負載均衡技術對于一個網站尤其是大型網站的web伺服器叢集來說是至關重要的!做好負載均衡架構,可以實作故障轉移和高可用環境,避免單點故障,保證網站健康持續運作。
由于業務擴充,網站的通路量不斷加大,負載越來越高。現需要在web前端放置nginx負載均衡,同時結合keepalived對前端nginx實作HA高可用。
1)nginx程序基于Master+Slave(worker)多程序模型,自身具有非常穩定的子程序管理功能。在Master程序配置設定模式下,Master程序永遠不進行業務處理,隻是進行任務分發,進而達到Master程序的存活高可靠性,Slave(worker)程序所有的業務信号都 由主程序發出,Slave(worker)程序所有的逾時任務都會被Master中止,屬于非阻塞式任務模型。
2)Keepalived是Linux下面實作VRRP備份路由的高可靠性運作件。基于Keepalived設計的服務模式能夠真正做到主伺服器和備份伺服器故障時IP瞬間無縫交接。二者結合,可以構架出比較穩定的軟體LB方案。
Keepalived介紹:
Keepalived是一個基于VRRP協定來實作的服務高可用方案,可以利用其來避免IP單點故障,類似的工具還有heartbeat、corosync、pacemaker。但是它一般不會單獨出現,而是與其它負載均衡技術(如lvs、haproxy、nginx)一起工作來達到叢集的高可用。
VRRP協定:
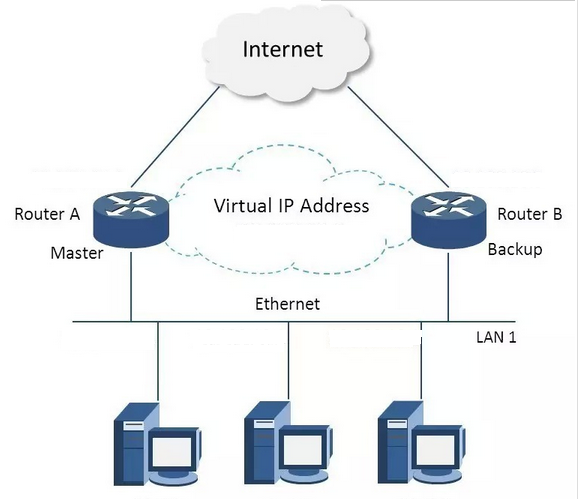
VRRP全稱 Virtual Router Redundancy Protocol,即 虛拟路由備援協定。可以認為它是實作路由器高可用的容錯協定,即将N台提供相同功能的路由器組成一個路由器組(Router Group),這個組裡面有一個master和多個backup,但在外界看來就像一台一樣,構成虛拟路由器,擁有一個虛拟IP(vip,也就是路由器所在區域網路内其他機器的預設路由),占有這個IP的master實際負責ARP相應和轉發IP資料包,組中的其它路由器作為備份的角色處于待命狀态。master會發多點傳播消息,當backup在逾時時間内收不到vrrp包時就認為master宕掉了,這時就需要根據VRRP的優先級來選舉一個backup當master,保證路由器的高可用。
在VRRP協定實作裡,虛拟路由器使用 00-00-5E-00-01-XX 作為虛拟MAC位址,XX就是唯一的 VRID (Virtual Router IDentifier),這個位址同一時間隻有一個實體路由器占用。在虛拟路由器裡面的實體路由器組裡面通過多點傳播IP位址 224.0.0.18 來定時發送通告消息。每個Router都有一個 1-255 之間的優先級别,級别最高的(highest priority)将成為主要(master)路由器。通過降低master的優先權可以讓處于backup狀态的路由器搶占(pro-empt)主路由器的狀态,兩個backup優先級相同的IP位址較大者為master,接管虛拟IP。
keepalived與heartbeat/corosync等比較:
Heartbeat、Corosync、Keepalived這三個叢集元件我們到底選哪個好呢?
首先要說明的是,Heartbeat、Corosync是屬于同一類型,Keepalived與Heartbeat、Corosync,根本不是同一類型的。
Keepalived使用的vrrp協定方式,虛拟路由備援協定 (Virtual Router Redundancy Protocol,簡稱VRRP);
Heartbeat或Corosync是基于主機或網絡服務的高可用方式;
簡單的說就是,Keepalived的目的是模拟路由器的高可用,Heartbeat或Corosync的目的是實作Service的高可用。
是以一般Keepalived是實作前端高可用,常用的前端高可用的組合有,就是我們常見的LVS+Keepalived、Nginx+Keepalived、HAproxy+Keepalived。而Heartbeat或Corosync是實作服務的高可用,常見的組合有Heartbeat v3(Corosync)+Pacemaker+NFS+Httpd 實作Web伺服器的高可用、Heartbeat v3(Corosync)+Pacemaker+NFS+MySQL 實作MySQL伺服器的高可用。總結一下,Keepalived中實作輕量級的高可用,一般用于前端高可用,且不需要共享存儲,一般常用于兩個節點的高可用。而Heartbeat(或Corosync)一般用于服務的高可用,且需要共享存儲,一般用于多節點的高可用。這個問題我們說明白了。
那heartbaet與corosync又應該選擇哪個好?
