提取碼:pdsx
tips 學完這一章你可以知道Kafka基本原理,
了解關鍵術語概念可以使用Kafka進行消息系統開發
通過Java語言來使用Kafka進行消息收發
Kafka最初是由LinkedIn公司采用Scala語言開發的一個多分區、多副本并且基于ZooKeeper協調的分布
式消息系統,現在已經捐獻給了Apache基金會。目前Kafka已經定位為一個分布式流式處理平台,它以
高吞吐、可持久化、可水準擴充、支援流處理等多種特性而被廣泛應用。
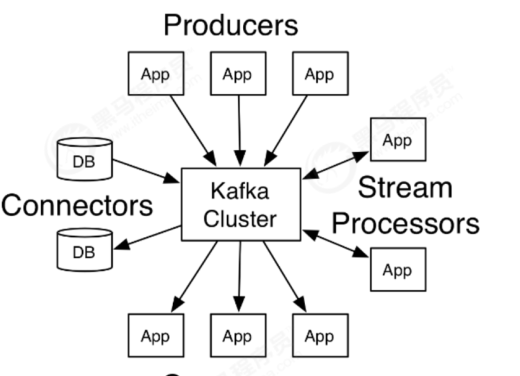
Apache Kafka是一個分布式的釋出-訂閱消息系統,能夠支撐海量資料的資料傳遞。在離線和實時的消
息處理業務系統中,Kafka都有廣泛的應用。Kafka将消息持久化到磁盤中,并對消息建立了備份保證了
資料的安全。Kafka在保證了較高的處理速度的同時,又能保證資料處理的低延遲和資料的零丢失。
(1)高吞吐量、低延遲:kafka每秒可以處理幾十萬條消息,它的延遲最低隻有幾毫秒,每個主題可以
分多個分區, 消費組對分區進行消費操作;
(2)可擴充性:kafka叢集支援熱擴充;
(3)持久性、可靠性:消息被持久化到本地磁盤,并且支援資料備份防止資料丢失;
(4)容錯性:允許叢集中節點失敗(若副本數量為n,則允許n-1個節點失敗);
(5)高并發:支援數千個用戶端同時讀寫;
北京市昌平區建材城西路金燕龍辦公樓一層 電話:400-618-9090
使用場景
(1)日志收集:一個公司可以用Kafka可以收集各種服務的log,通過kafka以統一接口服務的方式開放
給各種consumer,例如Hadoop、Hbase、Solr等;
(2)消息系統:解耦和生産者和消費者、緩存消息等;
(3)使用者活動跟蹤:Kafka經常被用來記錄web使用者或者app使用者的各種活動,如浏覽網頁、搜尋、點
擊等活動,這些活動資訊被各個伺服器釋出到kafka的topic中,然後訂閱者通過訂閱這些topic來做實時
的監控分析,或者裝載到Hadoop、資料倉庫中做離線分析和挖掘;
(4)營運名額:Kafka也經常用來記錄營運監控資料。包括收集各種分布式應用的資料,生産各種操作
的集中回報,比如報警和報告;
(5)流式處理:比如spark streaming和storm;
可伸縮性:Kafka 的兩個重要特性造就了它的可伸縮性。
1、Kafka 叢集在運作期間可以輕松地擴充或收縮(可以添加或删除代理),而不會當機。
2、可以擴充一個 Kafka 主題來包含更多的分區。由于一個分區無法擴充到多個代理,是以它的容量受
到代理磁盤空間的限制。能夠增加分區和代理的數量意味着單個主題可以存儲的資料量是沒有限制的。
容錯性和可靠性:Kafka 的設計方式使某個代理的故障能夠被叢集中的其他代理檢測到。由于每個主題
都可以在多個代理上複制,是以叢集可以在不中斷服務的情況下從此類故障中恢複并繼續運作。
吞吐量:代理能夠以超快的速度有效地存儲和檢索資料。
适應人群
本教程為專注于使用Apache Kafka消息傳遞系統或者大資料分析領域發展事業的專業人士做好準備,它
将給你足夠的了解如何使用Kafka叢集。
課程亮點
l 知識覆寫度廣泛;
l 知識覆寫度深入;
l 由淺入深講解思路;
l 案例分析全面;
l 适應于想學習Kafka技術的不同人群;
Apache官網:http://apache.org
Kafka官網:http://kafka.apache.org
kafka消費者主動拉取消息,缺點是主動拉取消息需要不斷輪詢去隊列看有沒有消息,比較耗費性能,優點是可以根據自己消費能力去消費消息,充分發揮自己的性能。隊列主動推送消息給消費者的優點是避免了輪詢但是消費者的消費能力不足會導緻崩潰,或者有些消費者能力強導緻消費者能力不能吃充分發揮,性能下降。kafka是消費者主動拉取消息。消費組的消費者個數要和分區個數一緻效率最高。每個topic的分區數要小于broker的數量,盡量保證每個分區位于不同的broker,
自動送出因存在送出時間會存在重複消費問題,而且耗時,但是當出錯時可以多次重複送出,安全性高。異步送出因為出現問題重複送出會導緻相鄰兩個異步送出産生重複導緻重複消費,是以異步沒有重試機制,異步機制适合資料量大的場景
的模式

Producer
生産者即資料的釋出者,該角色将消息釋出到Kafka的topic中。broker接收到生産者發送的消息後,
broker将該消息追加到目前用于追加資料的segment檔案中。生産者發送的消息,存儲到一個partition
