以下為精彩視訊内容整理:
<b></b>
<b>大資料在好友推薦系統中的應用</b>
給大家分享一下基于MaxCompute搭建社交好友推薦系統,使用MaxCompute阿裡的大資料計算的方法可以做哪些事情,如果說是以社交好友的推薦,來給大家去示範一下。好友推薦系統它的一個場景介紹,現在大家都在講大資料,如果想去使用這些資料,我們認為它需要具備三個要素,第一個要素是海量的資料,資料量越多越好,隻有資料量達到了足夠大,我們才能夠成為一個資料裡面潛在去挖掘出來。第二個是處理資料的能力,有了這樣很高的快速處理資料的能力,可以讓我們更快的去把資料裡面的資訊挖掘出來。第三個是商業變現的一個場景,我們采集大資料的時候,并不是資料越多越好,一定要有一個具體的場景。以推薦系統為例來看一下大資料的一個應用。
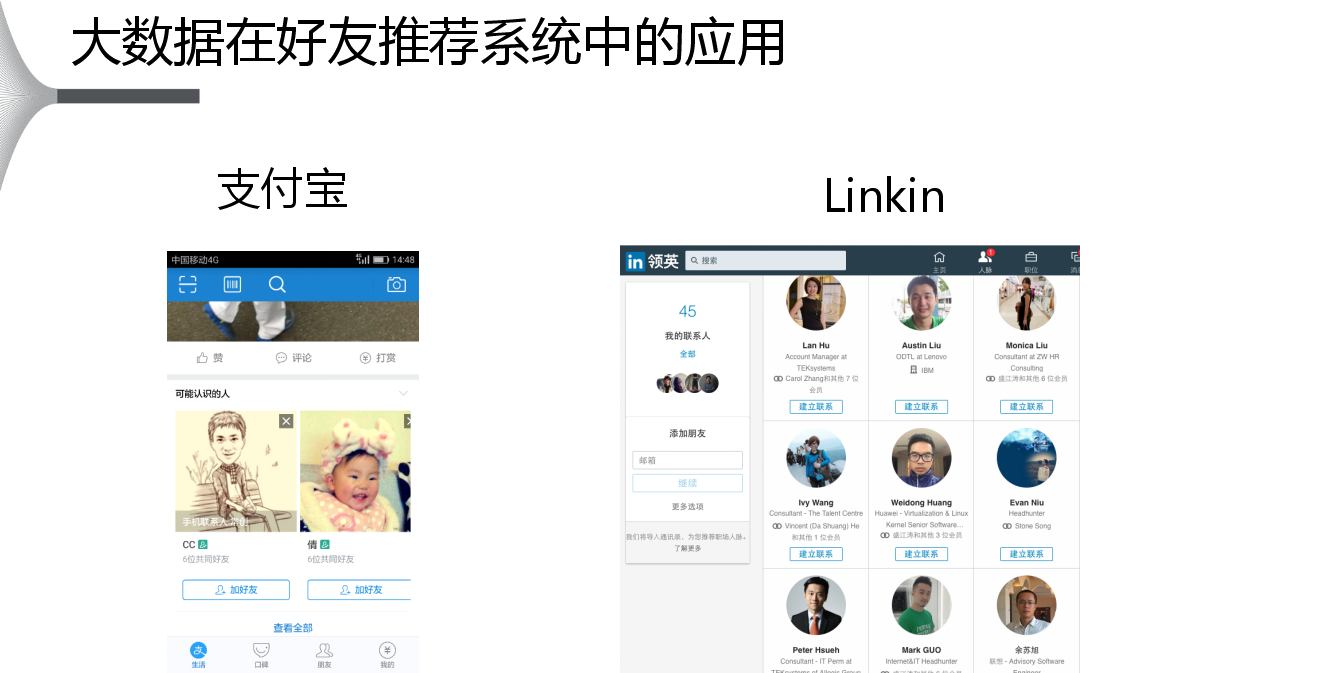
左邊是支付寶,在支付寶一打開的時候,下面會有一欄推薦可能是你的好友,一般的話下面的那些人都是你認識的,可能還沒加他們為好友。右側是Linkin,它是一個求職社交網站,Linkin也會給你這樣的一個推薦,會告訴你哪一些使用者是你潛在的好友,而且Linkin會告訴你這個好友跟你是一度的關系的還是兩度的關系或者是三度的關系。潛在關聯性高的,會在前面直接顯示出來,潛在關聯性沒有那麼高的也會在後面顯示出來,這兩個都是典型的一個好友推薦。
進行好友推薦的時候,怎麼給使用者進行推薦,首先這兩個人是非好友的關系,接着我們去看一下他們倆潛在共同好友的處理,通過這種方式去給使用者推送,比方說潛在好友數量多,我就認為這兩個人是好友關系,就是通過這種方式來實作的。

上圖的右側是人與人之間的一個社交關系的服務,比如說A跟B是一個好友,我們可以通過這五個方式畫出來,讓機器去分析這些資料,需要把右邊這種社交的關系,轉換成機器可以識别的資料,轉換成左側這樣的二維表的資料,比如說A跟B、C、D他們之間是好友,我們左側是A跟B、C、D是好友關系,剩下這些也是類似的,這樣就可以把這個表傳到機器裡面進行分析,比方說通過分析之後,發現A跟E有一個共同好友,B跟D有兩個共同好友,然後C跟E有一個共同好友。這個時候就可以推薦B跟D他兩個是一個潛在的好友,而排在前面,A跟E或者C跟E排在機率往下,稍微低一些,潛在好友多的排在前面,潛在好友少的排在後面,通過這種方式來進行排列,這個是我們期望的結果。
<b>好友推薦系統的分析模型</b>
我們怎麼來去計算呢?我們一般使用方式是什麼呢?使用的是MapReduce這樣的一個計算模型,MapReduce是一種程式設計模型,用于大規模資料集的并行運算,它由三部分組成分别是Map、Combine、Reduce。
以好友推薦這樣的一個場景為例。
首先輸入左側機器可以識别的資料,輸入之後,在Map端先把資料做一個拆分,拆分成兩份不同的資料,在拆分的同時把它轉換成key、value的類型,比方說A、B、D、E這幾行資料轉換成什麼呢?A跟B,然後value是零,零代表他們兩個已經是好友。如果兩個不是好友的話,自定義這一行資料,B跟D不是好友,就把他的值視為1。下面的B、E,還有D跟E也是1。把原來一行資料轉換成Key、Value這個形式的資料,類似于右邊這樣的資料,上面是key、value的一個類型,下面也是類似的。這個是在Map做的事情,把這個資料通過兩個key、value進行一個拆分,轉化成key、value這樣的一個類型。
