作者:楊勇,吳一昊
本小節講述為什麼使用 CPI 分析程式性能的意義。如果已經非常了解 CPI 對分析程式性能的意義,可以跳過本小節的閱讀。
了解什麼是 CPI,首先讓我們思考一個問題:在一個給定的處理器上,如何才能讓程式跑得更快呢?
假設程式跑得快慢的标準是程式的執行時間,那麼程式執行的快慢,就可以用如下公式來表示:
是以,要想程式跑得快,即減少程式執行時間,我們就需要在以下三個方面下功夫:
減少程式總指令數
要減少程式執行的總指令數,可能有以下手段:
算法優化;好的算法設計,可能帶來更少的指令執行數
更高效的編譯器或者解釋器;新的編譯器或者解釋器,可能對同樣的源代碼,生成更少的機器碼。
用更底層的語言優化;這是為何 Linux 核心代碼使用 C 語言,并且還喜歡内聯彙編。
更新的處理器指令;新的處理器指令,對處理某類特殊目的運算更有幫助,而新版本編譯器最重要的工作就是,在新的處理器上,用最新的高效指令;例如,x86 SSE,AVX 指令。
減少每 CPU 時鐘周期時間
這一點很容易了解,縮短 CPU 時鐘周期的時間,實際上就是要提高 CPU 的主頻。這正是 Intel 過去占無不勝的法寶之一。今天,由于主頻的提高已經到了制造技術的極限,CPU 時鐘周期的時間很難再繼續降低了。
減少每指令執行所需平均時鐘周期數
如何減少每指令執行所需平均 CPU 時鐘周期數呢?讓我們先從 CPU 設計角度看一下:
标量處理器 (Scalar Processor) ;一個 CPU 時鐘周期隻能執行一條指令;
超标量處理器 (Superscalar Processor);一個 CPU 時鐘周期可以執行多條指令;通常這個是靠在處理器裡實作多級流水線 (Pipeline) 來實作的。
是以不難看出,如果使用支援超标量處理器的 CPU,利用 CPU 流水線提高指令并行度,那麼就可以達到我們的目的了。流水線的并行度越高,執行效率越高,那麼每指令執行所需平均時鐘周期數就會越低。
當然,流水線的并行度和效率,又取決于很多因素,例如,取值速度,訪存速度,指令亂序執行 (Out-Of-Order Execution),分支預測執行 (Branch Prediction Execution),投機執行 (Speculative Execution)的能力。一旦流水線并行執行的能力降低,那麼程式的性能就會受到影響。關于超标量處理器,流水線,亂序執行,投機執行的細節,這裡不再一一贅述,請查閱相關資料。
另外,在 SMP,或者多核處理器系統裡,程式還可以通過并行程式設計來提高指令的并行度,是以,這也是為什麼今天在 CPU 主頻再難以提高的情況下,CPU 架構轉為 Multi-Core 和 Many-Core。
由于提高 CPU 主頻的同時,又要保障一個 CPU 時鐘周期可以執行更多的指令,是以需要處理器廠商需要不斷地提高制造技術,降低 CPU 的晶片面積和功耗。
在計算機體系結構領域,經常可以看到 CPI 的使用。CPI 即 Cycle Per Instruction 的縮寫,它的含義就是每指令周期數。此外,在一些場合,也可以經常看到 IPC,即 Instruction Per Cycle 的,含義為每周期指令數。
是以不難得出,CPI 和 IPC 的關系為,
使用 CPI 這個定義,本文開篇用于衡量程式執行性能的公式實際上可以表示為:
由于受到矽材料和制造技術的限制,處理器主頻的提高已經面臨瓶頸,是以,程式性能的提高,主要的變量在 Instruction Count 和 CPI 這兩個方面。
在 Linux 上,通過 <code>perf</code> 工具,通過 Intel 處理器提供的特殊寄存器,可以很容易測量一個程式的 IPC。
例如,下例就可以給出 Java 程式的 IPC,8 秒多的時間裡,這個 Java 程式的 IPC 是 0.54:
那麼,通過 IPC,我們也可以換算出 CPI 是 <code>1/0.54</code>,約為 1.85.
