2014年,深度學習三巨頭之一IanGoodfellow提出了生成對抗網絡(Generative Adversarial Networks, GANs)這一概念,剛開始并沒有引起轟動,直到2016年,學界、業界對它的興趣如“井噴”一樣爆發,多篇重磅文章陸續發表。2016年12月NIPS大會上,Goodfellow做了關于GANs的專題報告,使得GANs成為了當今最熱門的研究領域之一,本文将介紹如今深度學習界的明星——生成對抗網絡。
生成對抗網絡,根據它的名字,可以推斷這個網絡由兩部分組成:第一部分是生成,第二部分是對抗。這個網絡的第一部分是生成模型,就像之前介紹的自動編碼器的解碼部分;第二部分是對抗模型,嚴格來說它是一個判斷真假圖檔的判别器。生成對抗網絡最大的創新在此,這也是生成對抗網絡與自動編碼器最大的差別。簡單來說,生成對抗網絡就是讓兩個網絡互相競争,通過生成網絡來生成假的資料,對抗網絡通過判别器判别真僞,最後希望生成網絡生成的資料能夠以假亂真騙過判别器。過程如圖1所示。
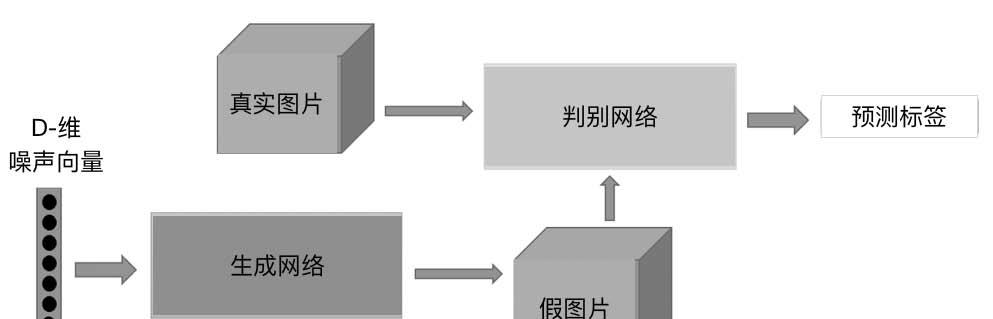
圖1 生成對抗網絡生成資料過程
下面依次介紹生成模型和對抗模型。
首先看看生成模型,前一節自動編碼器其實已經給出了一般的生成模型。
在生成對抗網絡中,不再是将圖檔輸入編碼器得到隐含向量然後生成圖檔,而是随機初始化一個隐含向量,根據變分自動編碼器的特點,初始化一個正态分布的隐含向量,通過類似解碼的過程,将它映射到一個更高的次元,最後生成一個與輸入資料相似的資料,這就是假的圖檔。這時自動編碼器是通過對比兩張圖檔之間每個像素點的差異計算損失函數的,而生成對抗網絡會通過對抗過程來計算出這個損失函數,如圖2所示。

圖2 生成模型
重點來介紹對抗過程,這個過程是生成對抗網絡相對于之前的生成模型如自動編碼器等最大的創新。
對抗過程簡單來說就是一個判斷真假的判别器,相當于一個二分類問題,輸入一張真的圖檔希望判别器輸出的結果是1,輸入一張假的圖檔希望判别器輸出的結果是0。
這跟原圖檔的label 沒有關系,不管原圖檔到底是一個多少類别的圖檔,它們都統一稱為真的圖檔,輸出的label 是1,則表示是真實的;而生成圖檔的label 是0,則表示是假的。
在訓練的時候,先訓練判别器,将假的資料和真的資料都輸入給判别模型,這個時候優化這個判别模型,希望它能夠正确地判斷出真的資料和假的資料,這樣就能夠得到一個比較好的判别器。
然後開始訓練生成器,希望它生成的假的資料能夠騙過現在這個比較好的判别器。
具體做法就是将判别器的參數固定,通過反向傳播優化生成器的參數,希望生成器得到的資料在經過判别器之後得到的結果能盡可能地接近1,這時隻需要調整一下損失函數就可以了,之前在優化判别器的時候損失函數是讓假的資料盡可能接近0,而現在訓練生成器的損失函數是讓假的資料盡可能接近1。
這其實就是一個簡單的二分類問題,這個問題可以用前面介紹過的很多方法去處理,比如Logistic 回歸、多層感覺器、卷積神經網絡、循環神經網絡等。
上面是生成對抗網絡的簡單解釋,可以通過代碼更清晰地展示整個過程。
跟自動編碼器一樣,先使用簡單的多層感覺器來實作:
上面是判别器的結構,中間使用了斜率設為0.2 的LeakyReLU 激活函數,最後需要使用nn.Sigmoid() 将結果映射到0 s 1 之間機率進行真假的二分類。這裡之是以用LeakyReLU 激活函數而不使用ReLU 激活函數,是因為經過實驗,LeakyReLU 的表現更好。
這就是生成器的結構,跟自動編碼器中的解碼器是類似的,最後需要使用nn.Tanh(),将資料分布到-1 ~1 之間,這是因為輸入的圖檔會規範化到-1 ~1之間。
接着需要定義損失函數和優化函數:
這裡使用二分類的損失函數nn.BCELoss(),使用Adam 優化函數,學習率設定為0.0003。
接着是最為重要的訓練過程,這個過程分為兩個部分:一個是判别器的訓練,一個是生成器的訓練。
首先來看看判别器的訓練。
開始需要自己建立label,真實的資料是1,生成的假的資料是0,然後将真實的資料輸入判别器得到loss,将假的資料輸入判别器得到loss,将這兩個loss 加起來得到總的loss,然後反向傳播去更新參數就能夠得到一個優化好的判别器。
接下來是生成模型的訓練:
