本文來自AI新媒體量子位(QbitAI)
GPU記憶體太小可能是神經網絡訓練過程中最大的攔路虎。
不怕,用這個OpenAI推出的gradient-checkpointing程式包,對于前饋模型來說,僅僅需要增加20%的計算時間,這個程式包,GPU就能适應十倍大的模型。
還有這種操作?
訓練神經網絡對記憶體的要求随着網絡的深度和batch-size呈線性增長。在記憶體有限的情況下,如果想訓練深層模型,并且增加batch-size,很多研究人員會采用KFAC這樣的二階方法。與小批量的SGD相比,這種方法發需要學習較少的樣例。
重點來了。昨天,OpenAI的研究科學家Tim Salimans和前Google Brain工程師的資料科學家Yaroslav Bulatov兩人釋出了一個python/TensorFlow包,名為gradient-checkpointing。
這個程式包使用了“用亞線性的存儲成本訓練神經網絡”的技術,為簡單的前饋網絡提供了等價的記憶體存儲,同時能為一般的神經網絡節省記憶體,比如多層架構。
将這個程式包應用到TensorFlow官方CIFAR10 ResNet示例中。在batch size=1280的情況下,将記憶體和執行時間情況如下圖所示。
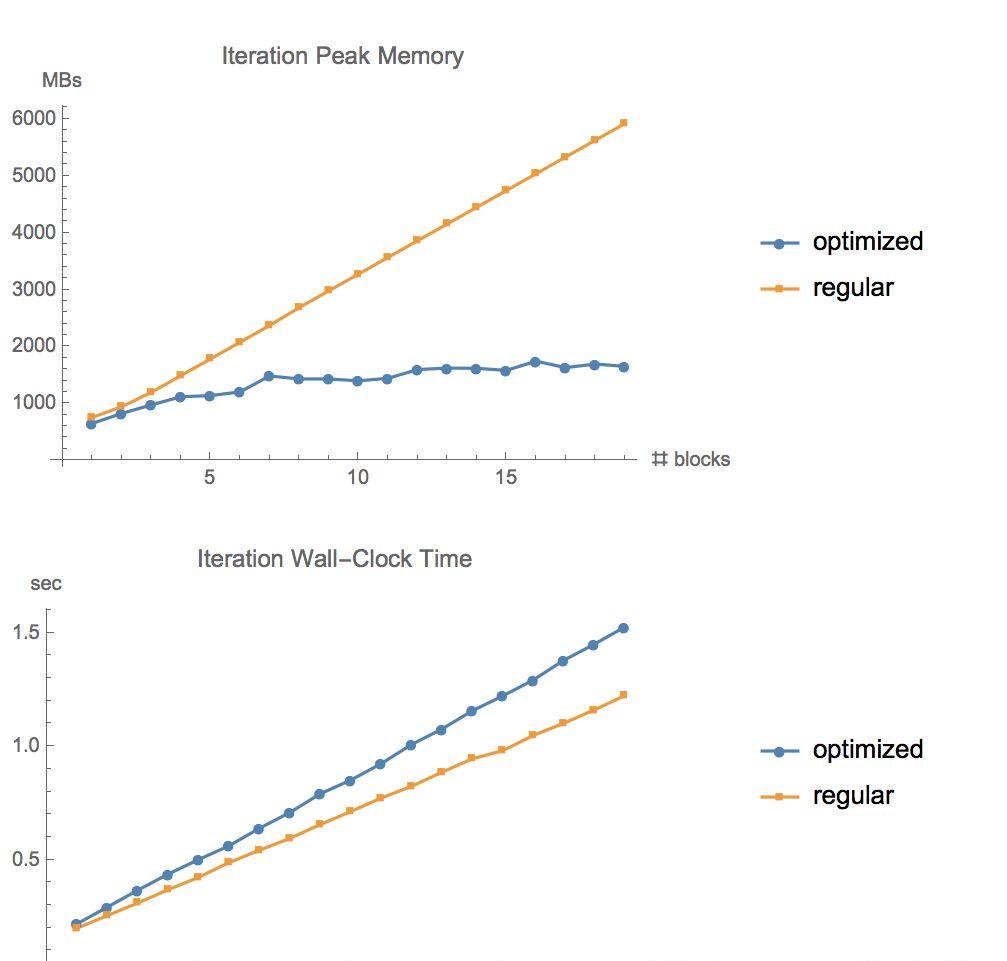
正常反向傳播為線性擴充,但優化後的方法以深度的平方根方式擴充。當我們在更深層次的網絡上嘗試時,差異就更明顯了。

用标準方法,運作這個疊代需要60GB的記憶體,但新方法隻需6GB的RAM。
再來看看計算時間。在實驗中,在GTX1080上的運作時間增加了20%,在V100 GPU上時間增加了30%。
如果想了解這個程式包是如何節約記憶體的,可以移步GitHub一探究竟:
https://github.com/openai/gradient-checkpointing
本文作者:安妮
原文釋出時間:2018-01-16