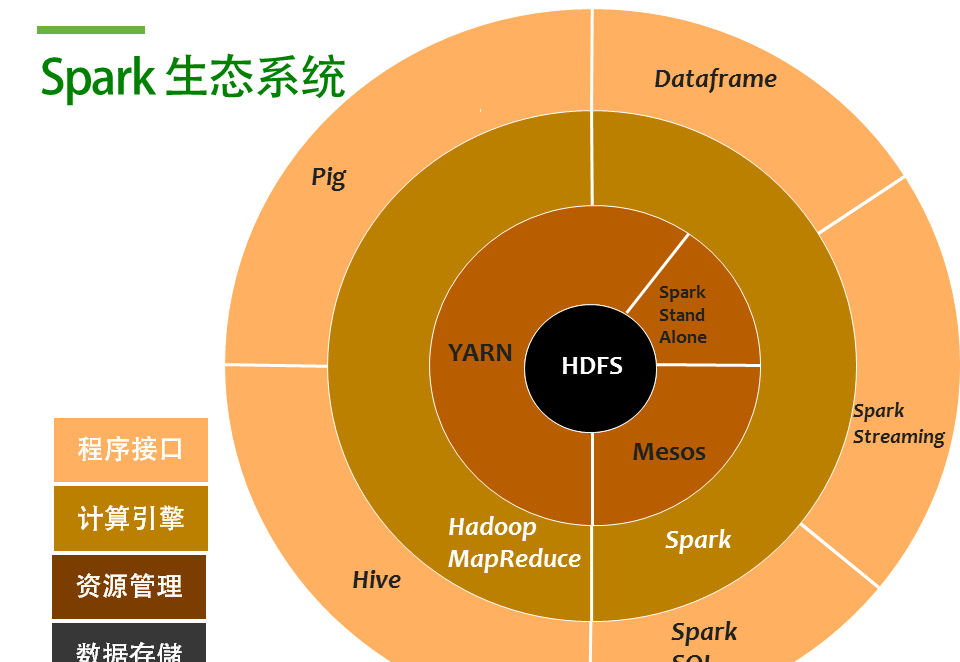
在Hdaoop裡面,HDFS是其核心,作為一個資料層。
Spark是Hadoop生态系統的一顆新星,原生就支援HDFS。大家知道HDFS是用來管理大規模非結構化資料的存儲系統,具有高可用和巨大的橫向擴充能力。
而作為一個橫向擴充的分布式叢集,資源管理是其核心必備的能力,Spark 可以通過YARN或者MESOS來負責資源(CPU)配置設定和任務排程。如果你不需要管理節點的高可用需求,你也可以直接使用Spark standalone。
在有了資料層和資源管理層後, 接下來就是我們真正的計算引擎。
Hadoop技術的兩大基石之一的MapReduce就是用來實作叢集大規模并行計算。而現在就多了一個選項:Spark。Map Reduce的特點是,用4個字來概括,簡單粗暴。采用divide & conquer戰術,我們可以用Map Reduce來處理PB級的資料。而Spark 作為打了雞血的Map Reduce增強版,利用了記憶體價格大量下降的時代因素,充分把計算所用變量和中間結果放到記憶體裡,并且提供了一整套機器學習的分析算法,在加上很多語言的支援,使之成為一個較之于Map Reduce更加優秀的選擇。
由于MapReduce 是一個相對并不直覺的程式接口,是以為了友善使用,一系列的高層接口如Hive或者Pig應運而生。Hive可以讓我們使用非常熟悉的SQL語句的方式來做一些常見的統計分析工作。同理,在Spark 引擎層也有類似的封裝,如Spark SQL、RDD以及2.0版本新推出的Dataframe等。
是以一個完整的大資料解決方案,包含了存儲,資源管理,計算引擎及接口層。那麼問題來了:我們畫了這麼大這麼圓的大餅,MongoDB可以吃哪一塊呢?