一般用corosync,因為corosync的運作機制更優于heartbeat,就連從heartbeat分離出來的pacemaker都說在以後的開發當中更傾向于corosync,是以現在corosync+pacemaker是最佳組合。
雙機高可用一般是通過虛拟IP(飄移IP)方法來實作的,基于Linux/Unix的IP别名技術。
雙機高可用方法目前分為兩種:
1)雙機主從模式:即前端使用兩台伺服器,一台主伺服器和一台熱備伺服器,正常情況下,主伺服器綁定一個公網虛拟IP,提供負載均衡服務,熱備伺服器處于空閑狀态;當主伺服器發生故障時,熱備伺服器接管主伺服器的公網虛拟IP,提供負載均衡服務;但是熱備伺服器在主機器不出現故障的時候,永遠處于浪費狀态,對于伺服器不多的網站,該方案不經濟實惠。
2)雙機主主模式:即前端使用兩台負載均衡伺服器,互為主備,且都處于活動狀态,同時各自綁定一個公網虛拟IP,提供負載均衡服務;當其中一台發生故障時,另一台接管發生故障伺服器的公網虛拟IP(這時由非故障機器一台負擔所有的請求)。這種方案,經濟實惠,非常适合于目前架構環境。
今天在此分享下Nginx+keepalived實作高可用負載均衡的主從模式的操作記錄:
keepalived可以認為是VRRP協定在Linux上的實作,主要有三個子產品,分别是core、check和vrrp。
core子產品為keepalived的核心,負責主程序的啟動、維護以及全局配置檔案的加載和解析。
check負責健康檢查,包括常見的各種檢查方式。
vrrp子產品是來實作VRRP協定的。

一、環境說明:
作業系統:centos6.8,64位
master機器(master-node):103.110.98.14/192.168.1.14
slave機器(slave-node):103.110.98.24/192.168.1.24
公用的虛拟IP(VIP):103.110.98.20 //負載均衡器上配置的域名都解析到這個VIP上
應用環境如下:
二、環境安裝
安裝nginx和keepalive服務(master-node和slave-node兩台伺服器上的安裝操作完全一樣)。
安裝依賴
[root@master-node ~]# yum -y install gcc pcre-devel zlib-devel openssl-devel
[root@master-node ~]# cd /usr/local/src/
安裝nginx
[root@master-node src]# tar -zvxf nginx-1.9.7.tar.gz
[root@master-node src]# cd nginx-1.9.7
添加www使用者,其中-M參數表示不添加使用者家目錄,-s參數表示指定shell類型
[root@master-node nginx-1.9.7]# useradd www -M -s /sbin/nologin
[root@master-node nginx-1.9.7]# vim auto/cc/gcc
#将這句注釋掉 取消Debug編譯模式 大概在179行
#CFLAGS="$CFLAGS -g"
[root@master-node nginx-1.9.7]# ./configure --prefix=/usr/local/nginx --user=www --group=www --with-http_ssl_module --with-http_flv_module --with-http_stub_status_module --with-http_gzip_static_module --with-pcre
[root@master-node nginx-1.9.7]# make && make install
安裝keepalived
[root@master-node src]# tar -zvxf keepalived-1.3.2.tar.gz
[root@master-node src]# cd keepalived-1.3.2
[root@master-node keepalived-1.3.2]# ./configure
[root@master-node keepalived-1.3.2]# make && make install
[root@master-node keepalived-1.3.2]# cp /usr/local/src/keepalived-1.3.2/keepalived/etc/init.d/keepalived /etc/rc.d/init.d/
[root@master-node keepalived-1.3.2]# cp /usr/local/etc/sysconfig/keepalived /etc/sysconfig/
[root@master-node keepalived-1.3.2]# mkdir /etc/keepalived
[root@master-node keepalived-1.3.2]# cp /usr/local/etc/keepalived/keepalived.conf /etc/keepalived/
[root@master-node keepalived-1.3.2]# cp /usr/local/sbin/keepalived /usr/sbin/
将nginx和keepalive服務加入開機啟動服務
[root@master-node keepalived-1.3.2]# echo "/usr/local/nginx/sbin/nginx" >> /etc/rc.local
[root@master-node keepalived-1.3.2]# echo "/etc/init.d/keepalived start" >> /etc/rc.local
三、配置服務
先關閉SElinux、配置防火牆 (master和slave兩台負載均衡機都要做)
[root@master-node ~]# vim /etc/sysconfig/selinux
#SELINUX=enforcing #注釋掉
#SELINUXTYPE=targeted #注釋掉
SELINUX=disabled #增加
[root@master-node ~]# setenforce 0 #使配置立即生效
[root@master-node ~]# vim /etc/sysconfig/iptables
.......
