随着越來越多的現代機器學習任務都需要使用GPU,了解不同GPU供應商的成本和性能trade-off變得至關重要。
初創公司Rare Technologies最近釋出了一個超大規模機器學習基準,聚焦GPU,比較了幾家受歡迎的硬體提供商,在機器學習成本、易用性、穩定性、可擴充性和性能等方面的性能。
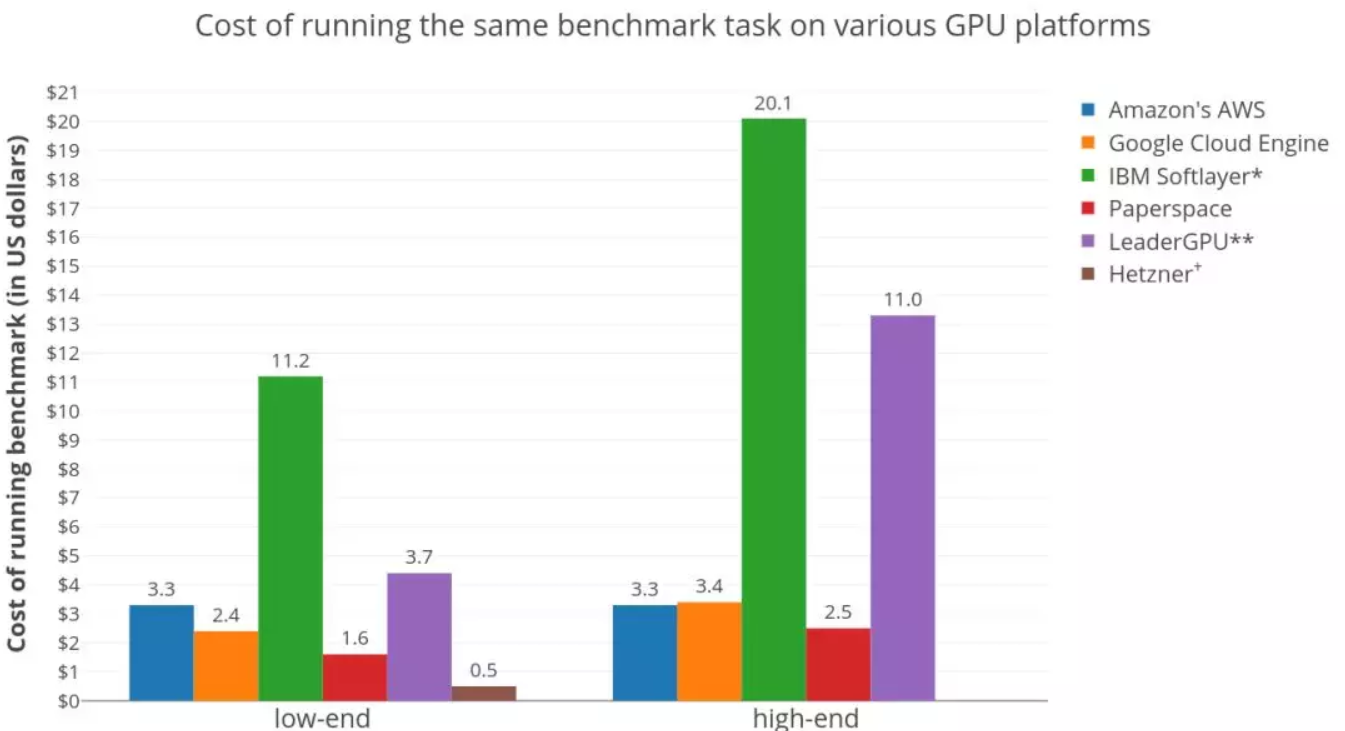
在6大GPU硬體平台上,執行Twitter情緒分類任務(大約150萬條推文,4個時期),訓練雙向LSTM的成本。由上圖可知,專用伺服器是控制成本的最佳選擇。
這項基準測試橫向比較了以下硬體平台:亞馬遜AWS EC2,谷歌Google Cloud Engine GCE,IBM Softlayer,Hetzner,Paperspace,以及LeaderGPU,這些硬體提供商都在這項測試期間提供了credits和支援。基準釋出時,微軟Azure官方還沒有回應,是以很遺憾沒有納入比較。
不過,這項測試還是涵蓋各種不同類型的GPU平台:提供虛拟機的(AWS,GCE),裸機基礎設施(Softlayer),專用伺服器(Hetzner)和專門提供GPUaaS的(LeaderGPU,Paperspace),也算很全面。研究人員也表示,他們希望通過測試,看看高端GPU是否更真的值價。
先說結果,經過這個測試後他們發現:

*這些是多GPU執行個體的結果,使用multi_gpu_model的multi_gpu_model函數在所有GPU上訓練模型,後來發現對多GPU使用率不足。
**由于上述原因,這些GPU模型僅使用多GPU種的其中一個進行訓練。
+ Hzzner是按月收費,提供專用伺服器。
基準設定:Twitter文本情緒分類任務
接下來,我們将詳細讨論和比較所有的平台,以及這項測試的情況。
任務 這項基準使用的是情緒分類任務(sentiment classification task [1])。具體說,訓練雙向LSTM來對Twitter的推文做二進制分類。算法的選擇并不是很重要,作者Shiva Manne表示,他對這個基準測試的唯一真正要求,是這項任務是否應該是GPU密集型的。為了確定GPU的最大使用率,他使用了由CuDNN( CuDNNLSM層)支援的Keras快速LSTM實作。
資料集 Twitter情緒分析資料集(Twitter Sentiment Analysis Dataset [2]),包含1,578,627條分過類的推文,每行用“1”标記為積極情緒,“0”表示消極情緒。模型對90%(shuffled)資料進行了4個epoch的訓練,剩下的10%用于模型評估。
Docker 為了可重複性,他們建立了一個Nvidia Docker鏡像 ,其中包含重新運作此基準測試所需的所有依賴項和資料。Dockerfile和所有必需的代碼可以在這個Github[3]庫中找到。
訂購和使用:LeaderGPU、AWS、Paperspace尤其适合初學者
在LeaderGPU和Paperspace上的訂購過程非常順暢,沒有任何複雜的設定(settings)。與AWS或GCE相比,Paperspace和LeaderGPU的供應時間要稍長一些(幾分鐘)。
LeaderGPU,Amazon和Paperspace提供免費的深度學習機器圖像(Deep Learning Machine Images),這些圖像預安裝了Nvidia驅動程式,Python開發環境和Nvidia-Docker,基本上立即就能啟動實驗。這讓事情變得容易很多,尤其是對于那些隻希望嘗試機器學習模型的初學者。但是,為了評估定制執行個體滿足個性化需求的難易程度,Manne從零開始(除了LeaderGPU),設定了所有的東西。在這個過程中,他發現了各家平台常見的一些問題,例如NVIDIA驅動與安裝的gcc版本不相容,或者在安裝驅動之後,沒有證據表明正在運作程式,但GPU的使用率卻達到100%。