MongoDB是個什麼?是個database。是以自然而然,MongoDB可以擔任的角色,就是資料存儲的這一部分。在和 Spark一起使用的時候,MongoDB就可以扮演HDFS的角色來為Spark提供計算的原始資料,以及用來持久化分析計算的結果。
既然我們說MongoDB可以用在HDFS的地方,那我們來詳細看看兩者之間的差異性。
在說差別之前,其實我們可以先來注意一下兩者的共同點。HDFS和MongoDB都是基于廉價x86伺服器的橫向擴充架構,都能支援到TB到PB級的資料量。資料會在多節點自動備份,來保證資料的高可用和備援。兩者都支援非結構化資料的存儲,等等。
但是,HDFS和MongoDB更多的是差異點:
如在存儲方式上 HDFS的存儲是以檔案為機關,每個檔案64MB到128MB不等。而MongoDB則是細顆粒化的、以文檔為機關的存儲。
HDFS不支援索引的概念,對資料的操作局限于掃描性質的讀,MongoDB則支援基于二級索引的快速檢索。
MongoDB可以支援常見的增删改查場景,而HDFS一般隻是一次寫入後就很難進行修改。
從響應時間上來說,HDFS一般是分鐘級别而MongoDB對手請求的響應時間通常以毫秒作為機關。
如果說剛才的比較有些抽象,我們可以結合一個實際一點的例子來了解。
比如說,一個比較經典的案例可能是日志記錄管理。在HDFS裡面你可能會用日期範圍來命名檔案,如7月1日,7月2日等等,每個檔案是個日志文本檔案,可能會有幾萬到幾十萬行日志。
而在MongoDB裡面,我們可以采用一個JSON的格式,每一條日志就是一個JSON document。我們可以對某幾個關心的字段建索引,如時間戳,錯誤類型等。
我們來考慮一些場景,加入我們相對7月份所有日志做一些全量的統計,比如每個頁面的所有點選量,那麼這個HDFS和MongoDB都可以正常處理。
如果有一天你的經理告訴你:他想知道網站上每天有多少404錯誤在發生,這個時候如果你用HDFS,就還是需要通過全量掃描所有行,而MongoDB則可以通過索引,很快地找到所有的404日志,可能花數秒鐘就可以解答你經理的問題。
又比如說,如果你希望對每個日志項加一個自定義的屬性,在進行一些預處理後,MongoDB就會比較容易地支援到。而一般來說,HDFS是不支援更新類型操作的。
好的,我們了解了MongoDB為什麼可以替換HDFS并且為什麼有這個必要來做這個事情,下面我們就來看看Spark和MongoDB怎麼玩!
Spark的工作流程可以概括為三部曲:建立并發任務,對資料進行transformation操作,如map, filter,union,intersect等,然後執行運算,如reduce,count,或者簡單地收集結果。
這裡是Spark和MongoDB部署的一個典型架構。
Spark任務一般由Spark的driver節點發起,經過Spark Master進行資源排程分發。比如這裡我們有4個Spark worker節點,這些節點上的幾個executor 計算程序就會同時開始工作。一般一個core就對應一個executor。
每個executor會獨立的去MongoDB取來原始資料,直接套用Spark提供的分析算法或者使用自定義流程來處理資料,計算完後把相應結果寫回到MongoDB。
我們需要提到的是:在這裡,所有和MongoDB的互動都是通過一個叫做Mongo-Spark的連接配接器來完成的。
另一種常見的架構是結合MongoDB和HDFS的。Hadoop在非結構化資料處理的場景下要比MongoDB的普及率高。是以我們可以看到不少使用者會已經将資料存放在HDFS上。這個時候你可以直接在HDFS上面架Spark來跑,Spark從HDFS取來原始資料進行計算,而MongoDB在這個場景下是用來儲存處理結果。為什麼要這麼麻煩?幾個原因:
Spark處理結果數量可能會很大,比如說,個性化推薦可能會産生數百萬至數千萬條記錄,需要一個能夠支援每秒萬級寫入能力的資料庫
處理結果可以直接用來驅動前台APP,如使用者打開頁面時擷取背景已經為他準備好的推薦清單。
在這裡我們在介紹下MongoDB官方提供的Mongo Spark連接配接器 。目前有3個連接配接器可用,包括社群第三方開發的和之前Mongo Hadoop連接配接器等,這個Mongo-Spark是最新的,也是我們推薦的連接配接方案。
這個連接配接器是專門為Spark打造的,支援雙向資料,讀出和寫入。但是最關鍵的是條件下推,也就是說:如果你在Spark端指定了查詢或者限制條件的情況下,這個條件會被下推到MongoDB去執行,這樣可以保證從MongoDB取出來、經過網絡傳輸到Spark計算節點的資料确實都是用得着的。沒有下推支援的話,每次操作很可能需要從MongoDB讀取全量的資料,性能體驗将會很糟糕。拿剛才的日志例子來說,如果我們隻想對404錯誤日志進行分析,看那些錯誤都是哪些頁面,以及每天錯誤頁面數量的變化,如果有條件下推,那麼我們可以給MongoDB一個限定條件:錯誤代碼=404, 這個條件會在MongoDB伺服器端執行,這樣我們隻需要通過網絡傳輸可能隻是全部日志的0.1%的資料,而不是沒有條件下推情況下的全部資料。
另外,這個最新的連接配接器還支援和Spark計算節點Co-Lo 部署。就是說在同一個節點上同時部署Spark執行個體和MongoDB執行個體。這樣做可以減少資料在網絡上的傳輸帶來的資源消耗及時延。當然,這種部署方式需要注意記憶體資源和CPU資源的隔離。隔離的方式可以通過Linux的cgroups。
目前已經有很多案例在不同的應用場景中使用Spark+MongoDB。
法國航空是法國最大的航空公司,為了提高客戶體驗,在最近施行的360度客戶視圖中,使用Spark對已經收集在MongoDB裡面的客戶資料進行分類及行為分析,并把結果(如客戶的類别、标簽等資訊)寫回到MongoDB内每一個客戶的文檔結構裡。
Stratio是美國矽谷一家著名的金融大資料公司。他們最近在一家在31個國家有分支機構的跨國銀行實施了一個實時監控平台。該銀行希望通過對日志的監控和分析來保證客戶服務的響應時間以及實時監測一些可能的違規或者金融欺詐行為。在這個應用内, 他們使用了:
Apache Flume 來收集log
Spark來處理實時的log
MongoDB來存儲收集的log以及Spark分析的結果,如Key Performance Indicators等
東方航空最近剛完成一個Spark運價的POC測試。
東方航空作為國内的3大行之一,每天有1000多個航班,服務26萬多乘客。過去,顧客在網站上訂購機票,平均資料庫查詢200次就會下單訂購機票,但是現在平均要查詢1.2萬次才會發生一次訂購行為,同樣的訂單量,查詢量卻成長百倍。按照50%直銷率這個目标計算,東航的運價系統要支援每天16億的運價請求。
目前的運價是通過實時計算的,按照現在的計算能力,需要對已有系統進行100多倍的擴容。另一個常用的思路,就是采用空間換時間的方式。與其對每一次的運價請求進行耗時300ms的運算,不如事先把所有可能的票價查詢組合窮舉出來并進行批量計算,然後把結果存入MongoDB裡面。當需要查詢運價時,直接按照 出發+目的地+日期的方式做一個快速的DB查詢,響應時間應該可以做到幾十毫秒。
那為什麼要用MongoDB?因為我們要處理的資料量龐大無比。按照1000多個航班,365天,26個倉位,100多管道以及數個不同的航程類型,我們要實時存取的運價記錄有數十億條之多。這個已經遠遠超出正常RDBMS可以承受的範圍。
MongoDB基于記憶體緩存的資料管理方式決定了對并發讀寫的響應可以做到很低延遲,水準擴充的方式可以通過多台節點同時并發處理海量請求。