-A INPUT -s 103.110.98.0/24 -d 224.0.0.18 -j ACCEPT #允許多點傳播位址通信
-A INPUT -s 192.168.1.0/24 -d 224.0.0.18 -j ACCEPT
-A INPUT -s 103.110.98.0/24 -p vrrp -j ACCEPT #允許 VRRP(虛拟路由器備援協)通信
-A INPUT -s 192.168.1.0/24 -p vrrp -j ACCEPT
-A INPUT -p tcp -m state --state NEW -m tcp --dport 80 -j ACCEPT #開通80端口通路
[root@master-node ~]# /etc/init.d/iptables restart #重新開機防火牆使配置生效
1.配置nginx
master-node和slave-node兩台伺服器的nginx的配置完全一樣,主要是配置/usr/local/nginx/conf/nginx.conf的http,當然也可以配置vhost虛拟主機目錄,然後配置vhost下的比如LB.conf檔案。
其中:
多域名指向是通過虛拟主機(配置http下面的server)實作;
同一域名的不同虛拟目錄通過每個server下面的不同location實作;
到後端的伺服器在vhost/LB.conf下面配置upstream,然後在server或location中通過proxy_pass引用。
要實作前面規劃的接入方式,LB.conf的配置如下(添加proxy_cache_path和proxy_temp_path這兩行,表示打開nginx的緩存功能):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
<code>[root@master-node ~]</code><code># vim /usr/local/nginx/conf/nginx.conf</code>
<code>user www;</code>
<code>worker_processes 8;</code>
<code>#error_log logs/error.log;</code>
<code>#error_log logs/error.log notice;</code>
<code>#error_log logs/error.log info;</code>
<code>#pid logs/nginx.pid;</code>
<code>events {</code>
<code> </code><code>worker_connections 65535;</code>
<code>}</code>
<code>http {</code>
<code> </code><code>include mime.types;</code>
<code> </code><code>default_type application</code><code>/octet-stream</code><code>;</code>
<code> </code><code>charset utf-8;</code>
<code> </code>
<code> </code><code>######</code>
<code> </code><code>## set access log format</code>
<code> </code><code>log_format main </code><code>'$http_x_forwarded_for $remote_addr $remote_user [$time_local] "$request" '</code>
<code> </code><code>'$status $body_bytes_sent "$http_referer" '</code>
<code> </code><code>'"$http_user_agent" "$http_cookie" $host $request_time'</code><code>;</code>
<code> </code><code>#######</code>
<code> </code><code>## http setting</code>
<code> </code><code>sendfile on;</code>
<code> </code><code>tcp_nopush on;</code>
<code> </code><code>tcp_nodelay on;</code>
<code> </code><code>keepalive_timeout 65;</code>
<code> </code><code>proxy_cache_path </code><code>/var/www/cache</code> <code>levels=1:2 keys_zone=mycache:20m max_size=2048m inactive=60m;</code>
<code> </code><code>proxy_temp_path </code><code>/var/www/cache/tmp</code><code>;</code>
<code> </code><code>fastcgi_connect_timeout 3000;</code>
<code> </code><code>fastcgi_send_timeout 3000;</code>
<code> </code><code>fastcgi_read_timeout 3000;</code>
<code> </code><code>fastcgi_buffer_size 256k;</code>
<code> </code><code>fastcgi_buffers 8 256k;</code>
<code> </code><code>fastcgi_busy_buffers_size 256k;</code>
<code> </code><code>fastcgi_temp_file_write_size 256k;</code>
<code> </code><code>fastcgi_intercept_errors on;</code>
<code> </code><code>#</code>
<code> </code><code>client_header_timeout 600s;</code>
<code> </code><code>client_body_timeout 600s;</code>
<code> </code><code># client_max_body_size 50m;</code>
<code> </code><code>client_max_body_size 100m; </code><code>#允許用戶端請求的最大單個檔案位元組數</code>
<code> </code><code>client_body_buffer_size 256k; </code><code>#緩沖區代理緩沖請求的最大位元組數,可以了解為先儲存到本地再傳給使用者</code>
<code> </code><code>gzip</code> <code>on;</code>
<code> </code><code>gzip_min_length 1k;</code>
<code> </code><code>gzip_buffers 4 16k;</code>
<code> </code><code>gzip_http_version 1.1;</code>
