問題背景
給出N個集合,找到相似的集合對,如何實作呢?直覺的方法是比較任意兩個集合。那麼可以十分精确的找到每一對相似的集合,但是時間複雜度是O(n2)。當N比較小時,比如K級,此算法可以在接受的時間範圍内完成,但是如果N變大時,比B級,甚至P級,那麼需要的時間是不能夠被接受的。比如N= 1B = 1,000,000,000。一台計算機每秒可以比較1,000,000,000對集合是否相等。那麼大概需要<b>15</b><b>年</b>的時間才能找到所有相似的集合!
上面的算法雖然效率很低,但是結果會很精确,因為檢查了每一對集合。假如,N個集合中隻有少數幾對集合相似,絕大多數集合都不等呢?那麼根據上述算法,絕大多數檢測的結果是兩個結合不相似,可以說這些檢測“浪費了計算時間”。是以,如果能找到一種算法,将大體上相似的集合聚到一起,縮小比對的範圍,這樣隻用檢測較少的集合對,就可以找到絕大多數相似的集合對,大幅度減少時間開銷。雖然犧牲了一部分精度,但是如果能夠将時間大幅度減少,這種算法還是可以接受的。接下來的内容講解如何使用Minhash和LSH(Locality-sensitive Hashing)來實作上述目的,在相似的集合較少的情況下,可以在O(n)時間找到大部分相似的集合對。
Jaccard相似度
判斷兩個集合是否相等,一般使用稱之為Jaccard相似度的算法(後面用Jac(S1,S2)來表示集合S1和S2的Jaccard相似度)。舉個列子,集合X = {a,b,c},Y = {b,c,d}。那麼Jac(X,Y) = 2 / 3 = 0.67。也就是說,結合X和Y有67%的元素相同。下面是形式的表述Jaccard相似度公式:
Jac(X,Y) = |X∩Y| / |X∪Y|
也就是兩個結合交集的個數比上兩個集合并集的個數。範圍在[0,1]之間。
降維技術Minhash
原始問題的關鍵在于計算時間太長。是以,如果能夠找到一種很好的方法将原始集合壓縮成更小的集合,而且又不失去相似性,那麼可以縮短計算時間。Minhash可以幫助我們解決這個問題。舉個例子,S1 = {a,d,e},S2 = {c, e},設全集U = {a,b,c,d,e}。集合可以如下表示:
行号
元素
S1
S2
類别
1
a
Y
2
b
Z
3
c
4
d
5
e
X
表1
表1中,清單示集合,行表示元素,值1表示某個集合具有某個值,0則相反(X,Y,Z的意義後面讨論)。Minhash算法大體思路是:采用一種hash函數,将元素的位置均勻打亂,然後将新順序下每個集合第一個元素作為該集合的特征值。比如哈希函數h1(i) = (i + 1) % 5,其中i為行号。作用于集合S1和S2,得到如下結果:
<b>Minhash</b>
表2
這時,Minhash(S1) = e,Minhash(S2) = e。也就是說用元素e表示S1,用元素e表示集合S2。那麼這樣做是否科學呢?進一步,如果Minhash(S1) 等于Minhash(S2),那麼S1是否和S2類似呢?
一個神奇的結論
P(Minhash(S1) = Minhash(S2)) = Jac(S1,S2)
在哈希函數h1均勻分布的情況下,集合S1的Minhash值和集合S2的Minhash值相等的機率等于集合S1與集合S2的Jaccard相似度,下面簡單分析一下這個結論。
S1和S2的每一行元素可以分為三類:
l <b>X</b><b>類 </b>均為1。比如表2中的第1行,兩個集合都有元素e。
l <b>Y</b><b>類 </b>一個為1,另一個為0。比如表2中的第2行,表明S1有元素a,而S2沒有。<b></b>
l <b>Z</b><b>類 </b>均為0。比如表2中的第3行,兩個集合都沒有元素b。<b></b>
這裡忽略所有Z類的行,因為此類行對兩個集合是否相似<b>沒有任何貢獻</b>。由于哈希函數将原始行号<b>均勻</b>分布到新的行号,這樣可以認為在新的行号排列下,任意一行出現X類的情況的機率為|X|/(|X|+|Y|)。這裡為了友善,将任意位置設為第一個出現X類行的行号。是以P(第一個出現X類) = |X|/(|X|+|Y|) = Jac(S1,S2)。這裡很重要的一點就是要保證哈希函數可以将數值均勻分布,盡量減少沖撞。
