<b>閱讀目錄</b>
<a href="http://www.cnblogs.com/asxinyu/p/MachineLearning_PageRank_1.html#_label0">1.PageRank算法介紹</a>
<a href="http://www.cnblogs.com/asxinyu/p/MachineLearning_PageRank_1.html#_label1">2.PageRank算法原理</a>
<a href="http://www.cnblogs.com/asxinyu/p/MachineLearning_PageRank_1.html#_label2">3.PageRank算法基本過程</a>
<a href="http://www.cnblogs.com/asxinyu/p/MachineLearning_PageRank_1.html#_label3">4.随機沖浪模型</a>
考慮到知識的複雜性,連續性,将本算法及應用分為3篇文章,請關注,将在本月逐漸發表。
Pagerank是Google排名運算法則(排名公式)的一部分,是Google用于用來辨別網頁的等級/重要性的一種方法,是Google用來衡量一個網站的好壞的唯一标準。在揉合了諸如Title辨別和Keywords辨別等所有其它因素之後,Google通過PageRank來調整結果,使那些更具“等級/重要性”的網頁在搜尋結果中令網站排名獲得提升,進而提高搜尋結果的相關性和品質。鑒于Google的巨大成功和PageRank的巨大作用,已經入學了機器學習的十大算法之一。今天就帶大家走近PageRank,簡述其原理以及應用的C#實作。由于個人是專業做足球賽事預測,是以應用就拿足球勝平負的預測作為例子了。原理和過程都差不多,看大家如何分析問題了。
鑒于PageRank算法的資料很多,也很成熟,是以相關的介紹和原理部分就直接引用了相關著作上面的話,在應用部分是個人的代碼和思路,引用原始出處已經标明。
PageRank,簡稱為PR值,又稱網頁級别、Google左側排名或佩奇排名。Pagerank取自Google的創始人LarryPage,它是Google排名運算法則的一部分,Pagerank是Google對網頁重要性的評估,是Google用來衡量一個網站的好壞的唯一标準。Google通過PageRank來調整結果,使那些更具“重要性”的網頁在搜尋結果中另網站排名獲得提升,進而提高搜尋結果的相關性和品質。PR值的級别從1到10級,10級為滿分。PR值越高說明該網頁越受歡迎。 PageRank這個概念引自學術中一篇論文的被引述的頻度——即被别人引述的次數越多,一般判斷這篇論文的權威性就越高。Google有一套自動化方法來計算這些投票。Google的PageRank分值從0到10;PageRank為10表示最佳,但非常少見,類似裡氏震級(Richterscale),PageRank級别也不是線性的,而是按照一種指數刻度。這是一種奇特的數學術語,意思是PageRank4不是比PageRank3好一級——而可能會好6到7倍。是以,一個PageRank5的網頁和PageRank8的網頁之間的差距會比你可能認為的要大的多。PageRank較高的頁面的排名往往要比PageRank較低的頁面高,而這導緻了人們對連結的着魔。在整個SEO社群,人們忙于争奪、交換甚至銷售連結,它是過去幾年來人們關注的焦點,以至于Google修改了他的系統,并開始放棄某些類型的連結。比如,被人們廣泛接受的一條規定,來自缺乏内容的“linkfarm”(連結工廠)網站的連結将不會提供頁面的PageRank,從PageRank較高的頁面得到連結但是内容不相關(比如說某個流行的漫畫書網站連結到一個叉車規範頁面),也不會提供頁面的PageRank。Google選擇降低了PageRank對更新頻率,以便不鼓勵人們不斷的對其進行監測。 <a href="http://baike.haosou.com/doc/5496980-5734893.html" target="_blank">http://baike.haosou.com/doc/5496980-5734893.html</a>
