概述
這是使用機器學習預測平均氣溫系列文章的最後一篇文章了,作為最後一篇文章,我将使用google的開源機器學習架構tensorflow來建構一個神經網絡回歸器。關于tensorflow的介紹、安裝、入門,請自己google,這裡就不做講述。
這篇文章我主要講解一下幾點:
了解人工神經網絡理論
tensorflow進階API:Estimators
建構DNN模型預測天氣
人工神經網絡基礎理論
上一篇文章主要講解了如何建構線性回歸模型(這是最基礎的機器學習算法)來預測内布拉斯加州林肯市每天的平均氣溫。線性回歸模型非常有效,并且可以被用于數值化(比如分類)、預測(比如預測天氣)。線性回歸算法也比較與局限性,它要求資料之間具有線性關系。 針對于非線性關系的場景,資料挖掘和機器學習有數不清的算法來處理。近些年最火的要數神經網絡算法了,它可以處理機器學習領域的好多問題。神經網絡算法具備線性和非線性學習算法的能力。 神經網絡受到大腦中的生物神經元的啟發,它們在複雜的互動網絡中工作,根據已經收集的資訊的曆史來傳輸,收集和學習資訊。我們感興趣的計算神經網絡類似于大腦的神經元,因為它們是接收輸入信号(數字量)的神經元(節點)的集合,處理輸入并将處理後的信号發送給其他下遊代理 網絡。 信号作為通過神經網絡的數字量的處理是一個非常強大的特征,不限于線性關系。 在這個系列中,我一直關注一種稱為監督學習的特定類型的機器學習,也就說說訓練的資料結果是已知的,根據曆史已知的輸入和輸出,預測未來的輸入對應的輸出。 此外,預測的類型是數值的真實值,這意味着我們使用的是回歸預測算法。 從圖形上看,類似于本文中描述的神經網絡如圖:
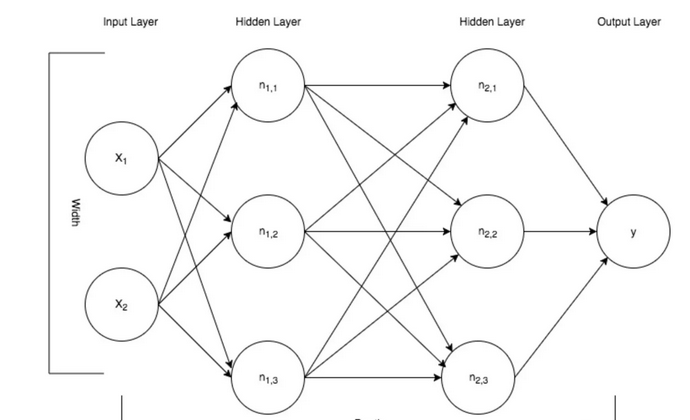
上面描述的神經網絡在最左邊包含一個輸入層,即圖中的x1和x2,這兩個特征是神經網絡輸入值。這兩個特征被輸入到神經網絡中,通過被稱為隐藏層的兩層神經元進行處理和傳輸。這個描述顯示了兩個隐藏層,每層包含三個神經元(節點)。 該信号然後離開神經網絡,并作為單個數值預測值彙總在輸出層。 讓我花一點時間來解釋箭頭背後的含義,箭頭表示資料在層間從一個節點到另一個節點的傳輸處理。 每個箭頭代表一個數值的數學變換,從箭頭的底部開始,然後乘以特定于該路徑特定的權重。 一個圖層中的每個節點将以這種方式得到一個值。 然後彙總所有在節點收斂的值。 這個就是我之前提到的神經網絡的線性操作。

在每個節點上進行求和之後,将一個特殊的非線性函數應用到總和上,這在上面的圖像中被描述為Fn(...)。 這種将非線性特征引入神經網絡的特殊功能稱為激活功能。 激活函數所帶來的這種非線性特性賦予了多層神經網絡以其功能。 如果不是将非線性加入到過程中,則所有層都将有效地代數地組合成一個常數運算,其中包括将輸入乘以某個平坦系數值(即線性模型)。 好吧,這一切都很好,但是這怎麼轉化為學習算法呢? 那麼最直接的答案就是評估正在進行的預測,即模型“y”的輸出,到實際預期值(目标),并對權重進行一系列調整,以改善整體 預測準确性。 在回歸機器學習算法的世界中,通過使用成本(又名“損失”或“客觀”)函數(即平方誤差之和(SSE))評估準确性。 請注意,我把這個聲明推廣到整個機器學習的連續體,而不僅僅是神經網絡。 在前面的文章中,普通最小二乘算法完成了這一工作,它發現了使誤差平方和(即最小二乘)最小化的系數組合。 我們的神經網絡回歸器會做同樣的事情。 它将疊代訓練資料提取特征值,計算成本函數(使用SSE),并以最小化成本函數的方式調整權重。 通過算法疊代推送特征的過程和評估如何根據成本函數來調整權重。 模型優化算法在建構魯棒神經網絡中非常重要。 例如通過網絡體系結構(即寬度和深度)饋送,然後根據成本函數進行評估,調整權重。 當優化器函數确定權重調整不會導緻成本函數計算代價的變化,該模型被認為是“學習”。
