HBase – Hadoop Database,是一個高可靠性、高性能、面向列、可伸縮的分布式存儲系統,利用HBase技術可在廉價PC Server上搭建起大規模結構化存儲叢集。
HBase是Google Bigtable的開源實作,類似Google Bigtable利用GFS作為其檔案存儲系統,HBase利用Hadoop HDFS作為其檔案存儲系統;Google運作MapReduce來處理Bigtable中的海量資料,HBase同樣利用Hadoop MapReduce來處理HBase中的海量資料;Google Bigtable利用 Chubby作為協同服務,HBase利用Zookeeper作為對應。
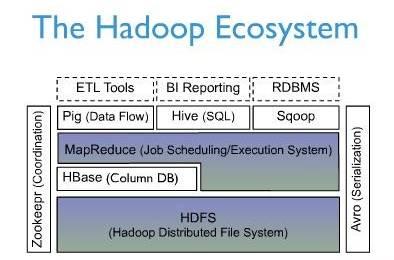
上圖描述了Hadoop EcoSystem中的各層系統,其中HBase位于結構化存儲層,Hadoop HDFS為HBase提供了高可靠性的底層存儲支援,Hadoop MapReduce為HBase提供了高性能的計算能力,Zookeeper為HBase提供了穩定服務和failover機制。
此外,Pig和Hive還為HBase提供了高層語言支援,使得在HBase上進行資料統計處理變的非常簡單。 Sqoop則為HBase提供了友善的RDBMS資料導入功能,使得傳統資料庫資料向HBase中遷移變的非常友善。
1. Native Java API,最正常和高效的通路方式,适合Hadoop MapReduce Job并行批處理HBase表資料
2. HBase Shell,HBase的指令行工具,最簡單的接口,适合HBase管理使用
3. Thrift Gateway,利用Thrift序列化技術,支援C++,PHP,Python等多種語言,适合其他異構系統線上通路HBase表資料
4. REST Gateway,支援REST 風格的Http API通路HBase, 解除了語言限制
5. Pig,可以使用Pig Latin流式程式設計語言來操作HBase中的資料,和Hive類似,本質最終也是編譯成MapReduce Job來處理HBase表資料,适合做資料統計
6. Hive,目前Hive的Release版本尚沒有加入對HBase的支援,但在下一個版本Hive 0.7.0中将會支援HBase,可以使用類似SQL語言來通路HBase
Row Key
Timestamp
Column Family
URI
Parser
r1
t3
url=http://www.taobao.com
title=天天特價
t2
host=taobao.com
t1
r2
t5
url=http://www.alibaba.com
content=每天…
t4
host=alibaba.com
Ø Row Key: 行鍵,Table的主鍵,Table中的記錄按照Row Key排序
Ø Timestamp: 時間戳,每次資料操作對應的時間戳,可以看作是資料的version number
Ø Column Family:列簇,Table在水準方向有一個或者多個Column Family組成,一個Column Family中可以由任意多個Column組成,即Column Family支援動态擴充,無需預先定義Column的數量以及類型,所有Column均以二進制格式存儲,使用者需要自行進行類型轉換。
當Table随着記錄數不斷增加而變大後,會逐漸分裂成多份splits,成為regions,一個region由[startkey,endkey)表示,不同的region會被Master配置設定給相應的RegionServer進行管理:

HBase中有兩張特殊的Table,-ROOT-和.META.
Ø .META.:記錄了使用者表的Region資訊,.META.可以有多個regoin
Ø -ROOT-:記錄了.META.表的Region資訊,-ROOT-隻有一個region
Ø Zookeeper中記錄了-ROOT-表的location
Client通路使用者資料之前需要首先通路zookeeper,然後通路-ROOT-表,接着通路.META.表,最後才能找到使用者資料的位置去通路,中間需要多次網絡操作,不過client端會做cache緩存。
在HBase系統上運作批處理運算,最友善和實用的模型依然是MapReduce,如下圖:
HBase Table和Region的關系,比較類似HDFS File和Block的關系,HBase提供了配套的TableInputFormat和TableOutputFormat API,可以友善的将HBase Table作為Hadoop MapReduce的Source和Sink,對于MapReduce Job應用開發人員來說,基本不需要關注HBase系統自身的細節。
HBase Client使用HBase的RPC機制與HMaster和HRegionServer進行通信,對于管理類操作,Client與HMaster進行RPC;對于資料讀寫類操作,Client與HRegionServer進行RPC
Zookeeper Quorum中除了存儲了-ROOT-表的位址和HMaster的位址,HRegionServer也會把自己以Ephemeral方式注冊到 Zookeeper中,使得HMaster可以随時感覺到各個HRegionServer的健康狀态。此外,Zookeeper也避免了HMaster的 單點問題,見下文描述
HMaster沒有單點問題,HBase中可以啟動多個HMaster,通過Zookeeper的Master Election機制保證總有一個Master運作,HMaster在功能上主要負責Table和Region的管理工作:
1. 管理使用者對Table的增、删、改、查操作
2. 管理HRegionServer的負載均衡,調整Region分布
3. 在Region Split後,負責新Region的配置設定
4. 在HRegionServer停機後,負責失效HRegionServer 上的Regions遷移
HRegionServer主要負責響應使用者I/O請求,向HDFS檔案系統中讀寫資料,是HBase中最核心的子產品。
