Linux 核心使用 <code>task_struct</code> 資料結構來關聯所有與程序有關的資料和結構,Linux 核心所有涉及到程序和程式的所有算法都是圍繞該資料結建構立的,是核心中最重要的資料結構之一。該資料結構在核心檔案 <code>include/linux/sched.h</code> 中定義,在Linux 3.8 的核心中,該資料結構足足有 380 行之多,在這裡我不可能逐項去描述其表示的含義,本篇文章隻關注該資料結構如何來組織和管理程序ID的。
要想了解核心如何來組織和管理程序ID,先要知道程序ID的類型:
PID:這是 Linux 中在其命名空間中唯一辨別程序而配置設定給它的一個号碼,稱做程序ID号,簡稱PID。在使用 fork 或 clone 系統調用時産生的程序均會由核心配置設定一個新的唯一的PID值。
TGID:在一個程序中,如果以CLONE_THREAD标志來調用clone建立的程序就是該程序的一個線程,它們處于一個線程組,該線程組的ID叫做TGID。處于相同的線程組中的所有程序都有相同的TGID;線程組組長的TGID與其PID相同;一個程序沒有使用線程,則其TGID與PID也相同。
PGID:另外,獨立的程序可以組成程序組(使用setpgrp系統調用),程序組可以簡化向所有組内程序發送信号的操作,例如用管道連接配接的程序處在同一程序組内。程序組ID叫做PGID,程序組内的所有程序都有相同的PGID,等于該組組長的PID。
SID:幾個程序組可以合并成一個會話組(使用setsid系統調用),可以用于終端程式設計。會話組中所有程序都有相同的SID。
命名空間是為作業系統層面的虛拟化機制提供支撐,目前實作的有六種不同的命名空間,分别為mount命名空間、UTS命名空間、IPC命名空間、使用者命名空間、PID命名空間、網絡命名空間。命名空間簡單來說提供的是對全局資源的一種抽象,将資源放到不同的容器中(不同的命名空間),各容器彼此隔離。命名空間有的還有層次關系,如PID命名空間,圖1 為命名空間的層次關系圖。
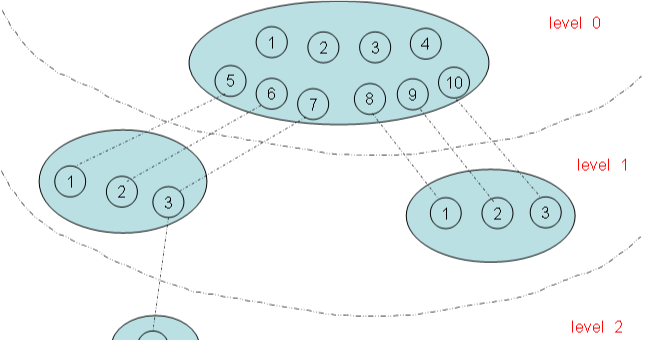
圖1 命名空間的層次關系
在上圖有四個命名空間,一個父命名空間衍生了兩個子命名空間,其中的一個子命名空間又衍生了一個子命名空間。以PID命名空間為例,由于各個命名空間彼此隔離,是以每個命名空間都可以有 PID 号為 1 的程序;但又由于命名空間的層次性,父命名空間是知道子命名空間的存在,是以子命名空間要映射到父命名空間中去,是以上圖中 level 1 中兩個子命名空間的六個程序分别映射到其父命名空間的PID 号5~10。
命名空間增大了 PID 管理的複雜性,對于某些程序可能有多個PID——在其自身命名空間的PID以及其父命名空間的PID,凡能看到該程序的命名空間都會為其配置設定一個PID。是以就有:
全局ID:在核心本身和初始命名空間中唯一的ID,在系統啟動期間開始的 init 程序即屬于該初始命名空間。系統中每個程序都對應了該命名空間的一個PID,叫全局ID,保證在整個系統中唯一。
局部ID:對于屬于某個特定的命名空間,它在其命名空間内配置設定的ID為局部ID,該ID也可以出現在其他的命名空間中。
Linux 核心在設計管理ID的資料結構時,要充分考慮以下因素:
如何快速地根據程序的 task_struct、ID類型、命名空間找到局部ID
如何快速地根據局部ID、命名空間、ID類型找到對應程序的 task_struct
如何快速地給新程序在可見的命名空間内配置設定一個唯一的 PID
如果将所有因素考慮到一起,将會很複雜,下面将會由簡到繁設計該結構。
如果先不考慮程序之間的關系,不考慮命名空間,僅僅是一個PID号對應一個task_struct,那麼我們可以設計這樣的資料結構:
每個程序的 task_struct 結構體中有一個指向 pid 結構體的指針,pid 結構體包含了 PID 号。結構示意圖如圖2。

圖2 一個task_struct對應一個PID
圖中還有兩個結構上面未提及:
pid_hash[]: 這是一個hash表的結構,根據 pid 的 nr 值哈希到其某個表項,若有多個 pid 結構對應到同一個表項,這裡解決沖突使用的是散清單法。這樣,就能解決開始提出的第2個問題了,根據PID值怎樣快速地找到task_struct結構體:
首先通過 PID 計算 pid 挂接到哈希表 pid_hash[] 的表項
周遊該表項,找到 pid 結構體中 nr 值與 PID 值相同的那個 pid
再通過該 pid 結構體的 tasks 指針找到 node
最後根據核心的 container_of 機制就能找到 task_struct 結構體
pid_map:這是一個位圖,用來唯一配置設定PID值的結構,圖中灰色表示已經配置設定過的值,在建立一個程序時,隻需在其中找到一個為配置設定過的值賦給 pid 結構體的 nr,再将pid_map 中該值設為已配置設定标志。這也就解決了上面的第3個問題——如何快速地配置設定一個全局的PID。
至于上面的第1個問題就更加簡單,已知 task_struct 結構體,根據其 pid_link 的 pid 指針找到 pid 結構體,取出其 nr 即為 PID 号。
