0 引言
在高校教學過程中,考試是最為普遍的一種教學評估、綜合練習的教學手段,随着科技進步,考試閱卷的方式也發生了巨大的變革。傳統的閱卷方式主要以人工閱卷為主, 存在效率低下等不足; 現代的閱卷方式采用了光學标記識别(Optica Mark Recognition, OMR) 技術, 考生隻需在答題卡上填塗, 計算機會通過對答題卡進行處理進而實作自動閱卷, 但這種方式需使用特别設計的答題卡與鉛筆,并且遵循一定的填塗規範。以上兩種方法均給老師、考生帶來了一定的限制,耗費了較多的時間;是以為了讓被試者靈活、高效的進行答題,對手寫體的字元識别進行研究十分有必要。
手寫體的字元識别按照采取的技術路線大體上分為兩類:一類是特征提取法;另一類是神經網絡法。特征提取法按照提取字元特征的不同又可分為兩類:一類是基于輪廓、結構特征的字元識别算法,這類算法通過識别字元圖像的輪廓特征、端點特征、凹凸結構特征等,對字元進行細化處理,采用模闆比對的方式實作手寫字元的自動識别。這類方式雖然能夠對字元的結構進行直覺地描述,但是對于噪聲及産生形變的字元不能很好的識别,缺乏魯棒性。
另一類是基于統計特征的手寫體字元識别算法,這類算法通過對大量的樣本訓練相應的分類器,并利用這些分類器對待識别字元進行分類。優點是當采樣樣本足夠充分時,這類方法能夠具有較好的識别效果;缺點就是往往不能構造足夠豐富的樣本。神經網絡法得到較高的識别率,但需要對大量樣本進行訓練,耗費較多時間,降低了識别的實時性;即使對神經網絡進行改進、優化,也沒有從根本上彌補其不足。
在考試中由于被試者的書寫風格不一造成了手寫字元的形态各異的特點,這就決定了在手寫字元的識别中單一方案不會得到很好的識别效果。試卷客觀題的評閱中,大多隻包含A、B、C、D四個字元,字元個數少,僅對A~D四個字元進行識别能夠得到較好的閱卷效率及較高的正确識别率。針對手寫英文字母的特點及應用場景,本文提出一種基于組合特征的手寫英文字母識别方法。該方法在輪廓特征提取的基礎上加入形狀特征提取,提取特征資訊簡單,同時不需要樣本訓練,是以提高了手寫英文字母的識别成功率與識别速度。
1 圖像預處理
由于手寫字元形狀存在風格不一的特點,且圖像拍攝時的光照變化、紙張整潔程度等都會使得字元圖像存在一定程度的噪聲,是以必須對圖像進行預處理,這樣便于對後面的字母切分和特征提取,提高最終的字母識别準确率。圖像預處理包括使用高斯濾波去除拍照裝置産生的高斯噪聲;對圖像進行二值化,使得圖像去掉背景;最後使用輪廓提取去除較大的噪點。
1.1 高斯濾波
數字圖像在擷取、傳輸的過程中都可能受到噪聲的污染,而錄影機傳感器内部元器件最容易産生的噪聲是高斯噪聲。高斯噪聲是指它的機率密度函數服從高斯分布的一類噪聲,對于此類噪聲常用的方法為高斯濾波。高斯濾波是一種線性平滑濾波,适用于消除高斯噪聲,廣泛應用于圖像處理的減噪過程。根據對測試樣本分别使用1×1、3×3、5×5的高斯核進行實驗發現,使用3×3高斯核的樣本實驗結果表現最好,是以本文選用3*3的高斯核對原始圖像進行高斯濾波。
1.2 圖像二值化