通常情況下,通過 CPI 的取值,我們可以大緻判斷一個計算密集型任務,到底是 CPU bound 還是 Memory Bound:
CPI 小于 1,程式通常是 CPU Bound;
CPI 大于 1,程式通常是 Memory Bound;
對程式員來說,判斷一個計算密集型任務運作效率的重要依據就是看程式運作時的 CPU 使用率。很多人認為 CPU 使用率高就是程式的代碼在瘋狂運作。實際上,CPU 使用率高,也有可能是 CPU 正在忙等一些資源,如通路記憶體遇到了瓶頸。
一些計算密集型任務,在正常情況下,CPI 很低,性能原本很好。CPU 使用率很高。但是随着系統負載的增加,其它任務對系統資源的争搶,導緻這些計算任務的 CPI 大幅上升,性能下降。而此時,很可能 CPU 使用率上看,還是很高的,但是這種 CPU 使用率的高,實際上展現的是 CPU 的忙等,及流水線的停頓帶來效應。
至此,相信讀者已經清楚,在不修改二進制程式的前提下,通過 CPI 名額了解程式的運作性能,有着非常重要的意義。對于計算密集型的程式,隻通過 CPU 使用率這樣的傳統名額,也無法幫助你确認你的程式的運作效率,必須将 CPU 使用率和 CPI/IPC 結合起來看,确定程式的執行效率。
雖然利用 <code>perf</code> 可以很友善擷取 CPI/IPC 名額,但是想分析和優化程式高 CPI 的問題,就需要一些工具和分析方法,将 CPI 高的原因,以及與之關聯的軟體的調用棧找到,進而決定優化方向。
關于 CPI 高的原因分析,在 Intel 64 and IA-32 Architectures Optimization Reference Manual, 附錄 B 裡有介紹。其中主要的思路就是按照自頂向下的方法,自頂向下排查, 4 種引起 CPI 變高的主要原因,
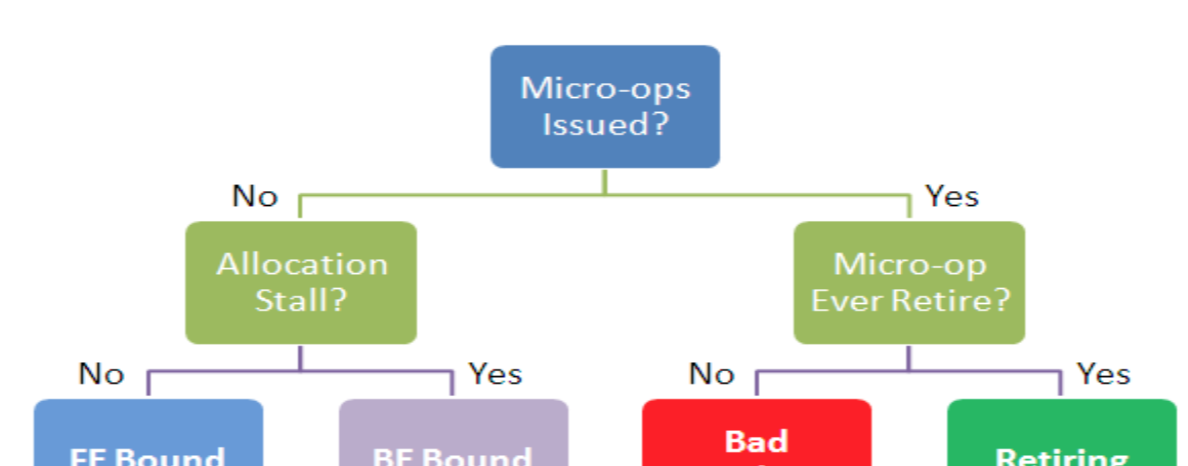
我們稍後會在另一篇文章介紹這種分析方法,本文主要關注使用 CPI 火焰圖來分析 CPI 的問題。
我們已經知道,光看 CPU 使用率并不能知道 CPU 在幹嘛。因為 CPU 可能執行到一條指令就停下來,等待資源了。這種等待對軟體是透明的,是以從使用者角度看,CPU 還是在被使用狀态,但是實際上,指令并沒有有效地執行,CPU 在忙等,這種 CPU 使用率并不是有效的使用率。
要發現 CPU 在 busy 的時候實際上在幹什麼,最簡單的方法就是測量平均 CPI。CPI 高說明運作每條指令用了更多的周期。這些多出來的周期裡面,通常是由于流水線的停頓周期 (Stalled Cycles) 造成的,例如,等待記憶體讀寫。
而 CPI 火焰圖,可以基于 CPU 火焰圖,提供一個可視化的基于 CPU 使用率和 CPI 名額,綜合分析程式 CPU 執行效率的方案。
下面這個 CPI 火焰圖引用自 Brendan Gregg 部落格文章。可以看到,CPI 火焰圖是基于 CPU 火焰圖,根據 CPI 的大小,在每個條加上了顔色。紅色代表指令,藍色代表流水線的停頓:

火焰圖中,每個函數幀的寬度,顯示了函數或其子函數在 CPU 上的次數,和普通 CPU 火焰圖完全一樣。而顔色則顯示了函數此時在 CPU 上是運作 (running 紅色) 還是停頓 (stalled 藍色)。
火焰圖裡,顔色範圍,從最高CPI為藍色(執行最慢的指令),到最低CPI為紅色 (執行最快的指令)。火焰圖是 SVG 格式,矢量圖,是以支援滑鼠點選縮放。
然而,Brendan Gregg 部落格中的這篇部落格,CPI 火焰圖是基于 FreeBSD 作業系統特有的指令生成的,而在 Linux 上,應該怎麼辦呢?
