了解Python
Python具有豐富和強大的庫。它常被昵稱為膠水語言,能夠把用其他語言制作的各種子產品(尤其是C/C++)很輕松地聯結在一起。常見的一種應用情形是,使用Python快速生成程式的原型(有時甚至是程式的最終界面),然後對其中[3] 有特别要求的部分,用更合适的語言改寫,比如3D遊戲中的圖形渲染子產品,性能要求特别高,就可以用C/C++重寫,而後封裝為Python可以調用的擴充類庫。需要注意的是在您使用擴充類庫時可能需要考慮平台問題,某些可能不提供跨平台的實作。
由于Python語言的簡潔性、易讀性以及可擴充性,在國外用Python做科學計算的研究機構日益增多,一些知名大學已經采用Python來教授程式設計課程。例如卡耐基梅隆大學的程式設計基礎、麻省理工學院的計算機科學及程式設計導論就使用Python語言講授。衆多開源的科學計算軟體包都提供了Python的調用接口,例如著名的計算機視覺庫OpenCV、三維可視化庫VTK、醫學圖像處理庫ITK。而Python專用的科學計算擴充庫就更多了,例如如下3個十分經典的科學計算擴充庫:NumPy、SciPy和matplotlib,它們分别為Python提供了快速數組處理、數值運算以及繪圖功能。是以Python語言及其衆多的擴充庫所構成的開發環境十分适合工程技術、科研人員處理實驗資料、制作圖表,甚至開發科學計算應用程式。
說起科學計算,首先會被提到的可能是MATLAB。然而除了MATLAB的一些專業性很強的工具箱還無法替代之外,MATLAB的大部分常用功能都可以在Python世界中找到相應的擴充庫。和MATLAB相比,用Python做科學計算有如下優點:
● 首先,MATLAB是一款商用軟體,并且價格不菲。而Python完全免費,衆多開源的科學計算庫都提供了Python的調用接口。使用者可以在任何計算機上免費安裝Python及其絕大多數擴充庫。
● 其次,與MATLAB相比,Python是一門更易學、更嚴謹的程式設計語言。它能讓使用者編寫出更易讀、易維護的代碼。
● 最後,MATLAB主要專注于工程和科學計算。然而即使在計算領域,也經常會遇到檔案管理、界面設計、網絡通信等各種需求。而Python有着豐富的擴充庫,可以輕易完成各種進階任務,開發者可以用Python實作完整應用程式所需的各種功能。
Python的作者有意的設計限制性很強的文法,使得不好的程式設計習慣(例如if語句的下一行不向右縮進)都不能通過編譯。其中很重要的一項就是Python的縮進規則。
一個和其他大多數語言(如C)的差別就是,一個子產品的界限,完全是由每行的首字元在這一行的位置來決定的(而C語言是用一對花括号{}來明确的定出子產品的邊界的,與字元的位置毫無關系)。這一點曾經引起過争議。因為自從C這類的語言誕生後,語言的文法含義與字元的排列方式分離開來,曾經被認為是一種程式語言的進步。不過不可否認的是,通過強制程式員們縮進(包括if,for和函數定義等所有需要使用子產品的地方),Python确實使得程式更加清晰和美觀。
Python的設計哲學是“優雅”、“明确”、“簡單”。
Python是完全面向對象的語言。函數、子產品、數字、字元串都是對象。并且完全支援繼承、重載、派生、多繼承,有益于增強源代碼的複用性。Python支援重載運算符和動态類型。相對于Lisp這種傳統的函數式程式設計語言,Python對函數式設計隻提供了有限的支援。有兩個标準庫(functools, itertools)提供了Haskell和Standard ML中久經考驗的函數式程式設計工具。
編輯
Python在執行時,首先會将.py檔案中的源代碼編譯成Python的byte code(位元組碼),然後再由Python Virtual Machine(Python虛拟機)來執行這些編譯好的byte code。這種機制的基本思想跟Java,.NET是一緻的。然而,Python Virtual Machine與Java或.NET的Virtual Machine不同的是,Python的Virtual Machine是一種更進階的Virtual Machine。這裡的進階并不是通常意義上的進階,不是說Python的Virtual Machine比Java或.NET的功能更強大,而是說和Java 或.NET相比,Python的Virtual Machine距離真實機器的距離更遠。或者可以這麼說,Python的Virtual Machine是一種抽象層次更高的Virtual Machine。
基于C的Python編譯出的位元組碼檔案,通常是.pyc格式。
除此之外,Python還可以以互動模式運作,比如主流作業系統Unix/Linux、Mac、Windows都可以直接在指令模式下直接運作Python互動環境。直接下達操作指令即可實作互動操作。
Python是一門跨平台的腳本語言,Python規定了一個Python文法規則,實作了Python文法的解釋程式就成為了Python的解釋器。
