CPU(Central Processing Unit)是計算機系統的運算和控制核心,是資訊處理、程式運作的最終執行單元,相當于系統的“大腦”。
當 CPU 過于繁忙,就像“人腦”并發處理過多的事情,會降低做事的效率,嚴重時甚至會導緻崩潰“當機”。是以,了解 CPU 的工作原理,合理控制負載,是保障系統穩定持續運作的重要手段。
一台機器可能包含多塊 CPU 晶片,多個 CPU 之間通過系統總線通信。
超線程(Hyper-Threading)技術可以讓一個實體核在機關時間内同時處理兩個線程,變成兩個邏輯核。但它不會擁有傳統單核 2 倍的處理能力,也不可能提供完整的并行處理能力。
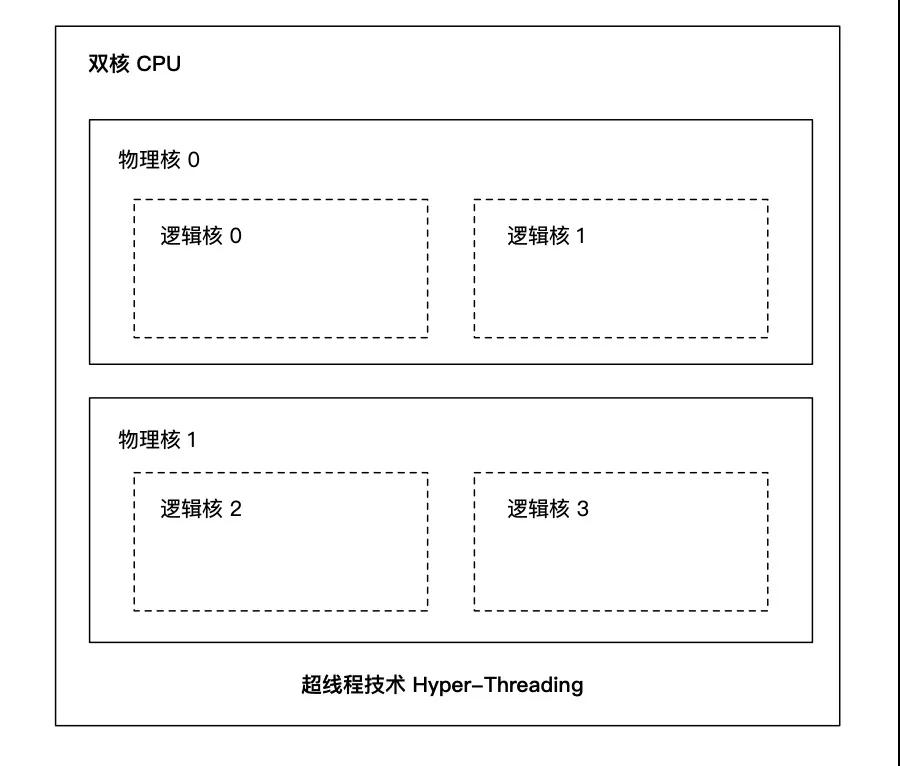
舉個例子,假設一個 CPU 晶片就是一個班級;它有 2 個實體核,也就是 2 個同學,老師讓他們分别擔任班長和體育委員;過了一段時間,校長要求每個班級還要有學習委員和生活委員,理論上還需要 2 位同學,但是這個班級隻有 2 個人,最後老師隻能讓班長和體育委員兼任。
這樣一來,對于不了解的人來說,這個班級有班長、體育委員、學習委員和生活委員 4 個職位,應該有 4 個人,每個職位就是一個邏輯核;但是,實際上這個班級隻有 2 位同學,也就是隻有 2 個實體核,雖然他們可以做 4 份工作,但是不能把他們當做 4 個人。

在 Linux 系統下,可以從 /proc/cpuinfo 檔案中讀取 CPU 資訊,如下圖所示:
檢視 CPU 個數:
<code>cat /proc/cpuinfo | grep 'physical id' | sort | uniq | wc -l</code>
檢視 CPU 實體核數:
<code>cat /proc/cpuinfo | grep 'cpu cores' | sort | uniq</code>
檢視 CPU 邏輯核數:
<code>cat /proc/cpuinfo | grep 'siblings' | sort | uniq</code>
CPU 使用率就是 CPU 非空閑态運作的時間占比,它反映了 CPU 的繁忙程度。比如,單核 CPU 1s 内非空閑态運作時間為 0.8s,那麼它的 CPU 使用率就是 80%;雙核 CPU 1s 内非空閑态運作時間分别為 0.4s 和 0.6s,那麼,總體 CPU 使用率就是 (0.4s + 0.6s) / (1s * 2) = 50%,其中 2 表示 CPU 核數,多核 CPU 同理。
在 Linux 系統下,使用 top 指令檢視 CPU 使用情況,可以得到如下資訊:
<code>Cpu(s): 0.2%us, 0.1%sy, 0.0%ni, 77.5%id, 2.1%wa, 0.0%hi, 0.0%si, 20.0%st </code>
us(user):表示 CPU 在使用者态運作的時間百分比,通常使用者态 CPU 高表示有應用程式比較繁忙。典型的使用者态程式包括:資料庫、Web 伺服器等。
