在項目開發時,有時候想知道源碼檔案中有多少字尾名為.cc、.c、.h的檔案。下面介紹Linux幾種方法統計字尾名為.cc、.c、.h的檔案數的方法。
我以python3的源代碼為例,python3的源碼共有檔案數:
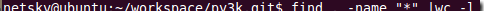
這段時間在學習python3,我就把它作為例子啦。感慨下:Python3跟Python2比變化了好多!有興趣的同學可以從代碼庫中checkout代碼研究研究,過程如下:(Python3使用git管理代碼) mkdir py3k.git cd py3k.git git init git svn init svn+ssh://[email protected]/python/branches/py3k git remote add git-svn git://code.python.org/python/branches/py3k git config remote.git-svn.fetch refs/heads/master:refs/remotes/git-svn git fetch git-svn git pull git-svn master
分别統計.cc和.c/.h的檔案數,然後加起來。
1
<code>find</code> <code>. -name</code><code>"*.cc"</code> <code>|</code><code>wc</code> <code>-l ;</code><code>find</code> <code>. -name </code><code>"*.[c|h]"</code> <code>|</code><code>wc</code> <code>-l</code>
結果如下:

雖然可以得到正确結果,不過就看上去比較醜。
<code>find</code> <code>. \( -name</code><code>"*.cc"</code> <code>-or -name</code><code>"*.c"</code> <code>-or -name</code><code>"*.h"</code> <code>\) |</code><code>wc</code> <code>-l</code>
使用-or指令連接配接多個表達式,注意使用圓括号“()”把所有的-name表達式括起來,并且需要轉義!結果如下:
<code>find</code> <code>. -iregex</code><code>".*\.\(cc\|h\|c\)$"</code> <code>|</code><code>wc</code> <code>-l</code>
使用正規表達式,但是需要注意進行轉義。結果如下:
附常用正規表達式符号意義: \ 将下一個字元标記為一個特殊字元、或一個原義字元、或一個後向引用、或一個八進制轉義符。 ^ 比對輸入字元串的開始位置。如果設定了 RegExp 對象的Multiline 屬性,^ 也比對 ’\n’ 或 ’\r’ 之後的位置。 $ 比對輸入字元串的結束位置。如果設定了 RegExp 對象的Multiline 屬性,$ 也比對 ’\n’ 或 ’\r’ 之前的位置。 * 比對前面的子表達式零次或多次。 + 比對前面的子表達式一次或多次。+ 等價于 {1,}。 ? 比對前面的子表達式零次或一次。? 等價于 {0,1}。 {n} n 是一個非負整數,比對确定的n 次。 {n,} n 是一個非負整數,至少比對n 次。 {n,m} m 和 n 均為非負整數,其中n <= m。最少比對 n 次且最多比對 m 次。在逗号和兩個數之間不能有空格。 ? 當該字元緊跟在任何一個其他限制符 (*, +, ?, {n}, {n,}, {n,m}) 後面時,比對模式是非貪婪的。非貪婪模式盡可能少的比對所搜尋的字元串,而預設的貪婪模式則盡可能多的比對所搜尋的字元串。 . 比對除 “\n” 之外的任何單個字元。要比對包括 ’\n’ 在内的任何字元,請使用象 ’[.\n]’ 的模式。 (pattern) 比對pattern 并擷取這一比對。 (?:pattern) 比對pattern 但不擷取比對結果,也就是說這是一個非擷取比對,不進行存儲供以後使用。 (?=pattern) 正向預查,在任何比對 pattern 的字元串開始處比對查找字元串。這是一個非擷取比對,也就是說,該比對不需要擷取供以後使用。 (?!pattern) 負向預查,與(?=pattern)作用相反 x|y 比對 x 或 y。 [xyz] 字元集合。 [^xyz] 負值字元集合。 [a-z] 字元範圍,比對指定範圍内的任意字元。 [^a-z] 負值字元範圍,比對任何不在指定範圍内的任意字元。 \b 比對一個單詞邊界,也就是指單詞和空格間的位置。 \B 比對非單詞邊界。 \cx 比對由x指明的控制字元。 \d 比對一個數字字元。等價于 [0-9]。 \D 比對一個非數字字元。等價于 [^0-9]。 \f 比對一個換頁符。等價于 \x0c 和 \cL。 \n 比對一個換行符。等價于 \x0a 和 \cJ。 \r 比對一個回車符。等價于 \x0d 和 \cM。 \s 比對任何空白字元,包括空格、制表符、換頁符等等。等價于[ \f\n\r\t\v]。 \S 比對任何非空白字元。等價于 [^ \f\n\r\t\v]。 \t 比對一個制表符。等價于 \x09 和 \cI。 \v 比對一個垂直制表符。等價于 \x0b 和 \cK。 \w 比對包括下劃線的任何單詞字元。等價于’[A-Za-z0-9_]’。 \W 比對任何非單詞字元。等價于 ’[^A-Za-z0-9_]’。 \xn 比對 n,其中 n 為十六進制轉義值。十六進制轉義值必須為确定的兩個數字長。 \num 比對 num,其中num是一個正整數。對所擷取的比對的引用。 \n 辨別一個八進制轉義值或一個後向引用。如果 \n 之前至少 n 個擷取的子表達式,則 n 為後向引用。否則,如果 n 為八進制數字 (0-7),則 n 為一個八進制轉義值。 \nm 辨別一個八進制轉義值或一個後向引用。如果 \nm 之前至少有is preceded by at least nm 個擷取得子表達式,則 nm 為後向引用。如果 \nm 之前至少有 n 個擷取,則 n 為一個後跟文字 m 的後向引用。如果前面的條件都不滿足,若 n 和 m 均為八進制數字 (0-7),則 \nm 将比對八進制轉義值 nm。 \nml 如果 n 為八進制數字 (0-3),且 m 和 l 均為八進制數字 (0-7),則比對八進制轉義值 nml。 \un 比對 n,其中 n 是一個用四個十六進制數字表示的Unicode字元。 摘自《精通正規表達式》
作者:吳秦
出處:http://www.cnblogs.com/skynet/
【新浪微網誌】 張昺華--sky
【twitter】 @sky2030_
【facebook】 張昺華 zhangbinghua
本文版權歸作者和部落格園共有,歡迎轉載,但未經作者同意必須保留此段聲明,且在文章頁面明顯位置給出原文連接配接,否則保留追究法律責任的權利.