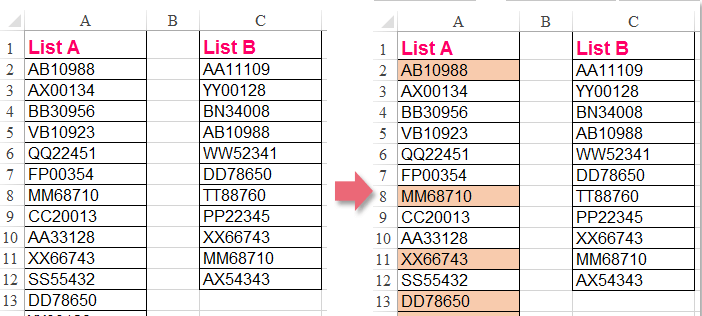
現有社保卡和身份證若幹,想要比對篩選出一一對應的社保卡和身份證。
轉換為List socialList,和List idList,從二者中找出比對的社保卡。
建立社保卡類
建立身份證類
隻要做兩輪循環即可。
準備初始化資料:
周遊
很容易看出,時間複雜度O(m,n)=m*n.
通過觀察發現,兩個list取相同的部分時,每次都周遊兩個list。那麼,可以把判斷條件放入Hash中,判斷hash是否存在來代替周遊查找。
如此,假設hash算法特别好,hash的時間複雜度為O(n)=n。如此推出這種做法的時間複雜度為O(m,n)=2m+n. 當然,更重要的是這種寫法更讓人喜歡,天然不喜歡嵌套的判斷,喜歡扁平化的風格。
想當然的以為,hash肯定會比周遊快,因為是hash啊。其實,可以算算比較結果。比較什麼時候<code>2m+n < m*n</code>。
從資料歸納法的角度,n必須大于2,不然即演變程<code>2m+2 < 2m</code>。于是,當n>2時:
結果是:
也就是說n<=3的時候,周遊要比hash快。事實上還要更快,因為hash還需要建立更多的對象。然而,大部分情況下,n也就是第二個數組的長度是大于3的。這就是為什麼說hash要更好寫。當然,另一個很重要的原因是lambda stream的運算符号遠比嵌套循環讓人喜愛。
唯有不斷學習方能改變!
-- <b>Ryan Miao</b>
![ORACLE——Instant Client配置SQL*LDR、EXP等指令工具[圖]](data:image/gif;base64,R0lGODlhAQABAIAAAP///wAAACwAAAAAAQABAAACAkQBADs=)