sy(sys):表示 CPU 在核心态運作的時間百分比(不包括中斷),通常核心态 CPU 越低越好,否則表示系統存在某些瓶頸。
ni(nice):表示用 nice 修正程序優先級的使用者态程序執行的 CPU 時間。nice 是一個程序優先級的修正值,如果程序通過它修改了優先級,則會單獨統計 CPU 開銷。
id(idle):表示 CPU 處于空閑态的時間占比,此時,CPU 會執行一個特定的虛拟程序,名為 System Idle Process。
wa(iowait):表示 CPU 在等待 I/O 操作完成所花費的時間,通常該名額越低越好,否則表示 I/O 存在瓶頸,可以用 iostat 等指令做進一步分析。
hi(hardirq):表示 CPU 處理硬中斷所花費的時間。硬中斷是由外設硬體(如鍵盤控制器、硬體傳感器等)發出的,需要有中斷控制器參與,特點是快速執行。
si(softirq):表示 CPU 處理軟中斷所花費的時間。軟中斷是由軟體程式(如網絡收發、定時排程等)發出的中斷信号,特點是延遲執行。
st(steal):表示 CPU 被其他虛拟機占用的時間,僅出現在多虛拟機場景。如果該名額過高,可以檢查下主控端或其他虛拟機是否異常。
由于 CPU 有多種非空閑态,是以,CPU 使用率計算公式可以總結為:CPU 使用率 = (1 - 空閑态運作時間/總運作時間) * 100%。
根據經驗法則, 建議生産系統的 CPU 總使用率不要超過 70%。
平均負載(Load Average)是指機關時間内,系統處于 可運作狀态(Running / Runnable) 和 不可中斷态 的平均程序數,也就是 平均活躍程序數。
可運作态程序包括正在使用 CPU 或者等待 CPU 的程序;不可中斷态程序是指處于核心态關鍵流程中的程序,并且該流程不可被打斷。比如當程序向磁盤寫資料時,如果被打斷,就可能出現磁盤資料與程序資料不一緻。不可中斷态,本質上是系統對程序和硬體裝置的一種保護機制。
在 Linux 系統下,使用 top 指令檢視平均負載,可以得到如下資訊:
<code>load average: 1.09, 1.12, 1.52 </code>
這 3 個數字分别表示 1分鐘、5分鐘、15分鐘内系統的平均負載。該值越小,表示系統工作量越少,負荷越低;反之負荷越高。
理想情況下,每個 CPU 應該滿負荷工作,并且沒有等待程序,此時,平均負載 = CPU 邏輯核數。但是,在實際生産系統中,不建議系統滿負荷運作。通用的經驗法則是:平均負載 = 0.7 * CPU 邏輯核數。
當平均負載持續大于 0.7 * CPU 邏輯核數,就需要開始調查原因,防止系統惡化;
當平均負載持續大于 1.0 * CPU 邏輯核數,必須尋找解決辦法,降低平均負載;
當平均負載持續大于 5.0 * CPU 邏輯核數,表明系統已出現嚴重問題,長時間未響應,或者接近當機。
除了關注平均負載值本身,我們也應關注平均負載的變化趨勢,這包含兩層含義。一是 load1、load5、load15 之間的變化趨勢;二是曆史的變化趨勢。