TensorFlow Estimator API
tensorflow由好幾個部分組成,其中最常用的是Core API,它為使用者提供了一套低級别的API來定義和訓練使用符号操作的任何機器學習算法。這也是TensorFlow的核心功能,雖然Core API能應對大多數的應用場景,但我更關注Estimator API。 TensorFlow團隊開發了Estimator API,使日常開發人員可以更友善地使用該庫。這個API提供了訓練模型、評估模型、以及和Sci-Kit庫相似的對未知資料的預測接口,這是通過實作各種算法的通用接口來實作的。另外,建構在進階API中的是機器學習最佳實踐,抽象和可伸縮性的負載。 所有這些機器學習的優點使得基礎Estimator類中實作的一套工具以及多個預先封裝的模型類型,降低了使用TensorFlow的入門門檻,是以可以應用于日常問題。通過抽象出諸如編寫訓練循環或處理會話之類的問題,開發人員能夠專注于更重要的事情,如快速嘗試多個模型和模型架構,以找到最适合他們需要的模型。 在這篇文章中,我将介紹如何使用非常強大的深度神經網絡估計器之一DNN Regressor。
建立一個DNNRegressor來預測天氣
我們先導入一些我們需要用到的庫。
我們來處理一下資料,所有的資料我都放在了Github上,大家可以去查閱clone。
請注意,我們剛剛記錄下了1000個氣象資料記錄,并且所有的特征都是數字性質的。 另外,由于我們在第一篇文章中的努力工作,所有記錄都是完整的,因為它們不缺少任何值(沒有非空值)。 現在我将删除“mintempm”和“maxtempm”這兩列,因為它們對幫助我們預測平均溫度毫無意義。 我們正在試圖預測未來,是以我們顯然不能掌握有關未來的資料。 我還将從目标(y)中分離出特征(X)。
和所有監督機器學習應用程式一樣,我将把我的資料集分成訓練集和測試集。 但是,為了更好地解釋訓練這個神經網絡的疊代過程,我将使用一個額外的資料集,我将其稱為“驗證集合”。 對于訓練集,我将利用80%的資料,對于測試和驗證集,它們将分别為剩餘資料的10%。為了分解這些資料,我将再次使用Scikit Learn 庫的train_test_split()函數。
建構神經網絡模型時要采取的第一步是執行個體化tf.estimator.DNNRegressor()類。類的構造函數有多個參數,但我将重點關注以下參數:
feature_columns:一種類似清單的結構,包含要輸入到模型中的要素的名稱和資料類型的定義
hidden_units:一個類似清單的結構,包含神經網絡數量寬度和深度的定義
optimizer:tf.Optimizer子類的一個執行個體,在訓練期間優化模型的權重;它的預設值是AdaGrad優化器。
activation_fn:激活功能,用于在每一層向網絡引入非線性;預設是ReLU
model_dir:要建立的目錄,其中包含模型的中繼資料和其他檢查點儲存 我将首先定義一個數字特征列的清單。要做到這一點,我使用tf.feature_column.numeric_column()函數傳回一個FeatureColumn執行個體。
使用定義的特性列,我現在可以執行個體化DNNRegressor類并将其存儲在回歸變量中。 我指定我想要一個有兩層深度的神經網絡,其中兩層的寬度都是50個節點。 我還指出,我希望我的模型資料存儲在一個名為tf_wx_model的目錄中。