<code> </code><code>gzip_comp_level 9;</code>
<code> </code><code>gzip_types text</code><code>/plain</code> <code>application</code><code>/x-javascript</code> <code>text</code><code>/css</code> <code>application</code><code>/xml</code> <code>text</code><code>/javascript</code> <code>application</code><code>/x-httpd-php</code><code>;</code>
<code> </code><code>gzip_vary on;</code>
<code> </code><code>## includes vhosts</code>
<code> </code><code>include vhosts/*.conf;</code>
[root@master-node ~]# mkdir /usr/local/nginx/conf/vhosts
[root@master-node ~]# mkdir /var/www/cache
[root@master-node ~]# ulimit 65535
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
<code>[root@master-node ~]</code><code># vim /usr/local/nginx/conf/vhosts/LB.conf</code>
<code>upstream LB-WWW {</code>
<code> </code><code>ip_hash;</code>
<code> </code><code>server 192.168.1.101:80 max_fails=3 fail_timeout=30s; </code><code>#max_fails = 3 為允許失敗的次數,預設值為1</code>
<code> </code><code>server 192.168.1.102:80 max_fails=3 fail_timeout=30s; </code><code>#fail_timeout = 30s 當max_fails次失敗後,暫停将請求分發到該後端伺服器的時間</code>
<code> </code><code>server 192.168.1.118:80 max_fails=3 fail_timeout=30s;</code>
<code> </code><code>}</code>
<code> </code>
<code>upstream LB-OA {</code>
<code> </code><code>server 192.168.1.101:8080 max_fails=3 fail_timeout=30s;</code>
<code> </code><code>server 192.168.1.102:8080 max_fails=3 fail_timeout=30s;</code>
<code> </code>
<code> </code><code>server {</code>
<code> </code><code>listen 80;</code>
<code> </code><code>server_name dev.wangshibo.com;</code>
<code> </code><code>access_log </code><code>/usr/local/nginx/logs/dev-access</code><code>.log main;</code>
<code> </code><code>error_log </code><code>/usr/local/nginx/logs/dev-error</code><code>.log;</code>
<code> </code><code>location </code><code>/svn</code> <code>{</code>
<code> </code><code>proxy_pass http:</code><code>//192</code><code>.168.1.108</code><code>/svn/</code><code>;</code>
<code> </code><code>proxy_redirect off ;</code>
<code> </code><code>proxy_set_header Host $host;</code>
<code> </code><code>proxy_set_header X-Real-IP $remote_addr;</code>
<code> </code><code>proxy_set_header REMOTE-HOST $remote_addr;</code>
<code> </code><code>proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;</code>
<code> </code><code>proxy_connect_timeout 300; </code><code>#跟後端伺服器連接配接逾時時間,發起握手等候響應時間</code>
<code> </code><code>proxy_send_timeout 300; </code><code>#後端伺服器回傳時間,就是在規定時間内後端伺服器必須傳完所有資料</code>
<code> </code><code>proxy_read_timeout 600; </code><code>#連接配接成功後等待後端伺服器的響應時間,已經進入後端的排隊之中等候處理</code>
<code> </code><code>proxy_buffer_size 256k; </code><code>#代理請求緩沖區,會儲存使用者的頭資訊以供nginx進行處理</code>
<code> </code><code>proxy_buffers 4 256k; </code><code>#同上,告訴nginx儲存單個用幾個buffer最大用多少空間</code>
<code> </code><code>proxy_busy_buffers_size 256k; </code><code>#如果系統很忙時候可以申請最大的proxy_buffers</code>
<code> </code><code>proxy_temp_file_write_size 256k; </code><code>#proxy緩存臨時檔案的大小</code>
<code> </code><code>proxy_next_upstream error timeout invalid_header http_500 http_503 http_404;</code>
<code> </code><code>proxy_max_temp_file_size 128m;</code>
<code> </code><code>proxy_cache mycache; </code>
<code> </code><code>proxy_cache_valid 200 302 60m; </code>
<code> </code><code>proxy_cache_valid 404 1m;</code>
<code> </code><code>}</code>