中,生産者也可以指定資料存儲的partition。
Consumer
消費者可以從broker中讀取資料。消費者可以消費多個topic中的資料。
Topic
在Kafka中,使用一個類别屬性來劃分資料的所屬類,劃分資料的這個類稱為topic。如果把Kafka看做
為一個資料庫,topic可以了解為資料庫中的一張表,topic的名字即為表名。
Partition
topic中的資料分割為一個或多個partition。每個topic至少有一個partition。每個partition中的資料使
用多個segment檔案存儲。partition中的資料是有序的,partition間的資料丢失了資料的順序。如果
topic有多個partition,消費資料時就不能保證資料的順序。在需要嚴格保證消息的消費順序的場景下,
需要将partition數目設為1。
Partition offset
每條消息都有一個目前Partition下唯一的64位元組的offset,它指明了這條消息的起始位置。
Replicas of partition
副本是一個分區的備份。副本不會被消費者消費,副本隻用于防止資料丢失,即消費者不從為follower
的partition中消費資料,而是從為leader的partition中讀取資料。副本之間是一主多從的關系。
Broker
Kafka 叢集包含一個或多個伺服器,伺服器節點稱為broker。broker存儲topic的資料。如果某topic有
N個partition,叢集有N個broker,那麼每個broker存儲該topic的一個partition。如果某topic有N個
partition,叢集有(N+M)個broker,那麼其中有N個broker存儲該topic的一個partition,剩下的M個
broker不存儲該topic的partition資料。如果某topic有N個partition,叢集中broker數目少于N個,那麼
一個broker存儲該topic的一個或多個partition。在實際生産環境中,盡量避免這種情況的發生,這種
情況容易導緻Kafka叢集資料不均衡。
Leader
每個partition有多個副本,其中有且僅有一個作為Leader,Leader是目前負責資料的讀寫的
partition。
Follower
Follower跟随Leader,所有寫請求都通過Leader路由,資料變更會廣播給所有Follower,Follower與
Leader保持資料同步。如果Leader失效,則從Follower中選舉出一個新的Leader。當Follower與
Leader挂掉、卡住或者同步太慢,leader會把這個follower從“in sync replicas”(ISR)清單中删除,重
新建立一個Follower。
Zookeeper
Zookeeper負責維護和協調broker。當Kafka系統中新增了broker或者某個broker發生故障失效時,由
ZooKeeper通知生産者和消費者。生産者和消費者依據Zookeeper的broker狀态資訊與broker協調資料
的釋出和訂閱任務。
AR(Assigned Replicas)
分區中所有的副本統稱為AR。
ISR(In-Sync Replicas)
所有與Leader部分保持一定程度的副(包括Leader副本在内)本組成ISR。
OSR(Out-of-Sync-Replicas)
與Leader副本同步滞後過多的副本。
HW(High Watermark)
高水位,辨別了一個特定的offset,消費者隻能拉取到這個offset之前的消息。
LEO(Log End Offset)
即日志末端位移(log end offset),記錄了該副本底層日志(log)中下一條消息的位移值。注意是下一條消
息!也就是說,如果LEO=10,那麼表示該副本儲存了10條消息,位移值範圍是[0, 9]。
我們使用Linux系統進行教學示範,通過虛拟機安裝CentOS或者Win10系統自己挂載的ubuntu系統都
可以。
首先需要安裝Java環境,同時配置環境變量,步驟如下:
官網下載下傳JDK
https://www.oracle.com/technetwork/java/javase/downloads/jdk12-downloads-5295953.html
解壓縮,放到指定目錄
配置環境變量
在/etc/profile檔案中配置如下變量
測試jdk
1.2.2 ZooKeeper的安裝