接下來我想要做的是定義一個可重用的函數,這個函數通常被稱為“輸入函數”,我将調用wx_input_fn()。 這個函數将被用來在訓練和測試階段将資料輸入到我的神經網絡中。有許多不同的方法來建立輸入函數,但我将描述如何定義和使用一個基于tf.estimator.inputs.pandas_input_fn(),因為我的資料是在一個pandas資料結構。
請注意,這個wx_input_fn()函數接受一個必選參數和四個可選參數,然後将這些參數交給TensorFlow輸入函數,專門用于傳回的pandas資料。 這是TensorFlow API一個非常強大的功能。函數的參數定義如下:
X:輸入要輸入到三種DNNRegressor接口方法中的一種(訓練,評估和預測)
y:X的目标值,這是可選的,不會被提供給預測調用
num_epochs:可選參數。 當算法在整個資料集上執行一次時,就會出現一個新紀元。
shuffle:可選參數,指定每次執行算法時是否随機選擇資料集的批處理(子集)
batch_size:每次執行算法時要包含的樣本數
通過定義我們的輸入函數,我們現在可以訓練我們基于訓練資料集上的神經網絡。 對于熟悉TensorFlow進階API的讀者,您可能會注意到我對自己的模型的教育訓練方式有點不合正常。至少從TensorFlow網站上的目前教程和網絡上的其他教程的角度來看。通常情況下,您将看到如下所示的内容。
然後,作者将直接展示evaluate()函數,并且幾乎沒有提示它在做什麼或為什麼存在這一行代碼。
在此之後,假設所有的訓練模型都是完美的,他們會直接跳到執行predict()函數。
我希望能夠提供一個合理的解釋,說明如何訓練和評估這個神經網絡,以便将這個模型拟合或過度拟合到訓練資料上的風險降到最低。是以,我們不再拖延,讓我定義一個簡單的訓練循環,對訓練資料進行訓練,定期對評估資料進行評估。
上面的循環疊代了100次。 在循環體中,我調用了回歸器對象的train()方法,并将其傳遞給了我的可重用的wx_input_fn(),後者又通過了我的訓練功能集和目标。 我有意地将預設參數num_epochs等于None,基本上這樣說:“我不在乎你通過訓練集多少次,隻是繼續訓練算法對每個預設batch_size 400”(大約一半的訓練 組)。 我還将shuffle參數設定為預設值True,以便在訓練時随機選擇資料以避免資料中的任何順序關系。 train()方法的最後一個參數是我設定為400的步驟,這意味着訓練集每個循環将被批處理400次。 這給了我一個很好的時間以更具體的數字來解釋一個epoch的意義。 回想一下,當一個訓練集的所有記錄都通過神經網絡訓練一次時,就會出現一個epoch。 是以,如果我們的訓練集中有大約800(準确的說是797)個記錄,并且每個批次選擇400個,那麼每兩個批次我們就完成了一個時間。 是以,如果我們周遊整個訓練集100個疊代400個步驟,每個批次大小為400(每個批次的一個半個時間),我們得到:
現在你可能想知道為什麼我為循環的每次疊代執行和evaluate()方法,并在清單中捕獲它的輸出。 首先讓我解釋一下每次train()方法被觸發時會發生什麼。它随機選擇一批訓練記錄,并通過網絡推送,直到做出預測,并為每條記錄計算損失函數。 然後根據計算出的損失根據優化器的邏輯調整權重,這對于減少下一次疊代的整體損失的方向做了很好的調整。 一般而言,隻要學習速率足夠小,這些損失值随着時間的推移而逐漸下降。 然而,經過一定數量的這些學習疊代之後,權重開始不僅受到資料整體趨勢的影響,而且還受到非實際的噪聲在所有實際資料中的繼承。 在這一點上,網絡受到訓練資料特性的過度影響,并且變得無法推廣關于總體資料的預測。這與我之前提到的進階TensorFlow API許多其他教程不足之處有關。 在訓練期間周期性地打破這一點非常重要,并評估模型如何推廣到評估或驗證資料集。 通過檢視第一個循環疊代的評估輸出,讓我們花些時間看看evaluate()函數傳回的結果。