一般而言,會找出一系列的哈希函數,比如h個(h << |U|),為每一個集合計算h次Minhash值,然後用h個Minhash值組成一個摘要來表示目前集合(注意Minhash的值的位置需要保持一緻)。舉個列子,還是基于上面的例子,現在又有一個哈希函數h2(i) = (i -1)% 5。那麼得到如下集合:
表3
是以,現在用摘要表示的原始集合如下:
哈希函數
h1(i) = (i + 1) % 5
h2(i) = (i - 1) % 5
表4
從表四還可以得到一個結論,令X表示Minhash摘要後的集合對應行相等的次數(比如表4,X=1,因為哈希函數h1情況下,兩個集合的minhash相等,h2不等):
X ~ B(h,Jac(S1,S2))
X符合次數為h,機率為Jac(S1,S2)的二項分布。那麼期望E(X) = h * Jac(S1,S2) = 2 * 2 / 3 = 1.33。也就是每2個hash計算Minhash摘要,可以期望有1.33元素對應相等。
是以,Minhash在壓縮原始集合的情況下,保證了集合的相似度沒有被破壞。
LSH – 局部敏感哈希
現在有了原始集合的摘要,但是還是沒有解決最初的問題,仍然需要周遊所有的集合對,,才能所有相似的集合對,複雜度仍然是O(n2)。是以,接下來描述解決這個問題的核心思想LSH。其基本思路是将相似的集合聚集到一起,減小查找範圍,避免比較不相似的集合。仍然是從例子開始,現在有5個集合,計算出對應的Minhash摘要,如下:
S3
S4
S5
區間1
區間2
f
g
區間3
h
區間4
表5
上面的集合摘要采用了12個不同的hash函數計算出來,然後分成了B = 4個區間。前面已經分析過,任意兩個集合(S1,S2)對應的Minhash值相等的機率r = Jac(S1,S2)。先分析區間1,在這個區間内,P(集合S1等于集合S2) = r3。是以隻要S1和S2的Jaccard相似度越高,在區間1内越有可能完成全一緻,反過來也一樣。那麼P(集合S1不等于集合S2) = 1 - r3。現在有4個區間,其他區間與第一個相同,是以P(4個區間上,集合S1都不等于集合S2) = (1 – r3)4。P(4個區間上,至少有一個區間,集合S1等于集合S2) = 1 - (1 – r3)4。這裡的機率是一個r的函數,形狀猶如一個S型,如下:
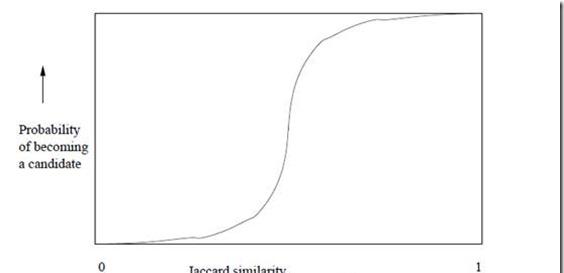
圖1
如果令區間個數為B,每個區間内的行數為C,那麼上面的公式可以形式的表示為:
P(B個區間中至少有一個區間中兩個結合相等) = 1 - (1 – rC)B
領r = 0.4,C=3,B = 100。上述公式計算的機率為0.9986585。這表明兩個Jaccard相似度為0.4的集合在至少一個區間内沖撞的機率達到了99.9%。根據這一事實,我們隻需要選取合适的B和C,和一個沖撞率很低的hash函數,就可以将相似的集合至少在一個區間内沖撞,這樣也就達成了本節最開始的目的:将相似的集合放到一起。具體的方法是為B個區間,準備B個hash表,和區間編号一一對應,然後用hash函數将每個區間的部分集合映射到對應hash表裡。最後周遊所有的hash表,将沖撞的集合作為候選對象進行比較,找出相識的集合對。整個過程是采用O(n)的時間複雜度,因為B和C均是常量。由于聚到一起的集合相比于整體比較少,是以在這小範圍内互相比較的時間開銷也可以計算為常量,那麼總體的計算時間也是O(n)。
總結
以上隻是描述了Minhash和LSH尋找相似集合的算法架構,作為學習筆記和備忘錄。還有一些算法細節沒有讨論。希望後面有機會,可以在海量資料的情況下使用這個算法。
參考資料
<b>聲明:如有轉載本博文章,請注明出處。您的支援是我的動力!文章部分内容來自網際網路,本人不負任何法律責任。</b>
本文轉自bourneli部落格園部落格,原文連結:http://www.cnblogs.com/bourneli/archive/2013/04/04/2999767.html,如需轉載請自行聯系原作者
![查找算法之二分查找查找算法之二分查找[圖]](data:image/gif;base64,R0lGODlhAQABAIAAAP///wAAACwAAAAAAQABAAACAkQBADs=)