1.Bagging(裝袋)
2.Boosting(提升)
3.Stacking(堆疊)
4.偏差與方差
內建學習(Emseble Learning)是建構多個學習器,然後通過一定政策把它們結合來完成學習任務的,常常可以獲得比單一學習顯著優越的學習器。周志華的書上說,“個體學習器的"準确性"和"多樣性"本身就存在沖突,一般準确性很高之後,要增加多樣性就需犧牲準确性。事實上,如何産生并結合‘好而不同’的個體學習器,恰是內建學習研究的核心”(對準确性和多樣性的論述還不是很了解)。
內建學習的思路是通過合并多個模型來提升機器學習性能,這種方法相較于當個單個模型通常能夠獲得更好的預測結果。這也是內建學習在衆多高水準的比賽如奈飛比賽,KDD和Kaggle,被首先推薦使用的原因。
按照個體學習器之間的關系,內建學習可以分為Bagging、Boosting、Stacking三大類。
用于減少方差的bagging
用于減少偏差的boosting
用于提升預測結果的stacking
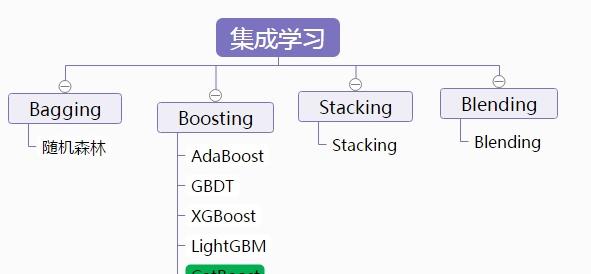
內建學習方法也可以歸為如下兩大類:
串行內建方法,這種方法串行地生成基礎模型(如AdaBoost)。串行內建的基本動機是利用基礎模型之間的依賴。通過給錯分樣本一個較大的權重來提升性能。
并行內建方法,這種方法并行地生成基礎模型(如Random Forest)。并行內建的基本動機是利用基礎模型的獨立性,因為通過平均能夠較大地降低誤差。
大部分內建模型都通過一個基礎學習算法來生成一個同質的基礎學習器,即同類型的學習器,也叫同質內建。
有同質內建就有異質內建,為了內建後的結果表現最好,異質基礎學習器需要盡可能準确并且差異性夠大。
Bagging就像是“民主政治”----少數服從多數
Bagging是引導聚合的意思。減少一個估計方差的一種方式就是對多個估計進行平均。
Bagging的原理首先是基于自助采樣法(bootstrap sampling)随機得到一些樣本集訓練,用來分别訓練不同的基學習器,然後對不同的基學習器得到的結果投票得出最終的分類結果。自助采樣法得到的樣本大概會有63%的資料樣本被使用,剩下的可以用來做驗證集。
實作步驟:
随機森林(Random Forest)其實也算Bagging的一種,但是有一點差別是随機森林在建構決策樹的時候,會随機選擇樣本特征中的一部分來進行劃分。由于随機森林的二重随機性,它具有良好的學習性能。
在随機森林中,每個樹模型都是裝袋采樣訓練的。這種處理的結果是随機森林的偏差增加的很少,而由于弱相關樹模型的平均,方差也得以降低,最終得到一個方差小,偏差也小的模型。
(Bagging+決策樹=随機森林)

在一個極端的随機樹算法中,随機應用的更為徹底:訓練集分割的門檻值也是随機的,即每次劃分得到的訓練集是不一樣的。這樣通常能夠進一步減少方差,但是會帶來偏差的輕微增加。
需要說明的是,Bagging算法是多種分類器并行執行的。
下面通過應用Iris資料集的分類問題來距離說明bagging。我們可以使用兩種基礎模型:決策樹和KNN。圖1展示了基礎模型與內建模型學習得到的決策邊界。
決策樹學到的是軸平行邊界,然而k=1最近鄰對資料拟合的最好。bagging通過訓練10個基礎模型以及随機選擇80%的資料作為訓練集,同樣随機選擇80%的特征進行訓練。
決策樹bagging內建相比KNN bagging內建獲得了更高的準确率。KNN對于訓練樣本的擾動并不敏感,這也是為什麼KNN成為穩定學習器的原因。
整合穩定學習器對于提升泛化性能沒有幫助。
