Apache Kafka可以幫助你解決在釋出/訂閱架構中遇到消費數百萬消息的問題。
如今,商業應用、社交應用以及其它類型的應用産生的實時資訊在不斷增長,這些資訊需要以簡單的方式快速、可靠地路由到各種類型的接收者。在大多數情況下,産生資訊和消費資訊的應用都是自然分開的,彼此不可互相通路。
需要一種機制,讓資訊的生産者和消費者能無縫地內建。
在大資料時代,收集資料也是一個挑戰——因為資料量太大。第二個挑戰是分析資料,它通常分為:
1)使用者行為資料
2)應用程式性能跟蹤
3)日志形式的活動資料
4)事件消息
消息訂閱是一種機制,可以連接配接各種應用程式,幫助消息在彼此之間路由。
Kafka是一個實時消息傳輸的解決方案,可處理大量實時資訊,并把這些資訊快速路由到各種消費者。Kafka提供了資訊生産者和消費者之間的無縫內建,無需對生産者的資訊進行阻塞,也無需告訴生産者那些消費者的位置。
Apache Kafka是一個開源、分布式的消息釋出/訂閱系統,其主要設計特性如下:
1)消息持久化
要從大資料中擷取真正的價值,那麼不能丢失任何資訊。Apache Kafka設計上是時間複雜度O(1)的磁盤結構,它提供了常量時間的性能,即使是存儲海量的資訊(TB級)。
2)高吞吐
記住大資料,Kafka的設計是工作在标準硬體之上,支援每秒數百萬的消息。
3)分布式
Kafka明确支援在Kafka伺服器上的消息分區,以及在消費機器叢集上的分發消費,維護每個分區的排序語義。
4)多用戶端支援
Kafka系統支援與來自不同平台(如java、.NET、PHP、Ruby或Python等)的用戶端相內建。
5)實時
生産者線程産生的消息對消費者線程應該立即可見,此特性對基于事件的系統(比如CEP系統)是至關重要的。
注:CEP即Complex Event Processing,複雜事件處理。
Apache Kafka提供了一個實時的釋出/訂閱解決方案,它客服了消費實時大資料的挑戰,這些資料量可能在數量級的增長、真實的資料。Kafka還支援在Hadoop系統上做并行資料載入。
下面的視圖顯示了Apache Kafka消息系統支援的一個典型的大資料彙聚和分析的場景:
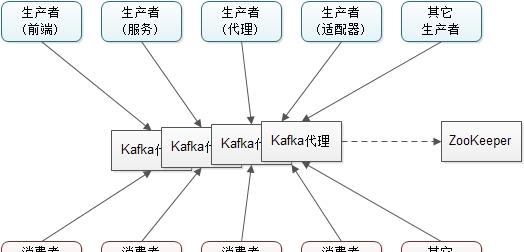
在生産者端,有數種不同的生産者:
1)前端Web應用産生的應用日志
2)生産者代理産生的Web分析日志
3)生産者擴充卡産生的傳輸日志
4)生産者服務産生的調用跟蹤日志
在消費者端,有數種不同的消費者:
1)離線消費者:消費消息并在Hadoop或傳統的資料倉庫中存儲消息用于離線分析
2)近乎實時的消費者:消費消息并在任意NoSQL資料庫(如HBase或Cassandra)中存儲消息用于近實時分析
3)實時消費者:在記憶體資料庫中過濾消息,并在相關的群組中觸發警告事件
![Linux 7 中配置Apache服務,及禁止ip通路,删除apache廣告頁面。[圖]](data:image/gif;base64,R0lGODlhAQABAIAAAP///wAAACwAAAAAAQABAAACAkQBADs=)