本文來自AI新媒體量子位(QbitAI)
2017已經正式離我們遠去。
過去的一年裡,有很多值得梳理記錄的内容。部落格WILDML的作者、曾在Google Brain做了一年Resident的Denny Britz,就把他眼中的2017年AI和深度學習的大事,進行了一番梳理彙總。
量子位進行概要摘錄如下,詳情可前往原文檢視,位址:http://www.wildml.com/2017/12/ai-and-deep-learning-in-2017-a-year-in-review/
作為一個強化學習Agent,它的第一個版本使用了來自人類專家的訓練資料,然後通過自我對局和蒙特卡洛樹搜尋的改進來進化。
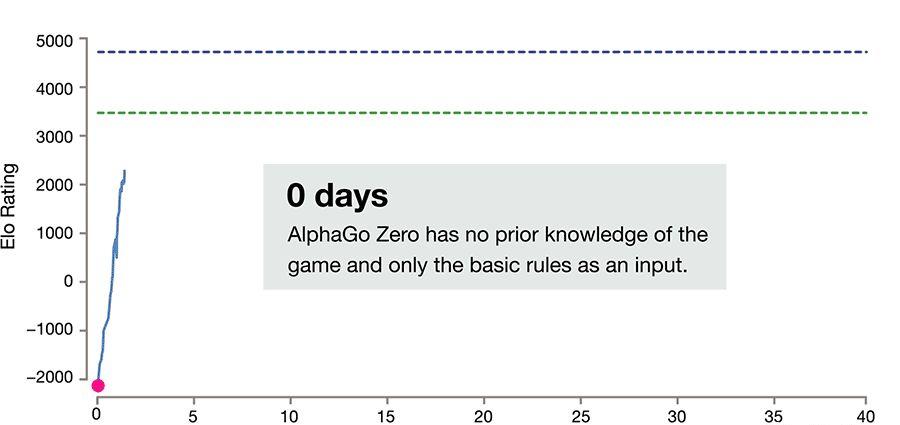
這些算法在對局中所用的政策,有時候甚至讓經驗豐富的棋手都覺得驚訝,他們也會向AlphaGo學習,改變着自己的對局風格。為了讓學習更容易,DeepMind還釋出了AlphaGo Teach工具。

下面是相關論文,認真的同學們可以收藏回顧啦:
AlphaGo
https://storage.googleapis.com/deepmind-media/alphago/AlphaGoNaturePaper.pdf
AlphaGo Zero
https://www.nature.com/articles/nature24270.epdf
AlphaZero
https://arxiv.org/abs/1712.01815
Thinking Fast and Slow with Deep Learning and Tree Search
https://arxiv.org/abs/1705.08439
再早些時候,查爾斯大學、捷克技術大學和加拿大阿爾伯塔大學開發的DeepStack,首先擊敗了專業德撲玩家。
有一點值得注意,這兩個程式玩的都是一對一撲克,也就是兩名玩家之間的對局,這比多人遊戲更容易。2018年,我們很可能看到算法在多玩家撲克上取得一些進步。
Libratus論文:
http://science.sciencemag.org/content/early/2017/12/15/science.aao1733.full
星際争霸2研究環境:
https://deepmind.com/blog/deepmind-and-blizzard-open-starcraft-ii-ai-research-environment/
對于監督學習來說,基于梯度的反向傳播算法已經非常好,而且這一點可能短期内不會有什麼改變。
然而,在強化學習中,進化政策(Evolution Strategies, ES)似乎正在東山再起。因為強化學習的資料通常不是lid(獨立同分布)的,錯誤信号更加稀疏,而且需要探索,不依賴梯度的算法表現很好。另外,進化算法可以線性擴充到數千台機器,實作非常快的平行訓練。它們不需要昂貴的GPU,但可以在成百上千便宜的CPU機器上進行訓練。
2017年早些時候,OpenAI的研究人員證明了進化政策實作的性能,可以與Deep Q-Learning等标準強化學習算法相媲美。
相關論文:
https://arxiv.org/abs/1703.03864
遠離昂貴且訓練漫長的回歸架構是一個更大的趨勢。在論文Attention is All you Need裡,研究人員完全擺脫了循環和卷積,使用一個更複雜的注意力機制,隻用了很小的訓練成本,就達到了目前最先進的結果。
論文位址:https://arxiv.org/abs/1706.03762
如果非要用一句話總結2017,那隻能說是架構之年。
此外,
除了通用的深度學習架構外,我們還看到大量的強化學習架構釋出:
OpenAI Roboschool,用于機器人仿真
https://blog.openai.com/roboschool/
OpenAI Baselines,一套強化學習算法的高品質實作
https://github.com/openai/baselines
Tensorflow Agents,用TensorFlow來訓練RL智能體
https://github.com/tensorflow/agents
Unity ML Agents,研究人員可用Unity Editor來建立遊戲,并展開強化訓練
https://github.com/Unity-Technologies/ml-agents
Nervana Coach,用最先進的強化學習算法進行試驗
http://coach.nervanasys.com/
Facebook ELF,遊戲研究平台
https://code.facebook.com/posts/132985767285406/introducing-elf-an-extensive-lightweight-and-flexible-platform-for-game-research/