Python的設計目标之一是讓代碼具備高度的可閱讀性。它設計時盡量使用其它語言經常使用的标點符号和英文單字,讓代碼看起來整潔美觀。它不像其他的靜态語言如C、Pascal那樣需要重複書寫聲明語句,也不像它們的文法那樣經常有特殊情況和意外。
Python開發者有意讓違反了縮進規則的程式不能通過編譯,以此來強制程式員養成良好的程式設計習慣。并且Python語言利用縮進表示語句塊的開始和退出(Off-side規則),而非使用花括号或者某種關鍵字。增加縮進表示語句塊的開始,而減少縮進則表示語句塊的退出。縮進成為了文法的一部分。例如if語句:
python3
<col>
1
2
3
4
<code>if</code> <code>age<21:</code>
<code> print("</code><code>你不能買酒。")</code>
<code> print("</code><code>不過你能買口香糖。")</code>
<code>print("</code><code>這句話在if語句塊的外面。")</code>
根據PEP的規定,必須使用4個空格來表示每級縮進(不清楚4個空格的規定如何,在實際編寫中可以自定義空格數,但是要滿足每級縮進間空格數相等)。使用Tab字元和其它數目的空格雖然都可以編譯通過,但不符合編碼規範。支援Tab字元和其它數目的空格僅僅是為相容很舊的的Python程式和某些有問題的編輯程式。
Python使用and, or, not表示邏輯運算。
is, is not用于比較兩個變量是否是同一個對象。in, not in用于判斷一個對象是否屬于另外一個對象。
Python的函數支援遞歸、預設參數值、可變參數,但不支援函數重載。為了增強代碼的可讀性,可以在函數後書寫“文檔字元串”(Documentation Strings,或者簡稱docstrings),用于解釋函數的作用、參數的類型與意義、傳回值類型與取值範圍等。可以使用内置函數help()列印出函數的使用幫助。比如:
>>> def randint(a, b):
... "Return random integer in range [a, b], including both end points."...
>>> help(randint)
Help on function randint in module __main__:
randint(a, b)
Return random integer inrange[a, b], including both end points.
使用Python建立第一個CGI程式,檔案名為hello.py,檔案位于/var/www/cgi-bin目錄中,内容如下,修改檔案的權限為755:[5]
5
6
7
8
9
10
<code>#!/usr/bin/env python</code>
<code>print("Content-type:text/html\r\n\r\n")</code>
<code>print("<html>")</code>
<code>print("<head>")</code>
<code>print("")</code>
<code>print("</head>")</code>
<code>print("<body>")</code>
<code>print("<h2>Hello World! This is my first CGI program</h2>")</code>
<code>print("</body>")</code>
<code>print("</html>")</code>
以上程式在浏覽器通路顯示結果如下:
<code>Hello World! This is</code> <code>my first CGI program</code>
這個的hello.py腳本是一個簡單的Python腳本,腳本第一的輸出内容"Content-type:text/html\r\n\r\n"發送到浏覽器并告知浏覽器顯示的内容類型為"text/html"。
1,http://www.python.org/download/ 下載下傳windows安裝包,
2,python環境變量配置
(1)設定環境變量:我的電腦-右鍵-屬性-進階-環境變量 在Path中加入
;c:\python26 (注意前面的分号和路徑)
(2)此時,還是隻能通過"python *.py"運作python腳本,若希望直接運作*.py,隻需再修改另一個環境變量PATHEXT:
cmd進入指令行 輸入python –v 若是輸出版本資訊,則表示安裝完畢
4,建一個hello.py
5,cmd 進入指令行 找到檔案路徑 hello.py
會輸出"hello world"
6,接受使用者輸入
簡單的‘Hello World!’
