最近在了解ELK做日志采集相關的内容,這篇文章主要講解通過filebeat來實作日志的收集。日志采集的工具有很多種,如fluentd, flume, logstash,betas等等。首先要知道為什麼要使用filebeat呢?因為logstash是jvm跑的,資源消耗比較大,啟動一個logstash就需要消耗500M左右的記憶體,而filebeat隻需要10來M記憶體資源。常用的ELK日志采集方案中,大部分的做法就是将所有節點的日志内容通過filebeat送到kafka消息隊列,然後使用logstash叢集讀取消息隊列内容,根據配置檔案進行過濾。然後将過濾之後的檔案輸送到elasticsearch中,通過kibana去展示。
filebeat介紹
Filebeat由兩個主要組成部分組成:prospector和 harvesters。這些元件一起工作來讀取檔案并将事件資料發送到您指定的output。
什麼是harvesters?
harvesters負責讀取單個檔案的内容。harvesters逐行讀取每個檔案,并将内容發送到output中。每個檔案都将啟動一個harvesters。harvesters負責檔案的打開和關閉,這意味着harvesters運作時,檔案會保持打開狀态。如果在收集過程中,即使删除了這個檔案或者是對檔案進行重命名,Filebeat依然會繼續對這個檔案進行讀取,這時候将會一直占用着檔案所對應的磁盤空間,直到Harvester關閉。預設情況下,Filebeat會一直保持檔案的開啟狀态,直到超過配置的close_inactive參數,Filebeat才會把Harvester關閉。
關閉Harvesters會帶來的影響:
file Handler将會被關閉,如果在Harvester關閉之前,讀取的檔案已經被删除或者重命名,這時候會釋放之前被占用的磁盤資源。
當時間到達配置的scanfrequency參數,将會重新啟動為檔案内容的收集。
如果在Havester關閉以後,移動或者删除了檔案,Havester再次啟動時,将會無法收集檔案資料。
當需要關閉Harvester的時候,可以通過close*配置項來控制。
什麼是Prospector?
Prospector負責管理Harvsters,并且找到所有需要進行讀取的資料源。如果input type配置的是log類型,Prospector将會去配置度路徑下查找所有能比對上的檔案,然後為每一個檔案建立一個Harvster。每個Prospector都運作在自己的Go routine裡。
Filebeat目前支援兩種Prospector類型:log和stdin。每個Prospector類型可以在配置檔案定義多個。log Prospector将會檢查每一個檔案是否需要啟動Harvster,啟動的Harvster是否還在運作,或者是該檔案是否被忽略(可以通過配置 ignore_order,進行檔案忽略)。如果是在Filebeat運作過程中新建立的檔案,隻要在Harvster關閉後,檔案大小發生了變化,新檔案才會被Prospector選擇到。
filebeat工作原理
Filebeat可以保持每個檔案的狀态,并且頻繁地把檔案狀态從系統資料庫裡更新到磁盤。這裡所說的檔案狀态是用來記錄上一次Harvster讀取檔案時讀取到的位置,以保證能把全部的日志資料都讀取出來,然後發送給output。如果在某一時刻,作為output的ElasticSearch或者Logstash變成了不可用,Filebeat将會把最後的檔案讀取位置儲存下來,直到output重新可用的時候,快速地恢複檔案資料的讀取。在Filebaet運作過程中,每個Prospector的狀态資訊都會儲存在記憶體裡。如果Filebeat出行了重新開機,完成重新開機之後,會從系統資料庫檔案裡恢複重新開機之前的狀态資訊,讓FIlebeat繼續從之前已知的位置開始進行資料讀取。
Prospector會為每一個找到的檔案保持狀态資訊。因為檔案可以進行重命名或者是更改路徑,是以檔案名和路徑不足以用來識别檔案。對于Filebeat來說,都是通過實作存儲的唯一辨別符來判斷檔案是否之前已經被采集過。
如果在你的使用場景中,每天會産生大量的新檔案,你将會發現Filebeat的系統資料庫檔案會變得非常大。這個時候,你可以參考(the section called “Registry file is too large?edit),來解決這個問題。
安裝filebeat服務
2.1 最簡單架構
在這種架構中,隻有一個 Logstash、Elasticsearch 和 Kibana 執行個體。Logstash 通過輸入插件從多種資料源(比如日志檔案、标準輸入 Stdin 等)擷取資料,再經過濾插件加工資料,然後經 Elasticsearch 輸出插件輸出到 Elasticsearch,通過 Kibana 展示。詳見圖 1。
圖 1. 最簡單架構