DeepMind Pycolab,定制化的遊戲引擎
https://github.com/deepmind/pycolab
Geek.ai MAgent,多智能體強化學習平台
https://github.com/geek-ai/MAgent
為了讓深度學習更易普及,還有一些面向web的架構,例如谷歌的deeplearn.js和MIL WebDNN執行架構。
2017,還有一個流行架構跟我們告别了。
随着深度學習和強化學習越來越流行,2017年有越來越多的課程、訓練營等活動舉行并分享到網上。以下是我最愛的一些。
Deep RL Bootcamp,由OpenAI和UC Berkeley聯合主辦,主要講授關于強化學習的基礎知識和最新研究成果
位址:https://sites.google.com/view/deep-rl-bootcamp/lectures?authuser=0
斯坦福視覺識别卷積神經網絡課程2017春季版
http://cs231n.stanford.edu/
斯坦福自然語言處理與深度學習課程2017冬季版
http://web.stanford.edu/class/cs224n/
斯坦福的深度學習理論課程
https://stats385.github.io/
Coursera上最新的深度學習課程
https://www.coursera.org/specializations/deep-learning
蒙特利爾深度學習和強化學習暑期學校
http://videolectures.net/deeplearning2017_montreal/
UC Berkeley的深度強化學習課程2017秋季版
http://rll.berkeley.edu/deeprlcourse/
TensorFlow開發者大會上關于深度學習和TensorFlow API相關的内容
https://www.youtube.com/playlist?list=PLOU2XLYxmsIKGc_NBoIhTn2Qhraji53cv
幾大學術會議,延續了在網上釋出會議内容的新傳統。如果你想趕上最尖端的研究,可以檢視這些頂級會議的錄像資料。
NIPS 2017:
https://nips.cc/Conferences/2017/Videos
ICLR 2017:
https://www.facebook.com/pg/iclr.cc/videos/
EMNLP 2017:
https://ku.cloud.panopto.eu/Panopto/Pages/Sessions/List.aspx
研究人員也開始在arXiv上釋出低門檻的教程和綜述論文。以下是過去一年我的最愛。
深度強化學習:概述
Deep Reinforcement Learning: An Overview
https://arxiv.org/abs/1701.07274
給工程師的機器學習簡介
A Brief Introduction to Machine Learning for Engineers
https://arxiv.org/abs/1709.02840
神經機器翻譯
Neural Machine Translation
https://arxiv.org/abs/1709.07809
教程:神經機器翻譯和序列到序列模型
Neural Machine Translation and Sequence-to-sequence Models: A Tutorial
https://arxiv.org/abs/1703.01619
2017年,有不少人宣稱用深度學習解決了醫療問題,而且還擊敗了人類專家。這其中有真正的突破,也有一些炒作。對這方面感興趣的話,推薦關注Luke Oakden-Rayner的人類醫生終結系列部落格:
https://lukeoakdenrayner.wordpress.com/2017/04/20/the-end-of-human-doctors-introduction/
這裡簡要介紹一些發展。其中最重要的事件包括:斯坦福的一個團隊公布了用深度學習識别皮膚癌的算法細節。
相關研究:https://cs.stanford.edu/people/esteva/nature/
另一個斯坦福的團隊則開發了一個模型,能比人類專家更好的發現心律失常。
相關研究:https://stanfordmlgroup.github.io/projects/ecg/
當然也有一些風波。例如DeepMind與NHS之間的問題;NIH釋出了一個不适合訓練AI的胸部X光片資料集等等。
應用于圖像、音樂、繪圖和視訊領域的生成模型,今年也越來越受到關注。NIPS 2017還首次推出了面向創意與設計的機器學習研讨會。
一起去玩一下:
https://quickdraw.withgoogle.com/
相關位址:
CycleGAN
https://arxiv.org/abs/1703.10593
DiscoGAN