<code> </code><code>location </code><code>/submin</code> <code>{</code>
<code> </code><code>proxy_pass http:</code><code>//192</code><code>.168.1.108</code><code>/submin/</code><code>;</code>
<code> </code><code>proxy_connect_timeout 300;</code>
<code> </code><code>proxy_send_timeout 300;</code>
<code> </code><code>proxy_read_timeout 600;</code>
<code> </code><code>proxy_buffer_size 256k;</code>
<code> </code><code>proxy_buffers 4 256k;</code>
<code> </code><code>proxy_busy_buffers_size 256k;</code>
<code> </code><code>proxy_temp_file_write_size 256k;</code>
<code> </code><code>proxy_cache mycache; </code>
<code> </code><code>proxy_cache_valid 200 302 60m;</code>
<code> </code><code>}</code>
<code>server {</code>
<code> </code><code>listen 80;</code>
<code> </code><code>server_name www.wangshibo.com;</code>
<code> </code>
<code> </code><code>access_log </code><code>/usr/local/nginx/logs/www-access</code><code>.log main;</code>
<code> </code><code>error_log </code><code>/usr/local/nginx/logs/www-error</code><code>.log;</code>
<code> </code><code>location / {</code>
<code> </code><code>proxy_pass http:</code><code>//LB-WWW</code><code>;</code>
<code> </code>
<code> </code><code>server {</code>
<code> </code><code>listen 80;</code>
<code> </code><code>server_name oa.wangshibo.com;</code>
<code> </code><code>access_log </code><code>/usr/local/nginx/logs/oa-access</code><code>.log main;</code>
<code> </code><code>error_log </code><code>/usr/local/nginx/logs/oa-error</code><code>.log;</code>
<code> </code><code>location / {</code>
<code> </code><code>proxy_pass http:</code><code>//LB-OA</code><code>;</code>
驗證方法(保證從負載均衡器本機到後端真實伺服器之間能正常通信):
1)首先在本機用IP通路上面LB.cong中配置的各個後端真實伺服器的url
2)然後在本機用域名和路徑通路上面LB.cong中配置的各個後端真實伺服器的域名/虛拟路徑
----------------------------------------------------------------------------------------------------------------------------
後端應用伺服器的nginx配置,這裡選擇192.168.1.108作為例子進行說明
由于這裡的192.168.1.108機器是openstack的虛拟機,沒有外網ip,不能解析域名。
是以在server_name處也将ip加上,使得用ip也可以通路。
[root@108-server ~]# cat /usr/local/nginx/conf/vhosts/svn.conf
server {
listen 80;
#server_name dev.wangshibo.com;
server_name dev.wangshibo.com 192.168.1.108;
access_log /usr/local/nginx/logs/dev.wangshibo-access.log main;
error_log /usr/local/nginx/logs/dev.wangshibo-error.log;
location / {
root /var/www/html;
index index.html index.php index.htm;
}
[root@108-server ~]# ll /var/www/html/
drwxr-xr-x. 2 www www 4096 Dec 7 01:46 submin
drwxr-xr-x. 2 www www 4096 Dec 7 01:45 svn
[root@108-server ~]# cat /var/www/html/svn/index.html
this is the page of svn/192.168.1.108
[root@108-server ~]# cat /var/www/html/submin/index.html
this is the page of submin/192.168.1.108
[root@108-server ~]# cat /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.1.108 dev.wangshibo.com
[root@108-server ~]# curl http://dev.wangshibo.com //由于是内網機器不能聯網,亦不能解析域名。是以用域名通路沒有反應。隻能用ip通路
[root@ops-server4 vhosts]# curl http://192.168.1.108
this is 192.168.1.108 page!!!
[root@ops-server4 vhosts]# curl http://192.168.1.108/svn/ //最後一個/符号要加上,否則通路不了。
[root@ops-server4 vhosts]# curl http://192.168.1.108/submin/
然後在master-node和slave-node兩台負載機器上進行測試(iptables防火牆要開通80端口):
[root@master-node ~]# curl http://192.168.1.108/svn/
[root@master-node ~]# curl http://192.168.1.108/submin/
浏覽器通路:
在本機host綁定dev.wangshibo.com,如下,即綁定到master和slave機器的公網ip上測試是否能正常通路(nginx+keepalive環境正式完成後,域名解析到的真正位址是VIP位址)