假設你已經安裝好了Python, 那麼在Linux指令行輸入:
$python
将直接進入python。然後在指令行提示符>>>後面輸入:
>>>print('Hello World!')
可以看到,随後在螢幕上輸出:
print是一個常用函數,其功能就是輸出括号中得字元串。
(在Python 2.x中,print還可以是一個關鍵字,可寫成print 'Hello World!',但這在3.x中行不通 )
另一個使用Python的方法,是寫一個Python程式。用文本編輯器寫一個.py結尾的檔案,比如說hello.py
在hello.py中寫入如下,并儲存:
退出文本編輯器,然後在指令行輸入:
$python hello.py
來運作hello.py。可以看到Python随後輸出
我們還可以把Python程式hello.py改成一個可執行的腳本,直接執行:
需要修改上面程式的權限為可執行:
然後再指令行中,輸入
就可以直接運作了
指令行模式: 運作Python,在指令行輸入指令并執行。
程式模式: 寫一段Python程式并運作。
相當于不用編譯,可以直接執行的就是腳本。
28原則吧 80%精力學習c++ 20精力學習一門腳本語言
主要看樓主以後方向吧 如果是網絡安全python肯定需要 如果是遊戲可以先學lua
光學習語言是不行的 多看看優秀的源碼的 openresty skynet stl
對于python可以先過書 幾天搞定一個進階話題 如裝飾器 疊代器 協程 元類
學一門學累了 看看csapp 算法導論 挺好
目測糾結的時間都足夠學個七七八八了。
python和c++面對的領域不同,特點不同,都學了也沒壞處。
何況程式設計這事,重要的是思想,不是語言。
要完成一些成規模的項目,軟體架構與性能都必不可少。C++正是為此而生,在盡量不犧牲性能的情況下,提供高層次抽象所需的功能。畢竟C所缺少的命名空間、進階資料結構等,使其完成大規模項目是有一定困難的。
不過C++并不是解決該問題的唯一方案。很多其他方案并不專注于同時確定兩點,而是将目标集中于更好的軟體架構,以及可以接受的性能。Python、Lua等很多語言都是如此。而同時,對于要求性能較高的部分,或者與系統結合緊密的部分,則是交給C子產品去處理。這樣的思路對大型項目是很有利的,架構方面因為有進階語言的支援而得到了更好的抽象,更容易實作複雜的邏輯。而循環次數較多的部分則交給C去處理。尤其是引入進階語言後,可以迫使人們将傳遞的資料交給進階語言,而不是C裡随處使用全局變量。
是以,以實用的角度講,Python+C是更好的選擇。另外就是C++為了尋求性能與架構的折中而不得不引入很多概念,這些概念使得C++比C要複雜很多,同時其對架構的支援能力卻又比進階語言查一截。
總的來說,我的建議是:
1. 學Python,反正很快
2. 學好C,結合具體的系統與函數庫
3. 學Python與C結合的方法,比如Python的C子產品、Cython、Swig等多種方式
4. 學一點C++文法,畢竟還是有一定機率會用到C++的庫,但不要在那些奇怪的C++功能上浪費時間
之前一直在學C,C++,還有一些Java,抱着興趣去選了一個Python,當我看到老師敲得代碼後,我驚歎,Python還可以這樣,如果用C的話,不得麻煩死,而且在寫函數時沒有用大括号,靠縮進分層次,顯得特别整潔,這也是為什麼我第一次實驗課代碼總出問題的原因,那我想從今天開始總結一下Python與C++的不同。
一、頭檔案
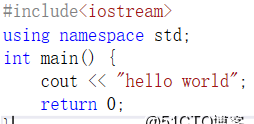
學一門語言的第一步就是輸出"hello world",如果是C++得這麼寫:
今天我們聊一下基本資料類型吧,
在學習c++的時候我們要記住幾種資料類型,int,float,double,long,char,double,string,bool,每次使用都要明确定義每個資料類型,這樣做是為了在記憶體裡申請指定大小的空間。