對圖像進行二值化處理是利用手寫字元區域與其背景存在灰階差異的特點,将手寫字元與背景以灰階區分開,便于後期的處理。常用的二值化算法有最大類間方差法(OTSU法) 、疊代法、Bers en、Niblack、簡單統計法、Niblack與模糊C均值法(Niblack and Fuzzy C-Means, NFC M) 等。OTSU法是一種自适應的門檻值确定的方法, 其基本思想是求取最佳門限門檻值,此門檻值将圖像灰階直方圖分割成黑白兩部分,使兩部分類間方差取得最大值,并使類内方內插補點最小,是以OTSU法也稱為最大類間方差法。本文圖像中的手寫英文字母與背景具有明顯的灰階差異, 是以采用OTSU法較為合适。圖1為圖像二值化過程。
圖1 圖像二值化
1.3 輪廓去噪
經過高斯濾波後,可以去除或者減少部分由攝像頭傳感器引起的噪聲,但是對于紙張本身存在的噪點處理效果達不到要求。在實際應用過程中,除字母以外的背景區域有可能會出現分布不均、不規則噪點,是以本文采用尋找連通域輪廓的方式,找到所有連通域的輪廓,并計算它們的輪廓面積,設定一個面積門檻值,輪廓面積小于門檻值的連通域可以判斷為噪點,将其剔除。經過大量實驗,本文設定将像素面積小于12的像素點去除。具體的輪廓提取方法在後文詳細叙述。圖2是輪廓去噪後的圖像。
2 字元分割
圖像的投影特征在圖像進行中是重要技術之一,一般是通過計算圖像在X軸或者Y軸的每個位置上的像素點(黑色或白色)總數量,并描繪出相應的投影曲線圖來分析圖像特征,該技術常用于圖像分割、字元檢測及提取等。公式(1)(2)分别是水準投影與垂直投影的計算公式。其中,h,w分别是二值化圖像的高度和寬度;f(i,j)為圖像第i行第j列元素的值1或0。
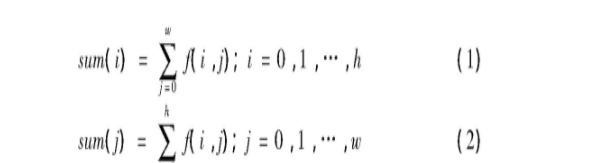
2.1 行分割
行分割就是對圖像X軸方向進行水準投影,得到X軸方向上每個位置的白點總數,若某個位置上的白點總數為0,則說明該位置沒有手寫痕迹。因為人們的常用書寫習慣是一行一行寫,且行與行之間存在一定距離,是以通過行分割就能知道哪些位置是沒有書寫過的,這樣就能大緻将手寫區域按行進行分割。

圖3 行分割過程
2.2 列分割
列分割就是對圖像Y軸方向進行垂直投影,得到Y軸方向上每個位置的白點總數,若某個位置上的白點總數為0,則說明該位置為字母間的間隙。通過列分割很容易地将每個字母提取出來進行後面的識别。
圖4 列分割過程
2.3 最小圖像分割
在進行過行分割與列分割後,基本将字母分割成單獨的圖像,但是此時的圖像往往尺寸較大,字母在整個圖像中所占比例較小,為了減少圖像處理時間,友善後面的字母識别,需要對分割後的字母再次進行切割,使得字母盡量占滿整個圖檔。圖5中的黑色邊框為圖像邊界。
圖5 最小圖像示意圖
3 分類識别
對于字母A~D很容易發現它們的輪廓特征,字母A、D包含一個閉合曲線;字母B包含2個閉合曲線;字母C包含0個閉合曲線,是以可以通過提取字母的閉合曲線數量對字母進行粗分,然後再對A、D進行區分。提取輪廓特征後接着提取形狀特征,将兩種特征的識别結果進行融合即可得到最後的識别結果
3.1 輪廓特征提取
輪廓提取在圖像進行中是常用方法之一,輪廓可以簡單認為成将連續的點連在一起的曲線,具有相同的顔色或者灰階。通過對二值圖像進行拓撲分析,對圖像進行行掃描,為不同的輪廓賦予不同的整數值,進而确定外輪廓、内輪廓以及它們的層級關系。如圖6有2個黑色輪廓,1a為第一個黑色輪廓的外邊界,1b為第一個黑色輪廓的孔邊界,2a為第二個黑色輪廓的外邊界,2b為第二個黑色輪廓的孔邊界。
圖6 輪廓示意圖
具體的操作是先對二值圖像進行行掃描,判斷像素點的像素值,用式(3)表示圖像的像素值,i是圖像的行數,j是圖像的列數。