103.110.98.14 dev.wangshibo.com
103.110.98.24 dev.wangshibo.com
2.keepalived配置
[root@master-node ~]# cp /etc/keepalived/keepalived.conf /etc/keepalived/keepalived.conf.bak
[root@master-node ~]# vim /etc/keepalived/keepalived.conf
<code>! Configuration File </code><code>for</code> <code>keepalived </code><code>#全局定義</code>
<code>global_defs {</code>
<code>notification_email { </code><code>#指定keepalived在發生事件時(比如切換)發送通知郵件的郵箱</code>
<code>[email protected] </code><code>#設定報警郵件位址,可以設定多個,每行一個。 需開啟本機的sendmail服務</code>
<code>[email protected]</code>
<code>notification_email_from [email protected] </code><code>#keepalived在發生諸如切換操作時需要發送email通知位址</code>
<code>smtp_server 127.0.0.1 </code><code>#指定發送email的smtp伺服器</code>
<code>smtp_connect_timeout 30 </code><code>#設定連接配接smtp server的逾時時間</code>
<code>router_id master-node </code><code>#運作keepalived的機器的一個辨別,通常可設為hostname。故障發生時,發郵件時顯示在郵件主題中的資訊。</code>
<code>vrrp_script chk_http_port { </code><code>#檢測nginx服務是否在運作。有很多方式,比如程序,用腳本檢測等等</code>
<code> </code><code>script </code><code>"/opt/chk_nginx.sh"</code> <code>#這裡通過腳本監測</code>
<code> </code><code>interval 2 </code><code>#腳本執行間隔,每2s檢測一次</code>
<code> </code><code>weight -5 </code><code>#腳本結果導緻的優先級變更,檢測失敗(腳本傳回非0)則優先級 -5</code>
<code> </code><code>fall 2 </code><code>#檢測連續2次失敗才算确定是真失敗。會用weight減少優先級(1-255之間)</code>
<code> </code><code>rise 1 </code><code>#檢測1次成功就算成功。但不修改優先級</code>
<code>vrrp_instance VI_1 { </code><code>#keepalived在同一virtual_router_id中priority(0-255)最大的會成為master,也就是接管VIP,當priority最大的主機發生故障後次priority将會接管</code>
<code> </code><code>state MASTER </code><code>#指定keepalived的角色,MASTER表示此主機是主伺服器,BACKUP表示此主機是備用伺服器。注意這裡的state指定instance(Initial)的初始狀态,就是說在配置好後,這台伺服器的初始狀态就是這裡指定的,但這裡指定的不算,還是得要通過競選通過優先級來确定。如果這裡設定為MASTER,但如若他的優先級不及另外一台,那麼這台在發送通告時,會發送自己的優先級,另外一台發現優先級不如自己的高,那麼他會就回搶占為MASTER</code>
<code> </code><code>interface em1 </code><code>#指定HA監測網絡的接口。執行個體綁定的網卡,因為在配置虛拟IP的時候必須是在已有的網卡上添加的</code>
<code> </code><code>mcast_src_ip 103.110.98.14 </code><code># 發送多點傳播資料包時的源IP位址,這裡注意了,這裡實際上就是在哪個位址上發送VRRP通告,這個非常重要,一定要選擇穩定的網卡端口來發送,這裡相當于heartbeat的心跳端口,如果沒有設定那麼就用預設的綁定的網卡的IP,也就是interface指定的IP位址</code>
<code> </code><code>virtual_router_id 51 </code><code>#虛拟路由辨別,這個辨別是一個數字,同一個vrrp執行個體使用唯一的辨別。即同一vrrp_instance下,MASTER和BACKUP必須是一緻的</code>
<code> </code><code>priority 101 </code><code>#定義優先級,數字越大,優先級越高,在同一個vrrp_instance下,MASTER的優先級必須大于BACKUP的優先級</code>
<code> </code><code>advert_int 1 </code><code>#設定MASTER與BACKUP負載均衡器之間同步檢查的時間間隔,機關是秒</code>
<code> </code><code>authentication { </code><code>#設定驗證類型和密碼。主從必須一樣</code>
<code> </code><code>auth_type PASS </code><code>#設定vrrp驗證類型,主要有PASS和AH兩種</code>
<code> </code><code>auth_pass 1111 </code><code>#設定vrrp驗證密碼,在同一個vrrp_instance下,MASTER與BACKUP必須使用相同的密碼才能正常通信</code>
<code> </code><code>virtual_ipaddress { </code><code>#VRRP HA 虛拟位址 如果有多個VIP,繼續換行填寫</code>
<code> </code><code>103.110.98.20</code>
<code>track_script { </code><code>#執行監控的服務。注意這個設定不能緊挨着寫在vrrp_script配置塊的後面(實驗中碰過的坑),否則nginx監控失效!!</code>
<code> </code><code>chk_http_port </code><code>#引用VRRP腳本,即在 vrrp_script 部分指定的名字。定期運作它們來改變優先級,并最終引發主備切換。</code>
2)slave-node負載機上的keepalived配置
[root@slave-node ~]# cp /etc/keepalived/keepalived.conf /etc/keepalived/keepalived.conf.bak
[root@slave-node ~]# vim /etc/keepalived/keepalived.conf