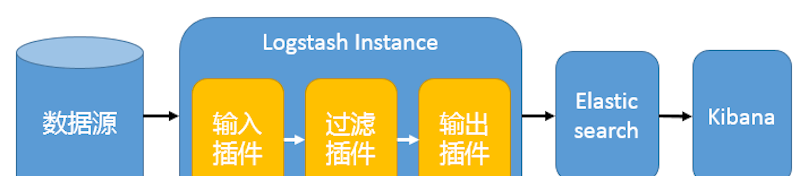
這種架構非常簡單,使用場景也有限。初學者可以搭建這個架構,了解 ELK 如何工作。
2.2 Logstash 作為日志搜集器
這種架構是對上面架構的擴充,把一個 Logstash 資料搜集節點擴充到多個,分布于多台機器,将解析好的資料發送到 Elasticsearch server 進行存儲,最後在 Kibana 查詢、生成日志報表等。詳見圖 2。
圖 2. Logstash 作為日志搜尋器

這種結構因為需要在各個伺服器上部署 Logstash,而它比較消耗 CPU 和記憶體資源,是以比較适合計算資源豐富的伺服器,否則容易造成伺服器性能下降,甚至可能導緻無法正常工作。
2.3 Beats 作為日志搜集器
這種架構引入 Beats 作為日志搜集器。目前 Beats 包括四種:
Beats 将搜集到的資料發送到 Logstash,經 Logstash 解析、過濾後,将其發送到 Elasticsearch 存儲,并由 Kibana 呈現給使用者。詳見圖 3。
圖 3. Beats 作為日志搜集器
這種架構解決了 Logstash 在各伺服器節點上占用系統資源高的問題。相比 Logstash,Beats 所占系統的 CPU 和記憶體幾乎可以忽略不計。另外,Beats 和 Logstash 之間支援 SSL/TLS 加密傳輸,用戶端和伺服器雙向認證,保證了通信安全。
是以這種架構适合對資料安全性要求較高,同時各伺服器性能比較敏感的場景。
2.4 引入消息隊列機制的架構
這種架構使用 Logstash 從各個資料源搜集資料,然後經消息隊列輸出插件輸出到消息隊列中。目前 Logstash 支援 Kafka、Redis、RabbitMQ 等常見消息隊列。然後 Logstash 通過消息隊列輸入插件從隊列中擷取資料,分析過濾後經輸出插件發送到 Elasticsearch,最後通過 Kibana 展示。詳見圖 4。
圖 4. 引入消息隊列機制的架構
這種架構适合于日志規模比較龐大的情況。但由于 Logstash 日志解析節點和 Elasticsearch 的負荷比較重,可将他們配置為叢集模式,以分擔負荷。引入消息隊列,均衡了網絡傳輸,進而降低了網絡閉塞,尤其是丢失資料的可能性,但依然存在 Logstash 占用系統資源過多的問題。
2.5 基于 Filebeat 架構的配置部署詳解
前面提到 Filebeat 已經完全替代了 Logstash-Forwarder 成為新一代的日志采集器,同時鑒于它輕量、安全等特點,越來越多人開始使用它。這個章節将詳細講解如何部署基于 Filebeat 的 ELK 集中式日志解決方案,具體架構見圖 5。
圖 5. 基于 Filebeat 的 ELK 叢集架構
因為免費的 ELK 沒有任何安全機制,是以這裡使用了 Nginx 作反向代理,避免使用者直接通路 Kibana 伺服器。加上配置 Nginx 實作簡單的使用者認證,一定程度上提高安全性。另外,Nginx 本身具有負載均衡的作用,能夠提高系統通路性能。
3.1下載下傳和安裝key檔案
<code>sudo rpm --import https://packages.elastic.co/GPG-KEY-elasticsearch</code>
3.2 建立yum源檔案
3.3 開始安裝
<code>sudo yum install filebeat</code>
3.4 啟動服務
收集日志
這裡我們先以收集docker日志為例,簡單來介紹一下filebeat的配置檔案該如何編寫。具體内容如下:
和我們看的一樣,其實并沒有太多的内容。我們采集/var/lib/docker/containers//.log,即filebeat所在節點的所有容器的日志。輸出的位置是我們ElasticSearch的服務位址,這裡我們直接将log輸送給ES,而不通過Logstash中轉。
再啟動之前,我們還需要向ES送出一個filebeat index template,以便讓elasticsearch知道filebeat輸出的日志資料都包含哪些屬性和字段。filebeat.template.json這個檔案安裝完之後就有,無需自己編寫,找不到的同學可以通過find查找。加載模闆到elasticsearch中:
重新開機服務
<code>systemctl restart filebeat</code>
提示:如果你啟動的是一個filebeat容器,需要将/var/lib/docker/containers目錄挂載到該容器中;
Kibana配置
如果上面配置都沒有問題,就可以通路Kibana,不過這裡需要添加一個新的index pattern。按照manual中的要求,對于filebeat輸送的日志,我們的index name or pattern應該填寫為:"filebeat-*"。