讓我們寫一個人造的小程式,展示在 Linux 下 CPI 火焰圖的使用。
這是一個最簡的小程式,其中包含如下兩個函數:
<code>cpu_bound</code>
<code>memory_bound</code>
下面是程式的源碼:
在上述小程式運作時,我們使用如下指令生成 CPI 火焰圖,
最後生成的火焰圖如下,
可以看到,CPI 火焰圖看到的結果,是符合我們的預期的:
該程式所有的 CPU 時間,都分布在 <code>cpu_bound</code> 和 <code>memory_bound</code> 兩個函數裡
同是 CPU 占用時間,但 <code>cpu_bound</code> 是紅色的,代表這個函數的指令在 CPU 上一直持續運作
而 <code>memory_bound</code> 是藍色的,代表這個函數發生了嚴重的通路記憶體的延遲,導緻了流水線停頓,屬于忙等
現在,我們可以使用 CPI 火焰圖來分析一個略真實一些的測試場景。下面的 CPI 火焰圖,來自 <code>fio</code> 的測試場景。
這個 <code>fio</code> 對 SATA 磁盤,做多程序同步 Direct IO 順序寫,可以看到:
紅顔色為标記為 CPU Bound 的函數。其中顔色最深的是 <code>_raw_spin_lock</code>,這是自旋鎖的等待循環引起的。
藍顔色為标記為 Memory Bound 的函數。其中顔色最深的是 <code>fio</code> 測試程式的函數 <code>get_io_u</code>,如果使用 <code>perf</code> 程式進一步分析,這個函數裡發生了嚴重的 LLC Cache Miss。
因為 CPI 火焰圖是矢量圖,支援縮放,是以以上結論可以通過放大 <code>get_io_u</code> 的調用棧進一步确認,
到這裡,讀者會發現,使用 CPI 火焰圖,可以很友善地做 CPU 使用率的分析,找到和定位引發 CPU 停頓的函數。一旦找到相關的函數,就可以通過 <code>perf annotate</code> 指令對引起停頓的指令作出進一步确認。并且,我們可以利用 <code>1.4</code> 小節的自頂向下分析方法,對 CPU 哪個環節産生瓶頸作出判斷。最後,結合這些資訊,決定優化方向。
本文介紹了使用 CPI 火焰圖分析程式性能的方法。CPI 火焰圖不但展示了程式的 Call Stack 與 CPU 占用率的關聯性,而且還揭示了這些 CPU 占用率裡,哪些部分是真正的有效的運作時間,哪些部分實際上是 CPU 因某些停頓造成的忙等。
系統管理者可以通過此工具發現系統存在的資源瓶頸,并且通過一些系統管理指令來緩解資源的瓶頸;例如,應用間的 Cache 颠簸幹擾,可以通過将應用綁到不同的 CPU 上解決。
而應用開發者則可以通過優化相關函數,來提高程式的性能。例如,通過優化代碼減少 Cache Miss,進而降低應用的 CPI 來減少處理器因訪存停頓造成的性能問題。
由于本文主要是介紹 CPI 火焰圖,對于 <code>1.4</code> 小節提到的自頂向下的分析方法,限于篇幅所限,這裡不詳細展開了。關于此内容,我們稍後會有專門的文章做詳細介紹。