事實上,全球最大的航空分銷商,管理者全世界95%航空庫存的Amadeus也正是使用MongoDB作為其1000多億運價緩存的存儲方案。
我們知道MongoDB可以用來做我們海量運價資料的存儲方案,在大規模并行計算方案上,就可以用到嶄新的Spark技術。
這裡是一個運價系統的架構圖。左邊是發起航班查詢請求的用戶端,首先會有API伺服器進行預處理。一般航班請求會分為庫存查詢和運價查詢。庫存查詢會直接到東航已有的庫存系統(Seat Inventory),同樣是實作在MongoDB上面的。在确定庫存後根據庫存結果再從Fare Cache系統内查詢相應的運價。
Spark叢集則是另外一套計算叢集,通過Spark MongoDB連接配接套件和MongoDB Fare Cache叢集連接配接。Spark 計算任務會定期觸發(如每天一次或者每4小時一次),這個任務會對所有的可能的運價組合進行全量計算,然後存入MongoDB,以供查詢使用。右半邊則把原來實時運算的叢集換成了Spark+MongoDB。Spark負責批量計算一年内所有航班所有倉位的所有價格,并以高并發的形式存儲到MongoDB裡面。每秒鐘處理的運價可以達到數萬條。
當來自用戶端的運價查詢達到服務端以後,服務端直接就向MongoDB發出按照日期,出發到達機場為條件的mongo查詢。
這裡是Spark計算任務的流程圖。需要計算的任務,也就是所有日期航班倉位的組合,事先已經存放到MongoDB裡面。
任務遞交到master,然後預先加載所需參考資料,broadcast就是把這些在記憶體裡的資料複制到每一個Spark計算節點的JVM,然後所有計算節點多線程并發執行,從Mongodb裡取出需要計算的倉位,調用東航自己的運價邏輯,得出結果以後,并儲存回MongoDB。
Spark和MongoDB的連接配接使用非常簡單,下面就是一個代碼示例:
這裡是一個在東航POC的簡單測試結果。從吞吐量的角度,新的API伺服器單節點就可以處理3400個并發的運價請求。在顯著提高了并發的同時,響應延遲則降低了10幾倍,平均10ms就可以傳回運價結果。按照這個性能,6台 API伺服器就可以應付将來每天16億的運價查詢。
接下來是一個簡單的Spark+MongoDB示範。
資料:365天,所有航班庫存資訊,500萬文檔
任務:按航班統計一年内所有餘票量
任務:按航班統計一年内所有庫存,但是隻處理昆明出發的航班
使用合适的chunksize (MB)
Total data size / chunksize = chunks = RDD partitions = spark tasks
不要将所有CPU核配置設定給Spark
預留1-2個core給作業系統及其他管理程序
同機部署
适當情況可以同機部署Spark+MongoDB,利用本地IO提高性能
上面隻是一些簡單的示範,實際上Spark + MongoDB的使用可以通過Spark的很多種形式來使用。我們來總結一下Spark + Mongo的應用場景。在座的同學可能很多人已經使用了MongoDB,也有些人已經使用了Hadoop。我們可以從兩個角度來考慮這個事情:
對那些已經使用MongoDB的使用者,如果你希望在你的MongoDB驅動的應用上提供個性化功能,比如說像Yahoo一樣為你找感興趣的新聞,能夠在你的MongoDB資料上利用到Spark強大的機器學習或者流處理,你就可以考慮在MongoDB叢集上部署Spark來實作這些功能。
如果你已經使用Hadoop而且資料已經在HDFS裡面,你可以考慮使用Spark來實作更加實時更加快速的分析型需求,并且如果你的分析結果有資料量大、格式多變以及這些結果資料要及時提供給前台APP使用的需求,那麼MongoDB可以用來作為你分析結果的一個存儲方案。
--end--