如果考慮程序之間有複雜的關系,如線程組、程序組、會話組,這些組均有組ID,分别為 TGID、PGID、SID,是以原來的 task_struct 中pid_link 指向一個 pid 結構體需要增加幾項,用來指向到其組長的 pid 結構體,相應的 struct pid 原本隻需要指回其 PID 所屬程序的task_struct,現在要增加幾項,用來連結那些以該 pid 為組長的所有程序組内程序。資料結構如下:
上面 ID 的類型 PIDTYPE_MAX 表示 ID 類型數目。之是以不包括線程組ID,是因為核心中已經有指向到線程組的 task_struct 指針 group_leader,線程組 ID 無非就是 group_leader 的PID。
假如現在有三個程序A、B、C為同一個程序組,程序組長為A,這樣的結構示意圖如圖3。
圖3 增加ID類型的結構
關于上圖有幾點需要說明:
圖中省去了 pid_hash 以及 pid_map 結構,因為第一種情況類似;
程序B和C的程序組組長為A,那麼 pids[PIDTYPE_PGID] 的 pid 指針指向程序A的 pid 結構體;
程序A是程序B和C的組長,程序A的 pid 結構體的 tasks[PIDTYPE_PGID] 是一個散清單的頭,它将所有以該pid 為組長的程序連結起來。
再次回顧本節的三個基本問題,在此結構上也很好去實作。
若在第二種情形下再增加PID命名空間,一個程序就可能有多個PID值了,因為在每一個可見的命名空間内都會配置設定一個PID,這樣就需要改變 pid 的結構了,如下:
在 pid 結構體中增加了一個表示該程序所處的命名空間的層次level,以及一個可擴充的 upid 結構體。對于struct upid,表示在該命名空間所配置設定的程序的ID,ns指向是該ID所屬的命名空間,pid_chain 表示在該命名空間的散清單。
舉例來說,在level 2 的某個命名空間上建立了一個程序,配置設定給它的 pid 為45,映射到 level 1 的命名空間,配置設定給它的 pid 為 134;再映射到 level 0 的命名空間,配置設定給它的 pid 為289,對于這樣的例子,如圖4所示為其表示:
圖4 增加PID命名空間之後的結構圖
圖中關于如果配置設定唯一的 PID 沒有畫出,但也是比較簡單,與前面兩種情形不同的是,這裡配置設定唯一的 PID 是有命名空間的容器的,在PID命名空間内必須唯一,但各個命名空間之間不需要唯一。
至此,已經與 Linux 核心中資料結構相差不多了。
有了上面的複雜的資料結構,再加上散清單等資料結構的操作,就可以寫出我們前面所提到的三個問題的函數了:
根據程序的 task_struct、ID類型、命名空間,可以很容易獲得其在命名空間内的局部ID:
獲得與task_struct 關聯的pid結構體。輔助函數有 task_pid、task_tgid、task_pgrp和task_session,分别用來擷取不同類型的ID的pid 執行個體,如擷取 PID 的執行個體:
擷取線程組的ID,前面也說過,TGID不過是線程組組長的PID而已,是以:
而獲得PGID和SID,首先需要找到該線程組組長的task_struct,再獲得其相應的 pid:
獲得 pid 執行個體之後,再根據 pid 中的numbers 數組中 uid 資訊,獲得局部PID。
這裡值得注意的是,由于PID命名空間的層次性,父命名空間能看到子命名空間的内容,反之則不能,是以,函數中需要確定目前命名空間的level 小于等于産生局部PID的命名空間的level。
除了這個函數之外,核心還封裝了其他函數用來從 pid 執行個體獲得 PID 值,如 pid_nr、pid_vnr 等。在此不介紹了。
結合這兩步,核心提供了更進一步的封裝,提供以下函數:
從函數名上就能推斷函數的功能,其實不外于封裝了上面的兩步。
根據局部ID、以及命名空間,怎樣獲得程序的task_struct結構體呢?也是分兩步:
獲得 pid 實體。根據局部PID以及命名空間計算在 pid_hash 數組中的索引,然後周遊散清單找到所要的 upid, 再根據核心的 container_of 機制找到 pid 執行個體。代碼如下:
根據ID類型取得task_struct 結構體。
核心還提供其它函數用來實作上面兩步:
具體函數實作的功能也比較簡單。
核心中使用下面兩個函數來實作配置設定和回收PID的:
在這裡我們不關注這兩個函數的實作,反而應該關注配置設定的 PID 如何在多個命名空間中可見,這樣需要在每個命名空間生成一個局部ID,函數 alloc_pid 為建立的程序配置設定PID,簡化版如下:
參考資料
深入Linux 核心架構(以前不覺得這本書寫得多好,現在倒發現還不錯,本文很多都是照抄上面的)
周徐達師弟的PPT(讓我受益匪淺的一次讨論,周由淺入深告訴我們該資料結構是如何設計出來的,本文主思路就是按照該PPT,在此 特别感謝!)
本文轉自張昺華-sky部落格園部落格,原文連結:http://www.cnblogs.com/sky-heaven/p/8086531.html,如需轉載請自行聯系原作者