意外的是,在Paperspace低端執行個體(P6000)上運作Docker導緻錯誤,這是由由Docker上的Tensorflow是由源優化(MSSE,MAVX,MFMA)建構的,而Paperspace執行個體不支援。在沒有這些優化的情況下運作Docker可以解決這個問題。
至于穩定性,各家表現都很好,沒有遇到任何問題。
成本:專用伺服器是控制成本的最佳選擇;更便宜的GPU成本效益更高
不出所料,專用伺服器是控制成本的最佳選擇。這是因為Hetzner按月收費,這意味着每小時的價格非常低,而且這個數字是按比例分攤的。是以,隻要你的任務足夠多,讓伺服器不會閑着,選擇專用伺服器就是正确的。
在虛拟機供應商中,Paperspace是明顯的赢家。在低端GPU領域,在Paperspace上訓練模型的價格比AWS便宜兩倍($1.6 vs $3.3)。Paperspace進一步顯示了,在高端GPU部分也有類似的成本效益模式。
剛才你可能已經看過這張圖了,不過配合這裡讨論的話題,再看一次:
基準測試結果:在各種GPU硬體平台上對Twitter情緒分類任務(大約150萬條推文,4個時期)進行雙向LSTM訓練的成本。
在AWS和GCE之間,低端GPU是AWS稍貴($3.3 vs $2.4),但在高端GPU領域則反了過來($3.3 vs $3.4)。這意味着,選高端GPU,AWS可能更好,多付出的那部分價錢或許能收到回報。
需要指出,IBM Softlayer和LeaderGPU看起來很貴,主要是由于其多GPU執行個體的使用率不足。這項基準測試使用Keras架構進行,是以多GPU實作的效率驚人地低,有時甚至比同一台機器上運作的單個GPU更差。而這些平台都不提供單個的GPU執行個體。在Softlayer上運作的基準測試使用了所有可用的GPU,使用multi_gpu_model的multi_gpu_model函數,而multi_gpu_model上的測試隻使用了一個可用的GPU。這導緻資源利用不足,産生了很多的額外成本。
另外,LeaderGPU提供了更強大的GPU GTX 1080 Ti和Tesla V100,價格卻與GTX 1080和Tesla P100相同(每分鐘)。在這些伺服器上運作,肯定會降低整體成本。綜上,LeaderGPU在圖表中,低端GPU成本部分,實際上是相當合理的。如果你打算使用非Keras架構,更好地利用多個GPU時,記住這些很重要。
另外還有一個大趨勢,更便宜的GPU比更貴的GPU成本效益更高,這表明訓練時間的減少,并不能抵消總成本的增加。
使用Keras做多GPU訓練模型:加速難以預測
既然也說到了使用Keras訓練多GPU模型,就多說幾句。
很多學術界和産業界人士非常喜歡使用像Keras這樣的進階API來實作深度學習模型。Keras本身也很流行,接受度高,疊代更新也快,使用者會以為使用Keras就不需要任何額外處理,能加快轉換到多GPU模型。
但實際情況并非如此,從下圖可以看出。
加速相當難以預測,與“雙P100”伺服器上的單GPU訓練相比,“雙GTX 1080”伺服器顯然有了加速,但多GPU訓練卻花費了更長的時間。這種情況在一些部落格和Github issue中都有提出,也是Manne在調查成本過程中遇到的值得注意的問題。
模型精準度、硬體定價、現貨測評及最新體驗感受
模型精準度
我們在訓練結束時對模型最終的精度做了完整性測試,從表1可以看出,底層硬體/平台對訓練品質沒有影響,基準設定正确。
硬體定價