Combine是對資料先做一個本地的彙總,先看到有一些資料是重複的,比如說A跟B是零,A跟B是零,出現了兩次,這個時候就存一個就可以。其他類似的,這樣我把這些資料在本地做完彙總,類似于這張表,這兩個資料。
接着是第三步是Reduce階段,Reduce是對這些資料進行一個彙總,把兩邊資料彙總到一起,然後對每一個Key值對應唯一的一個value值做一個彙總,這個就是它最終計算的一個結果。如果兩個使用者已經是好友了,Value值是零的話,不需要再給他推薦。是以說A、B如果是零的話就剔掉,隻需要知道它的value值是大于零的,有潛在好友,同時這兩個人目前還是非好友的關系,這個就達到了想要的效果。
<b>好友推薦系統在阿裡雲上的實作方式</b>
好友推薦阿裡雲實作整個的架構是怎麼樣的呢?比方現在有一個社交軟體是一個業務系統,前端使用阿裡雲的雲伺服器ECS去部署整個的社交的軟體的應用,入庫的一些資料存到阿裡的RDS,這個就是目前的一個社交應用系統。業務系統裡面産生了一個資料,怎麼來對資料進行分析,首先需要在資料庫裡邊把這個資料提取出來,提取到阿裡雲的大計算服務MaxCompute裡面,很類似于我們傳統做數倉的時候ETL的一個過程,會利用阿裡雲的大資料開發平台對資料進行分析和處理。
使用它可以快速便捷的去開發我們資料植入或者資料這樣的一個流程,這個就是會使用大資料開發平台和大資料制造,結果是一個資料分析結果,還需要前端的應用資料對分析出來的結果展示出來。
<b>MaxCompute的技術特點</b>
對于MaxCompute的一些技術特點主要有一下幾點:
(1)分布式:分布式叢集、跨叢集技術、可靈活擴充。
(2)安全性:從安全性來講具有自動存儲糾錯、沙箱機制、多分備份。
(3)易用:具有标準API、全面支援SQL、上傳下載下傳工具。
(4)權限控制:多租戶管理、使用者權限政策、資料通路政策。
<b>MaxCompute的使用場景</b>
對于MaxCompute的使用的場景,可以使用MaxCompute搭建自己的一個資料倉庫,同時,MaxCompute還可以提供一種分布式的應用系統,比方說可以通過圖計算,或者通過有效的寬幅的方式,可以搭建一個工作流;比方說資料分析并不是說隻分析一天就不分析了,其實是周期性的。如果資料每天要分析一次,可以在MaxCompute裡面生成那樣的任務工作流,設定一個周期性的排程,每天要讓它排程一次,MaxCompute可以按照設計好的工作流,調動周期,然後去運作;MaxCompute在機器學習裡面也是有用的,因為機器學習會用到MaxCompute分析出來的資料,其他相類似的服務對資料進行分析處理,分析出來的結果資料放到機器學習平台裡面,讓機器通過一些算法一些模型,去學習這裡邊的資料,生成一個希望達到的一個模型。
<b>大資料開發套件DataIDE</b>
另外一個除了MaxCompute之外還有一個會用到一個大資料開發操作DateIDE,大資料開發套件DataIDE(現名:資料工場DataWorks)提供一個高效、安全的離線資料開發環境。為什麼介紹它呢?是因為DateIDE隻是對資料任務工作流的一個開發,其實底層的資料處理,資料分析,都是在MaxCompute上完成,可以簡單了解為DateIDE就是一個圖象化的資料開發的服務,它是為了幫助我們更好去使用MaxCompute。也可以看到,這我們可以在DateIDE進行一個開發,不需要直接在MaxCompute裡面進行開發了,在MaxCompute開發的一個效果,跟在DateIDE裡面開發的效果對比。