但是在Python中就有些不同了,比如我們在使用時直接拿出來不必指定他是什麼類型的
如,我們定義一個int類型的x,并指派等于3,
C++要這麼做,int x=3;
而Python則要這麼做 x=3,好像在寫一條數學公式,
但是這時我們想一個問題,我們在定義這個變量時,C++為x申請了4個位元組的空間,Python為x申請了多大的空間呢
我們就從淺淺的分析一下吧。
首先Python語言為動态類型,也就是說對象的類型和記憶體都是在運作時确定的,另外,Python還采用了Windows核心對象一樣的方式對記憶體進行管理,每一個對象都在維護這一個對指向該對象的引用的計數

這個就好比C++中的指針,定義了指針x,然後為x申請空間并指派3.14,然後在定義一個指針,指向x,這時x和y用的同一塊記憶體,代碼及結果如下:
最後我們在了解一下python記憶體的垃圾回收,
1、當記憶體中有不再使用的部分時,垃圾收集器就會把他們清理掉。它會去檢查那些引用計數為0的對象,然後清除其在記憶體的空間。當然除了引用計數為0的會被清除,還有一種情況也會被垃圾收集器清掉:當兩個對象互相引用時,他們本身其他的引用已經為0了。
2、垃圾回收機制還有一個循環垃圾回收器, 確定釋放循環引用對象(a引用b, b引用a, 導緻其引用計數永遠不為0)。
對比java和python
1.難易度而言。python遠遠簡單于java。
2.開發速度。Python遠優于java
3.運作速度。java遠優于标準python,pypy和cython可以追趕java,但是兩者都沒有成熟到可以做項目的程度。
4.可用資源。java一抓一大把,python很少很少,尤其是中文資源。
5.穩定程度。python3和2不相容,造成了一定程度上的混亂以及大批類庫失效。java由于有企業在背後支援是以穩定的多。
6.是否開源。python從開始就是完全開源的。Java由sun開發,但現在有GUN的Openjdk可用,是以不用擔心。
7.編譯還是解釋。兩者都是解釋型。
我了解,C好比手動擋車(編譯型語言),java和python(解釋型語言)好比自動檔車。跑的最快的車都是手動檔,但是對開不好的人來說,開自動檔反而更快些。
Kno有一篇文章談到選擇程式設計語言,“先确定你的需求”,不要由語言的簡單還是複雜去覺定。隻有能夠編寫你真正認為有用的程式,才能獲得滿足感,學習才能繼續。
那麼java和python分别适用于什麼樣的環境呢。由sourceforge.net可以看出:
最著名,久經考驗的普通應用程式,基本都是c++寫的。例如emule,7-zip,WinSCP,FileZilla等等等。
一部分由java開發,例如最有名的OpenOffice。
python寫的很少,如Pidgin,FireBird。
開發語言(有多少個程式由此語言開發)的排行如下:
# Java46,202
# C++36,895
# PHP30,048
# C28,075
# C#13,476
# Python13,379
# JavaScript11,285
# Perl9,216
# Unix Shell3,869
# Delphi/Kylix3,548
# Visual Basic3,186
# Visual Basic .NET
很多架構和類庫也和應用軟體一樣在這個清單裡,是以比較公平。
由此可以看出,java不管在GNU還是商業領域都是應用最廣的語言。C主要用于建構系統底層。c++和java用于建構中間應用層。如果資源足夠,那麼會選擇c++開發,以求運作速度,否則會用java開發,以求開發速度。python在各方面都比java優秀,可謂次世代語言。可最受争議的是它的速度,純python比java慢很多,以及背後沒有商業支援,穩定性備受诟病。目前為止,python在商業層次上,主要作為一種膠水語言,粘合其他語言(主要是c/c++)的類庫。在GNU領域,主要局限于小規模的應用和個人化應用。以及逆向工程(黑客)應用。