當 load1、load5、load15 三個值非常接近,表明短期内系統負載比較平穩。此時,應該将其與昨天或上周同時段的曆史負載進行比對,觀察是否有顯著上升。
當 load1 遠小于 load5 或 load15 時,表明系統最近 1 分鐘的負載在降低,而過去 5 分鐘或 15 分鐘的平均負載卻很高。
當 load1 遠大于 load5 或 load15 時,表明系統負載在急劇升高,如果不是臨時性抖動,而是持續升高,特别是當 load5 都已超過 0.7 * CPU 邏輯核數 時,應調查原因,降低系統負載。
CPU 使用率是機關時間内 CPU 繁忙程度的統計。而平均負載不僅包括正在使用 CPU 的程序,還包括等待 CPU 或 I/O 的程序。是以,兩者不能等同,有兩種常見的場景如下所述:
CPU 密集型應用,大量程序在等待或使用 CPU,此時 CPU 使用率與平均負載呈正相關狀态。
I/O 密集型應用,大量程序在等待 I/O,此時平均負載會升高,但 CPU 使用率不一定很高。
為了更深入的了解 CPU 使用率與平均負載的關系,我們舉一個例子:假設現在有一個電話亭,有 4 個人在等待打電話,電話亭同一時刻隻能容納 1 個人打電話,隻有拿起電話筒才算是真正使用。那麼 CPU 使用率就是拿起電話筒的時間占比,它隻取決于在電話亭裡的人的行為,與平均負載沒有非常直接的關系。而平均負載是指在電話亭裡的人加上排隊的總人數
無論是 CPU 使用率,還是平均負載,都隻是反映系統健康狀态的度量名額,而不是問題的根因。
是以,它們的價值主要展現在兩個方面:一是綜合反映目前系統的健康程度,結合監控告警産品,實作快速響應;二是初步定位問題方向,縮小排查範圍,降低故障恢複時間。比如當 CPU iowait 高時,應優先排查磁盤 I/O;當 CPU steal 高時,就優先排查主控端狀态。
CPU 涵蓋的問題場景有很多,限于篇幅限制,下面以最常見的使用者态 CPU 使用率高為例,介紹下 Java 應用的排查思路,其他場景留待後續分享,推薦閱讀 《如何迅速分析出系統CPU的瓶頸在哪裡?》。
使用者态 CPU 使用率反映了應用程式的繁忙程度,通常與我們自己寫的代碼息息相關。是以,當你在做應用釋出、配置變更或性能優化時,如果想定位消耗 CPU 最多的 Java 代碼,可以遵循如下思路:
通過 top 指令找到 CPU 消耗最多的程序号;
通過 top -Hp 程序号 指令找到 CPU 消耗最多的線程号(列名仍然為 PID);
通過printf "%x\n" 線程号 指令輸出該線程号對應的 16 進制數字;
通過 jstack 程序号 | grep 16進制線程号 -A 10 指令找到 CPU 消耗最多的線程方法堆棧。
上述方法是目前業界最常用的診斷流程,如果是非 Java 應用,可以将 jstack 替換為 perf,推薦閱讀 《Perf — Linux下的系統性能調優工具》。
然而,上述方法有兩個顯著缺陷,一是操作流程複雜,而且往往一次 jstack 還不足以定位根因,需要執行多次;二是隻能用于診斷線上問題,如果問題已經發生,無法複現的話,往往隻能不了了之。