GPU價格變化頻繁,但目前AWS提供的K80 GPU(p2執行個體)起價為0.9美元/小時,以1秒為增量計費,而更強大且性能更高的Tesla V100 GPU(p3執行個體)起價為3.06美元/小時。資料傳輸、彈性IP位址和EBS優化執行個體等附加服務需要支付額外費用。 GCE是一種經濟的替代方案,它可以按照0.45美元/小時和1.46美元/小時的價格分别提供K80和P100。這些收費以一秒為增量,并通過基于折扣的使用有可觀的獎勵。盡管與AWS不同,它們需要附加到CPU執行個體(n1-standard-1,價格為0.0475美元/小時)。
Paperspace在低成本的聯盟中與GCE競争,專用GPU有Quadro M4000,0.4美元/小時,也有2.3美元/小時的Tesla V100。除了慣常的小時費外,他們還要收取月租費(每月5美元),服務包括儲存和維修。以毫秒為基礎的論文空間賬單,附加服務可以以補充成本獲得。 Hetzner每月僅提供一台配備GTX 1080的專用伺服器,并額外支付一次設定費用。
IBM Softlayer是市場上為數不多的每月和每小時提供帶有GPU的裸機伺服器的平台之一。它提供3個GPU伺服器(包含特斯拉M60s和K80s),起價為2.8美元/小時。這些伺服器具有靜态配置,這意味着與其他雲提供商相比,其定制可能性有限。以小時為機關的軟計算結果也是非常糟糕的,而且對于短時間運作的任務而言可能更昂貴。
LeaderGPU是一個相對較新的玩家,它提供了多種GPU(P100s,V100s,GTX1080s,GTX1080Ti)的專用伺服器。使用者可以利用按秒計費的每小時或每分鐘定價。伺服器至少有2個GPU,最多8個GPU,價格從0.02歐元/分鐘到0.08歐元/分鐘。
現貨/搶先執行個體
某些平台在其備用計算容量(AWS spot執行個體和GCE的搶先執行個體)上提供了顯着的折扣(50%-90%),盡管它們随時可能意外終止。這會導緻高度不可預測的訓練時間,因為不能保證執行個體何時再次啟動。對于可以處理這種終端但是有許多任務的應用程式來說,這很好,而時間限制的項目在這種情況下不會很好(特别是如果考慮浪費的勞動時間)。
在搶先執行個體上運作任務需要額外的代碼來優雅地處理執行個體的終止和重新啟動(檢查點/将資料存儲到永久磁盤等)。此外,價格波動可能導緻成本在很大程度上取決于基準運作時的産能供求。這将需要多次運作來平均成本。鑒于在完成基準測試時所花的時間有限,我沒有以現場/先發執行個體為基準。
體驗評論
Paperspace似乎在性能和成本方面領先一步,尤其适合希望深度學習技術的實驗在另一個基準測試中得出類似的結論。
專用伺服器(如LeaderGPU提供的伺服器)和裸機伺服器(如Hetzner)适合考慮長期使用這些資源(doh)的使用者。但請注意,由于在定制伺服器方面靈活性較差,是以請確定您的任務具有高度的CPU / GPU密集度以真正感受物超所值。
像Paperspace和LeaderGPU這樣的新玩家不應該被解雇,因為他們可以幫助削減大部分的成本。由于相關的慣性和轉換成本,企業可能不願意切換提供商,但這些小型平台絕對值得考慮。
AWS和GCE對于尋求與其他服務內建的使用者來說是非常棒的選擇(AI內建 - 亞馬遜的Rekognition,Google的Cloud AI)。
除非你計劃需要幾天完成任務,否則堅持一個低端的單個GPU執行個體是最好的選擇。
更高端的GPU運作更快,但實際上投資回報率更差。隻有在較短的訓練時間(較少的研發周期)比硬體成本更重要時,才應該選擇這些方案。
原文釋出時間為:2018-02-10
本文作者:Shiva Manne
本文來自雲栖社群合作夥伴新智元,了解相關資訊可以關注“AI_era”微信公衆号