https://github.com/carpedm20/DiscoGAN-pytorch
StarGAN
https://github.com/yunjey/StarGAN
無人車領域的大玩家包括Uber、Lyft、Waymo和Tesla。Uber這一年都麻煩不斷,但是這家公司一直沒有停下在無人車方面的腳步。
今年有很多好玩的項目和展示,這裡不可能提及所有:
用深度學習創造動漫角色
一起來試試吧~ http://make.girls.moe/#/
神經網絡玩《馬裡奧賽車》
實時《馬裡奧賽車 64》AI
https://github.com/rameshvarun/NeuralKart
<a href="http://mp.weixin.qq.com/s?__biz=MzIzNjc1NzUzMw==&mid=2247484309&idx=3&sn=8c9884e899b590bb675c7773e0b6f250&chksm=e8d3b4e7dfa43df1d656380d8f2059bea2a14a9f97990a05a2ea111a8f4eda2a44e4d6dfd23c&scene=21#wechat_redirect" target="_blank">随手畫貓</a>
在研究層面,
習得索引結構 - 使用神經網絡優化高速緩存B-Tree。
https://arxiv.org/abs/1712.01208
Attention is All You Need - Google推出的翻譯架構Transformer完全舍棄了RNN/CNN結構。
https://arxiv.org/pdf/1706.03762.pdf
<a href="http://mp.weixin.qq.com/s?__biz=MzIzNjc1NzUzMw==&mid=2247490443&idx=1&sn=7afcdf7062c27bcb2ceae64f480751ee&chksm=e8d3acf9dfa425efd8f9ae5370c0e89d4d401609f867ef3f78361a66c7ad9a86b4e710f1d28f&scene=21#wechat_redirect" target="_blank">Mask R-CNN</a>
神經網絡需要大量的資料,是以開放資料集是對行業的重要貢獻。以下是今年幾個新推出的資料集代表。
Youtube Bounding Boxes
https://research.google.com/youtube-bb
Google QuickDraw Data
https://quickdraw.withgoogle.com/data
DeepMind Open Source Datasets
https://deepmind.com/research/open-source/open-source-datasets
Google Speech Commands Dataset
https://research.googleblog.com/2017/08/launching-speech-commands-dataset.html
Atomic Visual Actions
https://research.google.com/ava/
Several updates to the Open Images data set
https://github.com/openimages/dataset
Nsynth dataset of annotated musical notes
https://magenta.tensorflow.org/datasets/nsynth
Quora Question Pairs
https://data.quora.com/First-Quora-Dataset-Release-Question-Pairs
另外,研究人員并不總是同步公開代碼,論文中有時還會漏掉重要的細節,或者使用特殊的評估方法……這些因素都讓可複現性成為一個大問題。
論文位址:https://arxiv.org/abs/1711.10337
同樣,在論文On the State of the Art of Evaluation in Neural Language Models中,研究人員表明,簡單的LSTM架構在正确調整後,表現就能比最近的多數模型都好。
論文位址:https://arxiv.org/abs/1707.05589
加拿大和中國,正在加速AI方面的部署。
宣傳非常重要,但有些宣傳和實驗室實際發生的事情不符。IBM沃森就是過度營銷的傳奇,并沒有帶來相符的結果。大家都不喜歡沃森,是以他們在醫療方面一再失敗也不奇怪。
Facebook的人工智能發明了自己的語言那事,其實也跟真相不符。這不簡單是媒體的誤導,研究人員所用的标題和摘要也越了界,沒能反映實驗的實際結果。
本文作者:若樸 夏乙
原文釋出時間:2018-01-01