<code>! Configuration File </code><code>for</code> <code>keepalived </code>
<code>notification_email { </code>
<code>[email protected] </code>
<code>notification_email_from [email protected] </code>
<code>smtp_server 127.0.0.1 </code>
<code>smtp_connect_timeout 30 </code>
<code>router_id slave-node </code>
<code>vrrp_script chk_http_port { </code>
<code> </code><code>script </code><code>"/opt/chk_nginx.sh"</code>
<code> </code><code>interval 2 </code>
<code> </code><code>weight -5 </code>
<code> </code><code>fall 2 </code>
<code> </code><code>rise 1 </code>
<code>vrrp_instance VI_1 { </code>
<code> </code><code>state BACKUP </code>
<code> </code><code>interface em1 </code>
<code> </code><code>mcast_src_ip 103.110.98.24 </code>
<code> </code><code>virtual_router_id 51 </code>
<code> </code><code>priority 99 </code>
<code> </code><code>advert_int 1 </code>
<code> </code><code>authentication { </code>
<code> </code><code>auth_type PASS </code>
<code> </code><code>auth_pass 1111 </code>
<code> </code><code>virtual_ipaddress { </code>
<code>track_script { </code>
<code> </code><code>chk_http_port </code>
讓keepalived監控NginX的狀态:
1)經過前面的配置,如果master主伺服器的keepalived停止服務,slave從伺服器會自動接管VIP對外服務;
一旦主伺服器的keepalived恢複,會重新接管VIP。 但這并不是我們需要的,我們需要的是當NginX停止服務的時候能夠自動切換。
2)keepalived支援配置監控腳本,我們可以通過腳本監控NginX的狀态,如果狀态不正常則進行一系列的操作,最終仍不能恢複NginX則殺掉keepalived,使得從伺服器能夠接管服務。
如何監控NginX的狀态
最簡單的做法是監控NginX程序,更靠譜的做法是檢查NginX端口,最靠譜的做法是檢查多個url能否擷取到頁面。
注意:這裡要提示一下keepalived.conf中vrrp_script配置區的script一般有2種寫法:
1)通過腳本執行的傳回結果,改變優先級,keepalived繼續發送通告消息,backup比較優先級再決定。這是直接監控Nginx程序的方式。
2)腳本裡面檢測到異常,直接關閉keepalived程序,backup機器接收不到advertisement會搶占IP。這是檢查NginX端口的方式。
上文script配置部分,"killall -0 nginx"屬于第1種情況,"/opt/chk_nginx.sh" 屬于第2種情況。個人更傾向于通過shell腳本判斷,但有異常時exit 1,正常退出exit 0,然後keepalived根據動态調整的 vrrp_instance 優先級選舉決定是否搶占VIP:
如果腳本執行結果為0,并且weight配置的值大于0,則優先級相應的增加
如果腳本執行結果非0,并且weight配置的值小于0,則優先級相應的減少
其他情況,原本配置的優先級不變,即配置檔案中priority對應的值。
提示:
優先級不會不斷的提高或者降低
可以編寫多個檢測腳本并為每個檢測腳本設定不同的weight(在配置中列出就行)
不管提高優先級還是降低優先級,最終優先級的範圍是在[1,254],不會出現優先級小于等于0或者優先級大于等于255的情況
在MASTER節點的 vrrp_instance 中 配置 nopreempt ,當它異常恢複後,即使它 prio 更高也不會搶占,這樣可以避免正常情況下做無謂的切換
以上可以做到利用腳本檢測業務程序的狀态,并動态調整優先級進而實作主備切換。
另外:在預設的keepalive.conf裡面還有 virtual_server,real_server 這樣的配置,我們這用不到,它是為lvs準備的。
如何嘗試恢複服務
由于keepalived隻檢測本機和他機keepalived是否正常并實作VIP的漂移,而如果本機nginx出現故障不會則不會漂移VIP。
是以編寫腳本來判斷本機nginx是否正常,如果發現NginX不正常,重新開機之。等待3秒再次校驗,仍然失敗則不再嘗試,關閉keepalived,其他主機此時會接管VIP;
根據上述政策很容易寫出監控腳本。此腳本必須在keepalived服務運作的前提下才有效!如果在keepalived服務先關閉的情況下,那麼nginx服務關閉後就不能實作自啟動了。
該腳本檢測ngnix的運作狀态,并在nginx程序不存在時嘗試重新啟動ngnix,如果啟動失敗則停止keepalived,準備讓其它機器接管。
監控腳本如下(master和slave都要有這個監控腳本):
[root@master-node ~]# vim /opt/chk_nginx.sh
<code>#!/bin/bash</code>
<code>counter=$(</code><code>ps</code> <code>-C nginx --no-heading|</code><code>wc</code> <code>-l)</code>
<code>if</code> <code>[ </code><code>"${counter}"</code> <code>= </code><code>"0"</code> <code>]; </code><code>then</code>
<code> </code><code>/usr/local/nginx/sbin/nginx</code>
<code> </code><code>sleep</code> <code>2</code>
<code> </code><code>counter=$(</code><code>ps</code> <code>-C nginx --no-heading|</code><code>wc</code> <code>-l)</code>
<code> </code><code>if</code> <code>[ </code><code>"${counter}"</code> <code>= </code><code>"0"</code> <code>]; </code><code>then</code>
<code> </code><code>/etc/init</code><code>.d</code><code>/keepalived</code> <code>stop</code>