這個是DateIDE整個應用的一個場景,我們在進行資料分析的時候,需要對裡面的原資料進行整合統一儲存,這個時候可以在DateIDE上實作,把所有的原資料的資訊統一彙總到MaxCompute裡面進行一個儲存,同時還可以DateIDE進行資料的加工,存儲等操作都可以在DateIDE上完成。DateIDE在整個資料分析的過程中可以對資料存儲、分析、處理、叢集等處理。
<b>MaxCompute的應用開發流程</b>
MaxCompute的應用開發流程一共需要六步分别是:
(1)安裝配置環境
(2)開發MR程式
(3)本地模式測試腳本
(4)導處jar包
(5)上傳到MaxCompute項目空間
(6)在MaxCompute中使用MR
下面我們以一個好友推薦的事例來詳細講解一下這個過程。首先需要去安裝MaxCompute用戶端,使用它的好處是可以在本地通過指令的方式去遠端使用阿裡雲的MaxCompute,在本地隻需要配置MaxCompute資訊就可以。另外還需要去配置自己的一個開發環境,因為現在阿裡雲的MaxCompute主要是兩種語言,一種是Java一種是Eclipse。然後建立項目,在開發建立項目的時候,大家可以看到這個紅包,這個紅包就是需要配置本地的用戶端的資訊。在進入到寫代碼的過程 。
接下來就是簡單的測試,開發之後要測試,這個代碼是不是按照設想的方式去工作的。接着這邊輸入的是一個測試資料,這個輸出的資料類别,就是輸出的這樣的一個表格,表格有三列,第一類是使用者A,第二類是使用者B,第三類是兩個潛在的共同好友的數量,隻需要關注這三個資料就可以,然後就可以測試。接着第三個本地運作的資料的代碼,運作的結果就是通過本地的開發測試,在本地測試的時候這邊有一個資料,你第一步需要選擇是使用哪一個的一個項目處理。第二個要選擇輸入表和輸出表,要告訴他輸出表是哪個,輸出表的目的是什麼,告訴這個程式,你輸出的結果儲存在表裡面,配置好點選運作這個結果就出來了。
本地開發測試成功之後,接着要把它打成一個Jar包,然後上傳到阿裡雲上,就是上傳到MaxCompute的叢集裡邊。第二個打完Jar包以後添加資源,下面就把剛剛輸出的Jar包,通過資源的管理,把剛剛輸入的Jar包上傳上來。本地開發測試好的一個MR的Jar包已經上傳到MaxCompute叢集裡邊。
上傳好了之後就可以使用它,去建立一個任務,然後這個任務去起個名字,這個任務跟哪一個Jar包相關聯,接着是OPENBMR,我們選的是MR的程式,是以裡面選的是OPENMR子產品,生成這樣的一個任務,進入到編輯頁面,在編輯頁面裡面首先告訴它,這個OPENMR這樣的一個任務,使用的是上傳的好友推薦的一個Jar包,最下面告訴它Jar包裡面的程式的邏輯是什麼,在這個裡面制定好之後點選運作結果就會出來。這個就是我們在本地開發測試,把資源上傳到MaxCompute的叢集裡面,接着在叢集裡面去使用我在本地開發好的Jar包,這個就是整個的一個開發和部署的一個流程。
<b>本文由雲栖社群志願者小組陳歡整理,百見編輯。</b>