為什麼java在伺服器端被大量應用,在用戶端用的卻比較少呢。難道伺服器端用到的計算量反而少麼。我認為這說明對比c++,java的速度還是可以接受的。無法被接受的是JRE平台,以及JRE平台啟動時卡的那一會兒。我就曾經為此認為java寫就的程式性能低下。
python使用者常常拿來說嘴的一點是:python并不慢,因為python運作時調用了大量c庫,而c是很快的。反過來想想,這正反映了其膠水語言的事實,任何一種語言都可以調用c庫,這麼比較有價值麼?假如一個庫完全由python,那麼它的運作效率...不說也罷。程式設計不能總是用别人的庫啊。
----
Python程式設計語言目前的使用中需要不斷的學習。下面我們就詳細的看看如何才能更好的進行相關知識的學習。最近我一直在看一個基于wxPython的GUI應用程式代碼,大概45.5KLOC的左右,而且這還不包括它所用到的庫(如Twisted)。
代碼是由那些對Python比較生疏的Java的開發者寫的,是以它存在很嚴重的性能問題(如三十秒的啟動時間)。在檢查代碼的時候,我發現他們寫了很多在Java中能講得通但是對Python程式設計語言來說去卻是很難接受的東西。并不是因為“Python比Java慢”,而是因為在Python中有更友善的方法去完成同樣的目标,甚至是在Java中不可能的事情。
是以,令人難過的事就是這些家夥事倍功半,寫的那些代碼比本應合乎用Python程式設計語言實作的慢很多。下面,讓我們來看一些例子:
◆Java中的靜态方法不能翻譯成Python的類方法。哦,當然,他多多少少也能産生同樣的效果,但類方法的目的實際上是做一些通常在Java中甚至都不可能的事情(如繼承一個非預設的預設函數)。Java靜态方法慣用的翻譯通常翻譯成一個子產品級的函數,而不是一個類方法或靜态方法。(并且靜态常量應該翻譯成子產品級常量.)
這不是性能上的問題,但是一個Python程式設計語言程式員如果想調用Foo.someMethod,他要是被迫采用像Java中Foo.Foo.someMethod的方式去做的話,那麼他就會被逼瘋的。有一點一定要注意:調用一個類方法需要一個額外的存儲空間,而調用靜态方法或函數就不需要這樣.
對了,還有就是這些Foo.Bar.Baz的屬性鍊也不是自己就能數出來的.在Java中,這些帶點的名稱是有編譯器來查找的,運作的時候并不會去考慮一共有多少.而在Python中,查找的過程是在運作時進行的,是以要包括每個點.(在Python中,要記住一點,"平鋪的結構别嵌套的要好",盡管相對于從性能方面來說,可能它更多涉及的是"可讀性"和"簡單要比複雜好".)
◆要使用switch語句嗎?Python程式設計語言将是一個哈希表,不是一堆if-then語句。要使用在Java中不是switch語句而且還有字元串參與了的一堆if-then語句嗎?它将仍然是一個哈希表。CPython字典是用在我們所了解的領域中認為是最佳性能之一的哈希表來實作的。你自己所寫的代碼也不會比這個再好了,除非你是Guido、Tim Peters和Raymond Hettinger的私生子,而且還是遺傳增強了的。
◆XML不是答案。它也不是一個問題。現在用正規表達式來解釋Jamie Zawinski,“一些人,當他遇到一個問題的時候,就會想‘我知道,我要用XML.’那麼他們就有兩個問題了。”
相對于在Java中來說這是個不同的情況,因為比起Java代碼,XML是靈活而且有彈性的。但比起Python的代碼來,XML就是一個船錨,一個累贅。在Python中,XML是用來協同工作的,而不是你的核心功能,因為你不需要那麼做。在Java中,XML可能是你的救世主,因為它讓你實作了特定領域的語言并且“不用編碼”就提高你的應用程式的适應性。在Java中,避免編碼是一個很大的優勢,因為編碼意味着重新編譯。但在Python中,通常是,寫代碼比寫XML更簡單。還有就是Python處理代碼要比處理XML快很多很多。(不僅僅是這個,你必須寫XML處理代碼,同時Python就已經為你寫好了.)