一個随機隐含向量通過生成網絡得到了一個假的資料,然後希望假的資料經過判别模型後盡可能和真實label 接近,通過g_loss = criterion(output, real_label)實作,然後反向傳播去優化生成器的參數,在這個過程中,判别器的參數不再發生變化,否則生成器永遠無法騙過優化的判别器。
除了使用簡單的多層感覺器外,也可以在生成模型和對抗模型中使用更加複雜的卷積神經網絡,定義十分簡單。
圖3 左邊是多層感覺器的生成對抗網絡,右邊是卷積生成對抗網絡,右邊的圖檔比左邊的圖檔噪聲明顯更少。在卷積神經網絡裡引入了批标準化(Batchnormalization)來穩定訓練,同時使用了LeakyReLU 和平均池化來進行訓練。生成對抗網絡的訓練其實是很困難的,因為這是兩個對偶網絡在互相學習,是以需要增加一些訓練技巧才能使訓練更加穩定。
圖3生成對抗網絡對比結果
以上介紹了生成對抗網絡的簡單原理和訓練流程,但是對生成對抗網絡而言,它其實并沒有真正地學習到它要表示的物體,通過對抗的過程,它隻是生成了一張盡可能真的圖檔,這就意味着沒辦法決定用哪種噪聲能夠生成想要的圖檔,除非把初始分布都試一遍。是以在生成對抗網絡提出之後,有很多基于标準生成對抗網絡的變式來解決各種各樣的問題。
這一節将介紹改善的生成對抗網絡,因為生成對抗網絡存在很多問題,是以人們研究能否通過改善網絡結構或者損害函數來解決這些問題。
Wasserstein GAN 是GAN 的一種變式,我們知道GAN 的訓練是非常麻煩的,需要很多訓練技巧,而且在不同的資料集上,由于資料的分布會發生變化,也需要重新調整參數,不僅需要小心地平衡生成器和判别器的訓練程序,同時生成的樣本還缺乏多樣性。除此之外最大的問題是沒辦法衡量這個生成器到底好不好,因為沒辦法通過判别器的loss 去判斷這個事情。雖然DC GAN 依靠對生成器和判别器的結構進行枚舉,最終找到了一個比較好的網絡設定,但還是沒有從根本上解決訓練的問題。
WGAN 的出現,徹底解決了下面這些難點:
(1)徹底解決了訓練不穩定的問題,不再需要設計參數去平衡判别器和生成器;
(2)基本解決了collapse mode 的問題,確定了生成樣本的多樣性;
(3)訓練中有一個向交叉熵、準确率的數值名額來衡量訓練的程序,數值越小代表GAN 訓練得越好,同時也就代表着生成的圖檔品質越高;
(4)不需要精心設計網絡結構,用簡單的多層感覺器就能夠取得比較好的效果。
下面先介紹為什麼GAN 會有這些缺點,然後解釋WGAN是通過什麼辦法解決這些問題的。
根據之前介紹的,有下面的式子(1):
從式(1)我們知道原始的GAN 是通過最優判别器下的JS Divergence 來衡量兩種分布之間的差異的,而且最優判别器下JS Divergence 越小,就說明兩種分布越接近,但是JS Divergence 有一個嚴重的問題,那就是如果兩種分布完全沒有重疊部分,或者說重疊部分可忽略,那麼JS Divergence 将恒等于常數log2。換句話說,就算兩種分布很接近,但是隻要它們沒有重疊,那麼JS Divergence 就是一個常數,這就使得網絡沒辦法通過這個損失函數去學習,因為它沒辦法知道它是否做得好,這就會導緻梯度消失,同時這也使得我們沒有辦法衡量這兩種分布到底有多靠近。
而真實分布與生成的分布沒有重疊部分的機率有多大呢?其實是非常大的,直覺來講,真實分布是一個高維分布,而生成的分布來自于一個低維分布,是以其實很有可能生成分布和真實分布之間就沒有重疊的部分。除此之外,不可能真正去計算兩個分布,隻能近似取樣,是以也導緻了兩種分布沒有重疊部分。如果判别器訓練得太好,那麼生成的分布和原來分布基本沒有重疊部分,這就導緻了梯度消失;如果判别器訓練得不好,這樣生成器的梯度又不準,就會出現錯誤的優化方向。如果要使得GAN 能夠完美地收斂,那麼需要判别器的訓練不好也不壞,而這個度是很難把握的,況且這還依賴資料的分布等條件,是以GAN 才這麼難訓練。
既然GAN 存在的問題都是由于JS Divergence 引起的,那麼能不能換一種度量方式去衡量兩種分布之間的差異,而不使用JS Divergence?答案是肯定的,這就是WGAN中提出的解決辦法。
首先介紹一種新的度量方式去度量兩種分布之間的差異——Wasserstein 距離,也稱為Earth Mover 距離,定義如下:
看上去可能比較複雜,數學解釋如下:對于兩種分布Pr 和Pg,它們的聯合分布是II(Pr,Pg),換句話說II(Pr,Pg) 中每一個聯合分布的邊緣分布就是Pr 或者Pg。那麼對每一個聯合分布而言,從裡面取樣x 和y,并計算x 和y 的距離,然後取遍所有的x 和y 計算一下期望,接着取這些期望裡面最小的作為W 距離的定義。
如果上面的解釋不夠清楚,也可以通俗地解釋,因為它還有一個别名叫Earth mover距離,也就是推土機距離,這是什麼意思呢?可以把兩種分布想象成兩堆土,然後想想如何用推土機将一種分布變成另外一種分布的樣子,會有很多種移動方案,裡面最小消耗的那種方案就是最優的方案,也就是這個距離的定義。
W 距離與JS Divergence 相比有什麼好處呢?最大的好處就是不管兩種分布是否有重疊,它都是連續變換的而不是突變的,可以用下面這個例子來說明一下,如圖4所示。
圖4 W 距離例子
通過上面這個示範可以發現,雖然兩種分布更接近,但JS Divergence 仍然是log2,W 距離就能夠連續而有效地衡量兩種分布之間的差異。
W 距離有很好的優越性,把它拿來作為兩種分布的度量優化生成器,但是W 距離裡面有一個
是沒辦法求解的。作者Martin 在論文附錄裡面通過定理将這個問題轉變成了一個新的問題,有着如下形式:
這裡引入了一個新的概念——Lipschitz 連續。如果函數f 滿足Lipschitz 連續條件,那麼它就滿足下面的式子:
我們不希望函數的變化太快,希望函數f 變化能比較平緩。
那麼可以将上面的式子改成GAN:
也就是說建構一個神經網絡D 作為判别器,希望D 輸出的變化比較平緩,在實際計算中限制D 中的參數大小不超過某個範圍,這樣就使得關于輸入的樣本,D 的輸出變化基本不會超過某個範圍,是以就能夠基本滿足Lipschitz 連續條件。
是以最後構造一個判别器D,滿足:
盡可能取到最大,同時D 還要滿足Lipschitz 連續條件,得到的L 可以近似為真實分布和生成分布的Wasserstein 距離。原始的GAN 做的是二分類的任務,也就是對于真假圖檔進行二分類,而WGAN 做的是回歸問題,相當于近似拟合Wasserstein 距離。
最後優化生成器的時候希望最小化L,這時候需要滿足Lipschitz 連續條件,是以需要做權重的裁剪,由于W 距離的優越性,不再需要擔心梯度消失的問題,這樣就能夠得到WGAN 的整個訓練過程。
總結一下,WGAN 與原始GAN 相比,隻改了以下四點:
(1)判别器最後一層去掉sigmoid;
(2)生成器和判别器的loss 不取log;
(3)每次更新判别器的參數之後把它們的絕對值裁剪到不超過一個固定常數的數;
(4)不要用基于動量的優化算法(比如momentuem 和Adam),推薦使用RMSProp。
前三點都是從理論分析得到的結果,第(4)點是作者從實驗中發現的。對于WGAN,論文作者做了不少實驗,得到了幾個結論:第一,WGAN 如果使用類似DCGAN 的結構,那麼和DCGAN 生成的圖檔差不多,但是WGAN 的優勢就在于不用DCGAN 的結構,也能生成效果比較好的圖檔,但是把DCGAN 的Batch Normalization 拿掉的話,DCGAN 就不能生成圖檔了;第二,WGAN 和原始的GAN 都是用多層全連接配接網絡的話,WGAN 生成的圖檔品質會變得差一些,但是原始的GAN 不僅品質很差,還有多樣性不足的問題。
WGAN 的提出成功地解決了GAN 的很多問題,最後需要滿足一階Lipschitz 連續性條件,是以在訓練的時候加了一個限制——權重裁剪。
然而權重的裁剪隻是一種簡單的做法,不是最好的做法,是以随後有人提出了一些新的辦法來解決這個問題。
首先提出一個定理:一個可微函數如果滿足1 階Lipschitz 連續,等價于它的梯度範數處小于1。用式子來表示就是:
有了這個定理,就能夠近似地這樣去表達W 距離:
不需要在整個分布上都滿足Lipschitz 條件,隻需要沿着一些直線上的點滿足這些,結果就已經很好了,同時在實際中采用的政策也不是取max,因為不希望
太小,是以做的是最小化
,最後改進的WGAN 就是:
改進後的WGAN 和改進前的WGAN 相比,訓練更加穩定,生成的圖檔效果也更好。
想及時獲得更多精彩文章,可在微信中搜尋“博文視點”或者掃描下方二維碼并關注。