HRegionServer内部管理了一系列HRegion對象,每個HRegion對應了Table中的一個Region,HRegion中由多 個HStore組成。每個HStore對應了Table中的一個Column Family的存儲,可以看出每個Column Family其實就是一個集中的存儲單元,是以最好将具備共同IO特性的column放在一個Column Family中,這樣最高效。
HStore存儲是HBase存儲的核心了,其中由兩部分組成,一部分是MemStore,一部分是StoreFiles。MemStore是 Sorted Memory Buffer,使用者寫入的資料首先會放入MemStore,當MemStore滿了以後會Flush成一個StoreFile(底層實作是HFile), 當StoreFile檔案數量增長到一定門檻值,會觸發Compact合并操作,将多個StoreFiles合并成一個StoreFile,合并過程中會進 行版本合并和資料删除,是以可以看出HBase其實隻有增加資料,所有的更新和删除操作都是在後續的compact過程中進行的,這使得使用者的寫操作隻要 進入記憶體中就可以立即傳回,保證了HBase I/O的高性能。當StoreFiles Compact後,會逐漸形成越來越大的StoreFile,當單個StoreFile大小超過一定門檻值後,會觸發Split操作,同時把目前 Region Split成2個Region,父Region會下線,新Split出的2個孩子Region會被HMaster配置設定到相應的HRegionServer 上,使得原先1個Region的壓力得以分流到2個Region上。下圖描述了Compaction和Split的過程:
在了解了上述HStore的基本原理後,還必須了解一下HLog的功能,因為上述的HStore在系統正常工作的前提下是沒有問題的,但是在分布式 系統環境中,無法避免系統出錯或者當機,是以一旦HRegionServer意外退出,MemStore中的記憶體資料将會丢失,這就需要引入HLog了。 每個HRegionServer中都有一個HLog對象,HLog是一個實作Write Ahead Log的類,在每次使用者操作寫入MemStore的同時,也會寫一份資料到HLog檔案中(HLog檔案格式見後續),HLog檔案定期會滾動出新的,并 删除舊的檔案(已持久化到StoreFile中的資料)。當HRegionServer意外終止後,HMaster會通過Zookeeper感覺 到,HMaster首先會處理遺留的 HLog檔案,将其中不同Region的Log資料進行拆分,分别放到相應region的目錄下,然後再将失效的region重新配置設定,領取 到這些region的HRegionServer在Load Region的過程中,會發現有曆史HLog需要處理,是以會Replay HLog中的資料到MemStore中,然後flush到StoreFiles,完成資料恢複。
HBase中的所有資料檔案都存儲在Hadoop HDFS檔案系統上,主要包括上述提出的兩種檔案類型:
1. HFile, HBase中KeyValue資料的存儲格式,HFile是Hadoop的二進制格式檔案,實際上StoreFile就是對HFile做了輕量級包裝,即StoreFile底層就是HFile
2. HLog File,HBase中WAL(Write Ahead Log) 的存儲格式,實體上是Hadoop的Sequence File
下圖是HFile的存儲格式:
首先HFile檔案是不定長的,長度固定的隻有其中的兩塊:Trailer和FileInfo。正如圖中所示的,Trailer中有指針指向其他數 據塊的起始點。File Info中記錄了檔案的一些Meta資訊,例如:AVG_KEY_LEN, AVG_VALUE_LEN, LAST_KEY, COMPARATOR, MAX_SEQ_ID_KEY等。Data Index和Meta Index塊記錄了每個Data塊和Meta塊的起始點。
Data Block是HBase I/O的基本單元,為了提高效率,HRegionServer中有基于LRU的Block Cache機制。每個Data塊的大小可以在建立一個Table的時候通過參數指定,大号的Block有利于順序Scan,小号Block利于随機查詢。 每個Data塊除了開頭的Magic以外就是一個個KeyValue對拼接而成, Magic内容就是一些随機數字,目的是防止資料損壞。後面會詳細介紹每個KeyValue對的内部構造。
HFile裡面的每個KeyValue對就是一個簡單的byte數組。但是這個byte數組裡面包含了很多項,并且有固定的結構。我們來看看裡面的具體結構:
開始是兩個固定長度的數值,分别表示Key的長度和Value的長度。緊接着是Key,開始是固定長度的數值,表示RowKey的長度,緊接着是 RowKey,然後是固定長度的數值,表示Family的長度,然後是Family,接着是Qualifier,然後是兩個固定長度的數值,表示Time Stamp和Key Type(Put/Delete)。Value部分沒有這麼複雜的結構,就是純粹的二進制資料了。
上圖中示意了HLog檔案的結構,其實HLog檔案就是一個普通的Hadoop Sequence File,Sequence File 的Key是HLogKey對象,HLogKey中記錄了寫入資料的歸屬資訊,除了table和region名字外,同時還包括 sequence number和timestamp,timestamp是“寫入時間”,sequence number的起始值為0,或者是最近一次存入檔案系統中sequence number。
HLog Sequece File的Value是HBase的KeyValue對象,即對應HFile中的KeyValue,可參見上文描述。
本文對HBase技術在功能和設計上進行了大緻的介紹,由于篇幅有限,本文沒有過多深入地描述HBase的一些細節技術。目前一淘的存儲系統就是基于HBase技術搭建的,後續将介紹“一淘分布式存儲系統”,通過實際案例來更多的介紹HBase應用。
本文轉自二郎三郎部落格園部落格,原文連結:http://www.cnblogs.com/haore147/p/5103090.html,如需轉載請自行聯系原作者