<code> </code><code>fi</code>
<code>fi</code>
[root@master-node ~]# chmod 755 /opt/chk_nginx.sh
[root@master-node ~]# sh /opt/chk_nginx.sh
80/tcp open http
此架構需考慮的問題
1)master沒挂,則master占有vip且nginx運作在master上
2)master挂了,則slave搶占vip且在slave上運作nginx服務
3)如果master上的nginx服務挂了,則nginx會自動重新開機,重新開機失敗後會自動關閉keepalived,這樣vip資源也會轉移到slave上。
4)檢測後端伺服器的健康狀态
5)master和slave兩邊都開啟nginx服務,無論master還是slave,當其中的一個keepalived服務停止後,vip都會漂移到keepalived服務還在的節點上;
如果要想使nginx服務挂了,vip也漂移到另一個節點,則必須用腳本或者在配置檔案裡面用shell指令來控制。(nginx服務宕停後會自動啟動,啟動失敗後會強制關閉keepalived,進而緻使vip資源漂移到另一台機器上)
最後驗證(将配置的後端應用域名都解析到VIP位址上):關閉主伺服器上的keepalived或nginx,vip都會自動飄到從伺服器上。
驗證keepalived服務故障情況:
1)先後在master、slave伺服器上啟動nginx和keepalived,保證這兩個服務都正常開啟:
[root@master-node ~]# /usr/local/nginx/sbin/nginx
[root@master-node ~]# /etc/init.d/keepalived start
[root@slave-node ~]# /usr/local/nginx/sbin/nginx
[root@slave-node ~]# /etc/init.d/keepalived start
2)在主伺服器上檢視是否已經綁定了虛拟IP:
[root@master-node ~]# ip addr
2: em1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP qlen 1000
link/ether 44:a8:42:17:3d:dd brd ff:ff:ff:ff:ff:ff
inet 103.110.98.14/26 brd 103.10.86.63 scope global em1
valid_lft forever preferred_lft forever
inet 103.110.98.20/32 scope global em1
inet 103.110.98.20/26 brd 103.10.86.63 scope global secondary em1:0
inet6 fe80::46a8:42ff:fe17:3ddd/64 scope link
......
3)停止主伺服器上的keepalived:
[root@master-node ~]# /etc/init.d/keepalived stop
Stopping keepalived (via systemctl): [ OK ]
[root@master-node ~]# /etc/init.d/keepalived status
[root@master-node ~]# ps -ef|grep keepalived
root 26952 24348 0 17:49 pts/0 00:00:00 grep --color=auto keepalived
[root@master-node ~]#
4)然後在從伺服器上檢視,發現已經接管了VIP:
[root@slave-node ~]# ip addr
link/ether 44:a8:42:17:3c:a5 brd ff:ff:ff:ff:ff:ff
inet 103.110.98.24/26 brd 103.10.86.63 scope global em1
inet6 fe80::46a8:42ff:fe17:3ca5/64 scope link
發現master的keepalived服務挂了後,vip資源自動漂移到slave上,并且網站正常通路,絲毫沒有受到影響!
5)重新啟動主伺服器上的keepalived,發現主伺服器又重新接管了VIP,此時slave機器上的VIP已經不在了。
Starting keepalived (via systemctl): [ OK ]
[root@master-node ~]# ip addr
接着驗證下nginx服務故障,看看keepalived監控nginx狀态的腳本是否正常?
如下:手動關閉master機器上的nginx服務,最多2秒鐘後就會自動起來(因為keepalive監控nginx狀态的腳本執行間隔時間為2秒)。域名通路幾乎不受影響!
[root@master-node ~]# /usr/local/nginx/sbin/nginx -s stop
[root@master-node ~]# ps -ef|grep nginx
root 28401 24826 0 19:43 pts/1 00:00:00 grep --color=auto nginx
root 28871 28870 0 19:47 ? 00:00:00 /bin/sh /opt/chk_nginx.sh
root 28875 24826 0 19:47 pts/1 00:00:00 grep --color=auto nginx
root 28408 1 0 19:43 ? 00:00:00 nginx: master process /usr/local/nginx/sbin/nginx
www 28410 28408 0 19:43 ? 00:00:00 nginx: worker process
www 28411 28408 0 19:43 ? 00:00:00 nginx: worker process
www 28412 28408 0 19:43 ? 00:00:00 nginx: worker process
www 28413 28408 0 19:43 ? 00:00:00 nginx: worker process
最後可以檢視兩台伺服器上的/var/log/messages,觀察VRRP日志資訊的vip漂移情況~~~~
-------------------------------------------------------------------------------------------------------------------------------------------------
可能出現的問題:
1)VIP綁定失敗
原因可能有:
-> iptables開啟後,沒有開放允許VRRP協定通信的政策(也有可能導緻腦裂);可以選擇關閉iptables
-> keepalived.conf檔案配置有誤導緻,比如interface綁定的裝置錯誤
2)VIP綁定後,外部ping不通
可能的原因是:
-> 網絡故障,可以檢查下網關是否正常;
-> 網關的arp緩存導緻,可以進行arp更新,指令是"arping -I 網卡名 -c 5 -s VIP 網關"
***************當你發現自己的才華撐不起野心時,就請安靜下來學習吧***************
本文轉自散盡浮華部落格園部落格,原文連結:http://www.cnblogs.com/kevingrace/p/6138185.html,如需轉載請自行聯系原作者