當行掃描到輪廓的外邊界與孔邊界時,掃描終止,式(4)為外邊界終止條件,式(5)為孔邊界終止條件。以掃描終止時的f(i,j)為起點,标記邊界上的像素,給邊界賦予一個數值(如1),以後每次發現一個新邊界即在數值上加1,在圖6中有兩條輪廓,第一條輪廓的标記值為1,第二條輪廓标記值為2,這樣即完成了輪廓的檢測。
本文中,通過對分割後的手寫英文字母進行輪廓提取可以很容易地将A~D分為3類:輪廓數為0的有C;輪廓數為1的有
A、D;輪廓數為2的有B。
由于字母A、D具有相同的輪廓數,是以需要對兩個字母進行區分。通過對字母A、D的輪廓特征進行分析可以發現,對于同樣尺寸的字母A和字母D,A字母輪廓面積比D字母輪廓面積小;對于已是最小圖象的字母A和字母D,經過對182份手寫英文字母資料進行統計分析得到字母A輪廓面積占圖像面積的比例為0.075194884,字母D輪廓面積占圖像面積比例為0.321412412。由此可見,A字母輪廓面積占尺寸面積的比例小于字母D。是以在王識别中隻需對待識别的字母輪廓面積占比分别與字母A的占比系數和字母D的占比系數求內插補點,相比較即可判别A、D。圖7為字母A與字母D提取輪廓面積示意圖。
圖7 字母A與字母D輪廓面積提取示意圖
3.2形狀特征提取
通過對英文字母A~D的形狀進行分析可以找到各個字母的形狀特征,具體操作為:将預處理後得到的二值圖像(如圖8(a))進行填充,得到圖8(b),可以看出字母A的形狀近似三角形;字母B的形狀包含兩個凸起部分和一個凹進部分;字母C同樣包含兩個凸起部分和一個凹進部分;字母D隻有一個凸起部分。然後對圖8(b)進行水準投影将字母每行的像素和顯示在投影直方圖上(圖8©),對各個字母的像素和資料進行分析,可以得到字母A的資料曲線呈現單調遞增;字母B的資料曲線包含2個波峰一個波谷;字母C的資料曲線同樣包含2個波峰一個波谷;字母D的資料曲線包含1個波峰。
圖8 形狀特征提取過程
得到各個字母的資料後, 對資料曲線進行差分運算, 曲線的峰值點滿足一階導數為0, 二階導數為負;波谷點滿足一階導數為0, 二階導數為正;單調性曲線滿足一階導數不為0, 由此可以将字母區分為A、B和C、D三類。算法流程如下:資料曲線可以看作是一維向量如下:
其中, vi (i∈[1, 2, …, N]) 代表圖像在第i行上的白色像素和。計算V的一階差分向量Diffv:
得到差分向量後進行符号函數運算, 如式 (8) :
此時可以得到各點的變化情況,但是有些點值相同,卻不是波峰波谷,那麼再進行一次一階差分即可得到資料曲線的波峰或波谷點。
3.3特殊處理
由于在考試中難免出現答案填寫錯誤的情況,是以對于這種情況需要作特殊處理。本文在對字母識别的基礎上設計一種錯誤答案标注方式,對于填寫錯誤的答案,可在答案上從左至右劃2筆不重複的斜杠,從右至左劃2筆不重複的斜杠,如圖9所示,經過标注後的錯誤答案輪廓數會超出正常字母的輪廓數,這樣即可區分出填寫錯誤的答案。
圖9 特殊情況處理
1 matlab版本
2014a
2 參考文獻
[1] 蔡利梅.MATLAB圖像處理——理論、算法與執行個體分析[M].清華大學出版社,2020.
[2]楊丹,趙海濱,龍哲.MATLAB圖像處理執行個體詳解[M].清華大學出版社,2013.
[3]周品.MATLAB圖像處理與圖形使用者界面設計[M].清華大學出版社,2013.
[4]劉成龍.精通MATLAB圖像處理[M].清華大學出版社,2015.