圖像結果同樣展示了通過增加內建模型的個數帶來的測試準确率變化。基于交叉驗證的結果,我們可以看到整合基礎模型個數大于10個之後性能就基本不再提升了,隻是帶來了計算複雜度的增加。
最後一張圖繪制的是內建學習模型的學習曲線,注意訓練集資料的平均誤差為0.3,在對訓練集做80%采樣的時候訓練集和驗證集誤差最小。
Boosting就像是“精英政治”,不同的人,說話的分量不一樣~
Boosting指的是通過算法集合将弱學習器轉換為強學習器。boosting的主要原則是訓練一系列的弱學習器,所謂弱學習器是指僅比随機猜測好一點點的模型,例如較小的決策樹,訓練的方式是利用權重的資料。在訓練的早期對于錯分資料給予較大的權重。
對于訓練好的弱分類器,如果是分類任務按照權重進行投票,而對于回歸任務進行權重,然後再進行預測。boosting和bagging的差別在于是對權重後的資料利用弱分類器依次進行訓練。
Boosting算法是多種分類器串行執行的,比如3個分類器G1,G2,G3,其中G1的效果是最好的,依次是G2,G3。那我們選擇G1當做一個分類器加入的Boosting算法中,目前這個G1也會有誤差,之後,帶着這些誤差和G1的結果,我們在G1後加入分類效果第二好的G2。最後在加入G3。這樣串行的進行Boosting算法,最終得到結果。
從弱學習器開始加強,通過權重來進行訓練。
下面描述的算法是最常用的一種boosting算法,叫做AdaBoost,表示自适應boosting。
而對比我們可以看到第一個分類器y1(x)是用相等的權重系數進行訓練的。在随後的boosting中,錯分的資料權重系數将會增加,正确分類的資料權重系數将會減小。
epsilon表示單個分類器的權重錯誤率。alpha是分類器的權重,正确的分類器alpha較大。
AdaBoost算法的表現如上圖所示。每個基礎模型包含一個深度為1的決策樹,這種決策樹依靠線性劃分進行分類,決策平面跟其中一個軸平行。上圖還展示了內建規模的增加帶來的測試準确率變化以及訓練和測試集的學習曲線。
梯度樹提升(Gradient Tree Boosting)是一個boosting算法在損失函數上的泛化。能夠用于分類和回歸問題。Gradient Boosting采用串行方式構模組化型。
每新增一個決策樹hm(x)都盡可能的選擇是的目前模型Fm-1(x)損失最小的那個:
注意:分類和回歸使用的損失函數有所差别。
Stacking是通過一個元分類器或者元回歸器來整合多個分類模型或回歸模型的內建學習技術。基礎模型利用整個訓練集做訓練,元模型将基礎模型的結果作為特征進行訓練。
基礎模型通常包含不同的學習算法,是以stacking通常是異質內建。算法僞代碼如下:
各基礎模型的預測結果如下:
Stacking內建效果如上圖所示。分别在KNN,Random Forest,Naive Bayes做訓練和預測,然後将其輸出結果作為特征,利用邏輯回歸作為元模型進一步訓練。如圖所示,stacking內建的結果由于每個基礎模型,并且沒有過拟合。
Stacking被Kaggle競賽獲獎者廣泛使用。例如,Otto Group Product分類挑戰賽的第一名通過對30個模型做stacking赢得了冠軍。他将30個模型的輸出作為特征,繼續在三個模型中訓練,這三個模型XGBoost,Neural Network和Adaboost,最後再權重平均。詳見文章(https://www.kaggle.com/c/otto-group-product-classification-challenge/discussion/14335)。