正規表達式的使用需要借助于工具程式來實作,我們使用grep來示範正規表達式元字元的使用。
grep使用方法
grep是一種文本搜尋工具,根據使用者指定的文本模式(搜尋條件)對目标檔案進行逐行搜尋,顯示能比對到的行。
使用grep在/etc/passwd檔案中找到有”roo”關鍵字的行并顯示了出來
grep指令的文法:
grep [OPTIONS] PATTERN [FILE…]
PATTERN:文本字元和正規表達式的元字元組合而成的比對條件
OPTOINS:此處隻列舉常用的選項
–color=auto:給關鍵字加上顔色
可以在全局配置檔案/etc/bashrc中定義指令别名grep=”grep –color=auto”,以使grep指令預設輸出顔色
-i:忽略大小寫
-v:顯示沒有被模式比對的内容
-o:隻顯示被模式比對的串本身
-n:顯示行号
-A #:顯示比對字元的後面“#”行
顯示包含roo字元行的後面一行
-B #:顯示比對字元的前面“#”行
顯示包含ROO字元行的前面一行
-C #:顯示比對字元的前後面“#”行
顯示包含roo字元的前後各一行
-E:擴充正規表達式
正規表達式:Regular Expression, REGEXP
常用正規表達式分為兩種
1. 基本正規表達式(Basic REGEXP)
grep
2. 擴充正規表達式(Extended REGEXP)
egrep、grep -E
元字元:不表示其字面意義,而用于額外功能性描述
基本正規表達式的元字元:
字元比對:
. :比對任意單個字元
r..t:表示以r開頭,中間包含兩個任意字元并以t結尾的字元串
[ ]:比對指定範圍内的任意單個字元
r[a-z]t:表示以r開頭,中間包含一個任意小寫字母并以t結尾的字元串
可以使用一些特殊符号還表示特定的值範圍
[[:digit:]] :表示數字,相當于[0-9]
[[:lower:]]:表示小寫字母,相當于[a-z]
[[:upper:]]:表示大寫字母,相當于[A-Z]
[[:space:]]:表示任何會産生空白的字元,如空格鍵、tab鍵等
[[:punct:]]:表示标點符号
[[:alpha:]] :表示任何大小寫字母,相當于[a-zA-Z]
[[:alnum:]]:表示任何大小寫字母和數字,相當于[0-9a-zA-Z]
[^]:比對指定範圍外的任意單個字元
r[^[:lower:]]t:表示以r開頭,中間包含一位非小寫字母并以t結尾的字元串
次數比對:用于實作指定其前面的字所能夠出現的次數
*:任意長度,前面的字元可以出現任意次
r*t:其中r*表示可以為空字元或一個連續r以上的字元;
如果需要至少兩個r以上的字元串時,使用rrr*來表示
同理需要至少三個r以上的字元串時,使用rrrr*來表示
\?:比對其前面的字元一次或0次,它前面的字元是可有可無的,其中\為轉義字元
rr\?t:表示以r開頭,中間有一個或者為空字元并且以t結尾的字元串
\{m\}:m次,它前面的字元要出現m次
r\{2\}:表示包含兩個連續r的字元串
\{m,n\}:比對其前面的字元至少m次,至多n次
r\{2,4\}t:表示包含2至4個連續r,并且以t結尾的字元串
\{m,\}:最少比對其前面的字元m次
r\{5\}:表示最小出現5個連續的r并且以t結尾的字元串
\{0,n\}:最多比對其前面的字元n次
r\{0,5\}:表示最多出現5個連續的r并且為t結尾的字元串
注:結果中出現了上面所示的行,是因為沒有限定條件不嚴格造成的,可以定義字元串首部來得到精确結果
.*:任意長度的任意字元
r.*t:表示r與t之間為任意字元(包括空字元)的字元串
位置錨定:用于定義字元位置的元字元
^:錨定行首,此字元後面的任意内容出現在行首。
查找以r開頭t結尾的4個字元的字元串開頭的行
$:錨定行尾,此字元前面的任意内容出現在行尾
查找以n結尾的行
^$:空白行
\<或\b:其後面的任意字元必須作為單詞首部出現
包含以op開頭的單詞的行
\>或\b:其前面的任意字元必須作為單詞尾部出現
包含以ot結尾的單詞的行
可以将兩個符号結合使用,精确查找單詞
分組:
\( \):把内容分組,括号中的字元将被看作是一個整體進行操作
分組中的模式比對到的内容,可由正規表達式引擎記憶在記憶體中,之後可被引用
例如:當我們想要查找一個檔案中包含至少1個ab的行
建立一個檔案eg
引用:
\#:引用第#個括号所比對到的内容,而非模式本身
例如:
建立一個檔案eg1,内容如下:
使用分組得到以下結果
下面使用引用來查找對應的行
表達式中的括号是有編号的,從最左邊的左括号開始計算,編号從1開始,上面的表達式中有兩個左括号,edu前面的為編号1,qa前面的為編号2;而與左括号相對應的右括号則是從裡向外就近比對,上面的表達式中編号為2的表達式為\(qa[[:digit:]]\),編号為1的表達式為\(edc[0-9]\{3\}\(qa[[:digit:]]\)\);
\1表示如果在行中有比對編号為1的表達式的結果,并且在本行再次出現此表達式的結果時,則此行被選中;如上圖的查詢結果中1号表達式的結果為”edc123qa7“,而後面又出現了一次此字元串,是以該行被選中;\2則引用2号表達式的結果進行比對查找,2号表達式的結果為”qa7″,是以結果中列出了再次出現”qa7″字元串的行。
擴充正規表達式:
字元比對:與基本正規表達式相同
. :比對任意單個字元
[^]:比對指定範圍外的任意單個字元
次數比對:無需轉義字元
?:比對前面的字元0或1次
+:至少1次= \{1,\}
{m}:精确比對m次
{m,n}:至少m次,至多n次
錨定:與基本正規表達式相同,詞首與詞尾錨定依然需要轉義
分組:與基本正規表達式相同,無需轉義
():無需轉義
引用:\1,\2,\3 …
或者:
a|b:a或者b
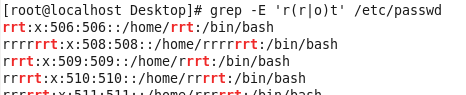
使用擴充正規表達式完成上面的引用查詢