PageRank算法是Google搜尋引擎對檢索結果的一種排序算法.它的基本思想主要是來自傳統文獻計量學中的文獻引文分析,即一篇文獻的品質和重要性可以通過其它文獻對其引用的數量和引文品質來衡量,也就是說,一篇文獻被其它文獻引用越多,并且引用它的文獻的品質越高,則該文獻本身就越重要.Google在給出頁面排序時也有兩條标準:一是看有多少超級連結指向它;二是要看超級連結指向它的那個頁面重要不重要.這兩條直覺的想法就是PageRank算法的數學基礎,也是Google搜尋引擎最基本的工作原理.PageRank算法利用了網際網路獨特的超連結結構.在龐大的超連結資源中,Google提取出上億個超級連結頁面進行分析,制作出一個巨大的網絡地圖.具體的講,就是把所有的網頁看作圖裡面相應的頂點,如果網頁A有—個指向網頁B的連結,則認為一條從頂點A到頂點B的有向邊.這樣就可以利用圖論來研究網絡的拓撲結構.PageRank算法正是利用網絡的拓撲結構來判斷網頁的重要性.具體來說,假如網頁A有—個指向網頁B的超連結,Google就認為網頁A投了網頁B一票,說明網頁A認為網頁B有連結價值,因而B可能是—個重要的網頁.Google根據指向網頁B的超連結數及其重要性來判斷頁面B的重要性,并賦予相應的頁面等級值(PageRank).網頁A的頁面等級值被平均分畫己給網頁A所連結指向的網頁,進而當網頁A的頁面等級值比較高時,則網頁B可從網頁A到它的超連結分得一定的重要性.根據這樣的分析,得到了高評價的重要頁面會被賦予較高的網頁等級,在檢索結果内的排名也會較高.頁面等級值(PageRank)是Google表示網頁重要性的綜合性名額,而且不會受到不同搜尋引擎的影響.當然,重要性高的頁面如果和檢索關鍵詞無關同樣也沒有任何意義.為此,Google使用了完善的超文本比對分析技術,使得能夠檢索出重要而且正确的網頁. [1].上述引用“趙國,宋建成.Google搜尋引擎的數學模型及其應用,西南民族大學學報自然科學版.2010,vol(36),3”
這一節我們還是采用趙國那篇論文的簡單例子,介紹PageRank的簡單過程以及對應的随機沖浪模型,可以讓你加深對算法的了解,同時這也是編寫代碼的重要依據。
PageRank算法的具體實作可以利用網頁所對應的圖的鄰接矩陣來表達超連結關系。是以要先寫出所對應圖的鄰接矩陣 A ,為了能将網頁的頁面等級值平均配置設定給該網頁所連結指向的網頁,需要對各個行向量進行歸一化處理,得到矩陣A1。PageRank算法的矩陣是将歸一化矩陣A1轉置所得矩陣W,稱之為 轉移機率矩陣(是不是和馬爾可夫鍊有點像,的确是與馬爾可夫鍊過程有着密切的關系),其特征是各個列列向量之和為全機率1,各個行矢量表示狀态之間的轉移機率,轉置的原因是PageRank算法重視的某個頁面被多少個頁面連結,而不是連結到多少個頁面。各個網頁的頁面等級制就是求這個轉義機率矩陣W的最大特征值所屬的特征向量。是以可以看出,PageRank的應用也主要是對某些過程對象進行重要等級排名。
例如,先假設有下面的圖鄰接矩陣:
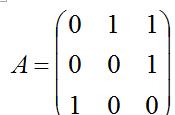
為了能将網頁的頁面等級值平均配置設定給該網頁所連結指向的網頁,對各個行向量進行歸一化處理,得:

将歸一化所得的矩陣轉置,所得到的轉移機率矩陣W:
根據上述公式和轉移機率矩陣,可以求得其最大特征值為:
對應的非負特征向量為:
是以可以确定網頁的排序為C,A,B,而A,C的排序并沒有很顯著的差别,但是由于指向C的連結多一些,是以可以考慮排在前面。至于其中的特征值計算和非負特征向量,是一個比較簡單的線性代數問題,如果不懂的可以去查下資料,本部落格也有相應的Math.NET數學元件可以借鑒,可以很容易的解決這些基礎的問題,連結看菜單導航。
随機沖浪模型(Random Surfer Model)是為了更加的符合實際情況而對上述PageRank基本模型進行的改進。PageRank算法原理中假設所有的網頁形成一個閉合的連結圖,除了這些文檔以外沒有其他任何連結的出入,并且每個網頁能從其他網頁通過超連結達到.但是在現實的網絡中,并不完全是這樣的情況.當一個頁面沒有對外連結的時候,它的PageRank值就不能被配置設定給其它的頁面。同樣道理,隻有對外連結接而沒有傳入連結接的頁面也是存在的。但PageRank并不考慮這樣的頁面.在現實中的頁面,無論怎樣順着連結前進,僅僅順着連結是絕對不能進入的頁面群總歸是存在的。是以為了解決這個問題,提出了使用者的随機沖浪模型:使用者雖然在大多數情況下都順着目前頁面中的連結前進,但也有少數情況會突然重新打開浏覽器随機進入到完全無關的頁面。這樣就可以用公式表示相應的機率矩陣:
還是考慮第3節中的問題,我們取d=0.5,可以計算相應的機率轉移矩陣為:
計算得到其最大特征值為1,相應的特征向量為:
是以排序的結果C,A,B合理一些,也更加符合實際情況。
接下來我們将通過上述論文中的一個例子來介紹PageRank的實際應用與C#實作過程,請關注部落格。
本文轉自資料之巅部落格園部落格,原文連結:http://www.cnblogs.com/asxinyu/p/MachineLearning_PageRank_1.html,如需轉載請自行聯系原作者