如果你是一個Java程式員,你并不能利用本能知覺來考慮你是否要在你的Python核心應用中使用XML作為一部分。如果你不是因為資訊互動的原因去實作一個已經存在的XML标準或是建立某種輸入、輸出格式或者建立某種XML編輯器或處理工具,那麼就不要這麼做。根本不要去這麼做。甚至連想都不要想。現在,丢掉那個XML模式然後把你的手解放出來吧!如果你的應用程式或者平台要被Python程式設計語言開發者使用,他們隻會感謝你不要在他們的工作中添加使用XML的負擔。
(這裡唯一的例外是如果你的客戶(your target audience)确确實實因為某些原因而需要使用XML。就好像,他們拒絕學習Python但如果你使用XML他們就給你付錢,或者你打算給他們一個很棒的能編輯XML的GUI,還有就是這個XML的GUI是另一個人寫的,同時你得到免費使用的權利。還有一些很少見的架構上的原因需要用到XML。相信我,它們不會應用到你的程式中去的。如果有疑問,對一個資深的Python開發員解釋你的用例。或者,如果你臉皮厚而且不介意被人嘲笑的話,試試向一個Lisp程式解釋你的程式為什麼要用XML!)
◆Getter和setter是惡魔。我應該說它是惡魔,是魔鬼!Python程式設計語言對象不是Java Bean。不要寫什麼getter和setter,而是還把它們内置在“屬性”裡面。它直到你能證明你需要比一個簡單通路複雜一點的功能時才有意義,要不然,不要寫getter和setter。它們是CPU時間的浪費,更要緊的是,它們還是程式員寶貴時間的浪費。不僅僅對于寫代碼和測試的人,對于那些要閱讀和了解它們的人也是。
在Java中,你必須使用getter和setter,因為公共字段不允許你以後改變想法再去使用getter和setter。是以,在Java中你最好事先避開這些"家務雜事".在Python中,這樣做很傻,因為你可以以一個普通特性開始并可以在任何時間改變你的想法,而不用影響到這個類的任何客戶。是以不要寫getter和setter方法。
◆代碼重複在Java中通常來說就是一場不可避免的災禍,你必須經常反複地寫同一個方法而隻有一點點的變化(通常是這是因為靜态類型限制)。在Python中這樣做是沒有必要的也是不值得的(除了極少數一些特定的場合需要内聯一些要求性能的函數)。如果你發現自己一遍一遍在寫同樣的代碼而且變化很少,你就需要去學一下閉包。他們實際不并是那麼可怕。
對Python程式設計技巧大總結
簡讀靈活性的Python程式設計語言
短時間内掌握Python程式設計語言
對Python程式設計語言曆史說明介紹
有關Python程式設計語言進行描述
這就是你要做的。你寫了一個包含了函數的函數。這裡内部的函數就是你要一遍遍寫的函數的模版,但是在裡面加入了針對不同情況的函數要使用變量。外部的函數需要剛剛提高的那種變量作為參數,并且将内部的函數作為結果傳回。然後,每次你要寫另一種略微不同的函數的時候,你隻要調用這個外部的函數,并且把傳回值賦給你要讓“重複”函數出現的名字。現在,如果你需要改變這個工作方式,你隻需要改變一個地方:這個模版。
在我所看過的應用程式/平台中,隻有一個很微不足道的程式使用了這個技術,它去掉了數百行重負的代碼。實際上,因為開發者使用了特别的樣闆檔案來為這個平台開發插件,是以這會節省很多很多第三方開發人員的代碼,同時也使那些程式員要學習的東西變得簡單了。
這隻是Java->Python程式設計語言思維方式轉變的冰山一角而已,現在我能正确的轉變而不用去鑽研程式的細節。本質上,如果你曾經用過一段時間Java,而且對Python比較陌生,那麼你不要太相信自己的本能。你的本能已經被Java調節,而不是Python。向後退一步來說,最重要的是不要再寫這麼多代碼了。
為了這樣做,讓自己覺得更加需要Python。假裝好像Python是可以做任何你想做的魔棒,而你無須出一點力。問一下,“Python怎樣解決我的問題?”還有“Python語言的哪個特點和我的問題最相似?”如果對于你需要的東西其實已經有了某種固定形式,那麼你絕對會感到驚訝的。事實上,這種現象實在是太普遍了,甚至即使在很有經驗的Python程式員中也會出現,以至于Python社群中給這種現象起了個名字。我們稱之為“GUIDO的時間機器”,因為在我們自己還沒有掌握它之前,通常看上去要得到我們所需要的東西好像那是唯一的方法。
是以,如果你在使用Python程式設計語言時候不能感到比使用Java要至少多出10倍的生産力話,你就最好做一下改動,你是不是忘記使用time machine!(chances are good that you've been forgetting to use the timemachine)(同時如果你還懷念你的Java IDE,你可以這樣想:因為你寫的Python程式比他所需要的要複雜得多.)