正如你所看到的,它輸出的是平均損失(均方誤差)和訓練中的步驟的總損失(平方誤差和),這一步是第400步。 在訓練有素的網絡中,你通常會看到一種趨勢,即訓練和評估損失或多或少地平行下降。 然而,在某個時間點的過度配置模型中,實際上在過拟合開始出現的地方,驗證訓練集将不再看到其evaluate()方法的輸出降低。 這是你想停止進一步訓練模型的地方,最好是在變化發生之前。 現在我們對每個疊代都有一個評估集合,讓我們将它們作為訓練步驟的函數來繪制,以確定我們沒有過度訓練我們的模型。 為此,我将使用matplotlib的pyplot子產品中的一個簡單的散點圖。
從上面的圖表看來,在所有這些疊代之後,我并沒有過度配置模型,因為評估損失從來沒有呈現出朝着增加價值的方向的顯着變化。現在,我可以安全地繼續根據我的剩餘測試資料集進行預測,并評估模型如何預測平均天氣溫度。 與我已經示範的其他兩種回歸方法類似,predict()方法需要input_fn,我将使用可重用的wx_input_fn()傳遞input_fn,将測試資料集交給它,将num_epochs指定為None,shuffle為False,是以它将依次送入所有的資料進行測試。 接下來,我做一些從predict()方法傳回的dicts疊代的格式,以便我有一個numpy的預測數組。然後,我使用sklearn方法explain_variance_score(),mean_absolute_error()和median_absolute_error()來預測數組,以測量預測與已知目标y_test的關系。
我已經使用了與上一篇文章有關的線性回歸技術相同的名額,以便我們不僅可以評估這個模型,還可以對它們進行比較。 正如你所看到的,這兩個模型的表現相當類似,更簡單的線性回歸模型略好一些。然而,你可以通過修改學習速率,寬度和深度等參數來優化機器學習模型。
總結
本文示範了如何使用TensorFlow進階API Estimator子類DNNRegressor。并且,我也描述了神經網絡理論,他們是如何被訓練的,以及在過程中認識到過度拟合模型的危險性的重要性。 為了示範這個建立神經網絡的過程,我建立了一個模型,能夠根據本系列第一篇文章收集的數字特征預測第二天的平均溫度。寫這些文章的目的不是為了建立一個非常好的模型預測天氣,我的目标是:
示範從資料收集,資料處理,探索性資料分析,模型選擇,模型建構和模型評估中進行分析(機器學習,資料科學,無論...)項目的一般過程。
示範如何使用兩個流行的Python庫StatsModels和Scikit Learn來選擇不違反線性回歸技術關鍵假設的有意義的功能。
示範如何使用進階别的TensorFlow API,并直覺地了解所有這些抽象層下正在發生的事情。
讨論與過度拟合模型相關的問題。
解釋試驗多個模型類型以最好地解決問題。
延伸推薦
點選關鍵詞閱讀更多新書:
Python|機器學習|Kotlin|Java|移動開發|機器人|有獎活動|Web前端|書單
在“異步圖書”背景回複“關注”,即可免費獲得2000門線上視訊課程;推薦朋友關注根據提示擷取贈書連結,免費得異步圖書一本。趕緊來參加哦!
點選閱讀原文,檢視本書更多資訊
掃一掃上方二維碼,回複“關注”參與活動!
本文摘自異步社群,點選下方閱讀原文檢視詳情