首先,要通過urllib2這個Module獲得對應的HTML源碼。
import urllib2 #調用urllib2
url='http://www.baidu.com/s?wd=cloga' #把等号右邊的網址指派給url
html=urllib2.urlopen(url).read() #html随意取名 等号後面的動作是打開源代碼頁面,并閱讀
print html #列印
通過上面這三句就可以将URL的源碼存在content變量中,其類型為字元型。
接下來是要從這堆HTML源碼中提取我們需要的内容。用Chrome檢視一下對應的内容的代碼(也可以用Firefox的Firebug)。
可以看到url的資訊存儲在span标簽中,要擷取其中的資訊可以用正則式。
在我們日常上網浏覽網頁的時候,經常會看到一些好看的圖檔,我們就希望把這些圖檔儲存下載下傳,或者使用者用來做桌面桌面,或者用來做設計的素材。
我們最正常的做法就是通過滑鼠右鍵,選擇另存為。但有些圖檔滑鼠右鍵的時候并沒有另存為選項,還有辦法就通過就是通過截圖工具截取下來,但這樣就降低圖檔的清晰度。好吧~!其實你很厲害的,右鍵檢視頁面源代碼。
我們可以通過python 來實作這樣一個簡單的爬蟲功能,把我們想要的代碼爬取到本地。下面就看看如何使用python來實作這樣一個功能。
一,擷取整個頁面資料
首先我們可以先擷取要下載下傳圖檔的整個頁面資訊。
getjpg.py
#coding=utf-8
import urllib
def getHtml(url):
page = urllib.urlopen(url)
html = page.read()
return html
html =getHtml("http://tieba.baidu.com/p/2738151262")
print html
Urllib 子產品提供了讀取web頁面資料的接口,我們可以像讀取本地檔案一樣讀取www和ftp上的資料。首先,我們定義了一個getHtml()函數:
urllib.urlopen()方法用于打開一個URL位址。
read()方法用于讀取URL上的資料,向getHtml()函數傳遞一個網址,并把整個頁面下載下傳下來。執行程式就會把整個網頁列印輸出。
二,篩選頁面中想要的資料
Python 提供了非常強大的正規表達式,我們需要先要了解一點python 正規表達式的知識才行。
javascript:void(0)
假如我們百度貼吧找到了幾張漂亮的桌面,通過到前段檢視工具。找到了圖檔的位址,如:src=”http://imgsrc.baidu.com/forum......jpg”pic_ext=”jpeg”
修改代碼如下:
import re
def getImg(html):
reg = r'src="(.+?\.jpg)" pic_ext'
imgre = re.compile(reg)
imglist = re.findall(imgre,html)
return imglist
html =getHtml("http://tieba.baidu.com/p/2460150866")
print getImg(html)
我們又建立了getImg()函數,用于在擷取的整個頁面中篩選需要的圖檔連接配接。re子產品主要包含了正規表達式:
re.compile() 可以把正規表達式編譯成一個正規表達式對象.
re.findall() 方法讀取html 中包含 imgre(正規表達式)的資料。
運作腳本将得到整個頁面中包含圖檔的URL位址。
三,将頁面篩選的資料儲存到本地
把篩選的圖檔位址通過for循環周遊并儲存到本地,代碼如下:
x = 0
for imgurl in imglist:
urllib.urlretrieve(imgurl,'%s.jpg' % x)
x+=1
這裡的核心是用到了urllib.urlretrieve()方法,直接将遠端資料下載下傳到本地。
通過一個for循環對擷取的圖檔連接配接進行周遊,為了使圖檔的檔案名看上去更規範,對其進行重命名,命名規則通過x變量加1。儲存的位置預設為程式的存放目錄。
程式運作完成,将在目錄下看到下載下傳到本地的檔案。