前言
本文對 Recurrent Neural Network 在推薦領域的序列資料模組化進行梳理,整理推薦領域和深度學習領域頂會 RecSys、ICLR 等中的 9 篇論文進行整理。圖檔和文字來源于原文,幫助讀者了解,有争議的請聯系我。
Session-based neural recommendation
首先介紹下 session-based 的概念:session 是伺服器端用來記錄識别使用者的一種機制。典型的場景比如購物車,服務端為特定的對象建立了特定的 Session,用于辨別這個對象,并且跟蹤使用者的浏覽點選行為。我們這裡可以将其了解為具有時序關系的一些記錄序列。
寫作動機
傳統的兩類推薦方法——基于内容的推薦算法和協同過濾推薦算法(model-based,memory-based)在刻畫序列資料中存在缺陷:每個 item 互相獨立,不能模組化 session 中 item 的連續偏好資訊。
傳統的解決方法
1. item-to-item recommendation approach (Sarwar et al.,2001; Linden et al., 2003) : 采用 session 中 item 間的相似性預測下一個 item。缺點:隻考慮了最後一次的 click 的 item 相似性,忽視了前面的的 clicks, 沒有考慮整個序列資訊。
2. Markov decision Processes (MDPs)(Shani et al., 2002):馬爾科夫決策過程,用四元組<S,A, P, R>(S: 狀态, A: 動作, P: 轉移機率, R: 獎勵函數)刻畫序列資訊,通過狀态轉移機率的計算點選下一個動作:即點選 item 的機率。缺點:狀态的數量巨大,會随問題次元指數增加。MDPs 參見部落格[1]。
Deep Neural Network 的方法
Deep Neural Network(RNN:LSTM 和 GRU 的記憶性)被成功的應用在刻畫序列資訊。因為論文中主要采用 GRU,下面簡單介紹下 GRU(LSTM 詳解參考部落格[2])。
GRU的原理:GRU 輸入為前一時刻隐藏層
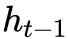
和目前輸入

,輸出為下一時刻隐藏層資訊
。GRU 包含兩個門
:reset 門和
: update 門,其中
用來計算候選隐藏層
,控制的是保留多少前一時刻隐藏層
的資訊;
用來控制加入多少候選隐藏層
的資訊,進而得到輸出
。GRU 可以靈活控制長短距離的依賴資訊,适合刻畫序列資料。
到此,已經說明用 GRU 來刻畫 session 中的序列的合理性。下面我們來梳理相關的工作。
Session-based recommendations with recurrent neural networks
ICLR 2016
本文的貢獻在于首次将 RNN 運用于 Session-based Recommendation,針對該任務設計了 RNN 的訓練、評估方法及 ranking loss。
Motivation (Why):第一篇提出将 RNN 應用到 session-based recommendation 的論文。
Main Idea (What):一個 session 中點選 item 的行為看做一個序列,用 GRU 來刻畫。
How:
模型(GRU4REC)架構
模型輸入:session 中的點選序列,
, 1 ≤ r < n,通過 one hot encoding 編碼,通過 embedding 層壓縮為低維連續向量作為 GRU 的輸入。
模型輸出:每一個 item 被點選的預測機率,y=M(x), where y=[y1, y2...ym]。
M:模型函數。yi 是 item i 的預測點選機率。
訓練政策
為了提高訓練的效率,文章采用兩種政策來加快簡化訓練代價,分别為:
Training strategy:為了更好的并行計算,論文采用了 mini-batch 的處理,即把不同的session 拼接起來,同一個 sequence 遇到下一個 Session 時,要注意将 GRU 中的一些向量重新初化。
Training data sample:因為 item 的次元非常高,item 數量過大的機率會導緻計算量龐大,是以隻選取目前的正樣本(即下一個點選的 item)加上随機抽取的負樣本。論文采用了取巧的方法來減少采樣需要的計算量,即選取了同一個 mini-batch 中其他 sequence 下一個點選的 item 作為負樣本,用這些正負樣本來訓練整個神經網絡。
損失函數
損失函數的選擇也影響着模型的效果,文章嘗試兩種損失函數:
Point-wise ranking loss,即認為負樣本為 0,正樣本為 1 的 loss function,發現訓練出來的模型并不穩定,因為在推薦裡面,并不存在絕對的正樣本和負樣本,使用者可能對多個 item 存在偏好。
故采用 Pairwise ranking,即正樣本的 loss 要低于負樣本。本文使用了兩種基于 Pairwise ranking 的 loss function:
BPR:一種矩陣分解法,公式:
TOP1:一種正則估計,公式:
資料集
RecSys Challenge 2015:網站點選流
Youtube-like OTT video service platform Collection
評價名額
recall@20、MRR
Baselines
POP:推薦訓練集中最受歡迎的 item;
S-POP:推薦目前 session 中最受歡迎的 item;
Item-KNN:推薦與實際 item 相似的 item,相似度被定義為 session 向量之間的餘弦相似度;
BPR-MF:一種矩陣分解法,新會話的特征向量為其内的 item 的特征向量的平均,把它作為使用者特征向量。
實驗結果及總結
Parallel Recurrent Neural Network Architectures for Feature-rich Session-based Recommendations
RecSys 2016
這篇文章主要貢獻:探究如何将 item 屬性資訊(如文本和圖像)加入到 RNN 架構中,探究了幾種融合 item 屬性的模型架構。
Motivation (Why): Items typically have rich feature representations such as pictures and text descriptions that can be used to model the sessions.
Main Idea (What): Here we investigate how these features can be exploited in Recurrent Neural Network based session models using deep learning.
How:
模型架構
模型輸入:item ID, Item features (texts and image)
模型輸出:next click scores of each items
1. Baseline architectures: ID only, Feature only, Concatenated input
2. p-RNN architectures: Parallel, Parallel shared-W, Parallel interaction
實驗結果及結論
Parallel 并行更新 item ID 和 feature 的模型達到最好的效果,Parallel shared-W 和 Parallel interaction 互動模型并沒有好的效果,可能原因重複的序列資訊加重了模型的訓練負擔。
Incorporating Dwell Time in Session-Based Recommendations with Recurrent Neural Networks
RecSys 2017
本文的貢獻在于将使用者在 session 中 item 上的停留時間長短考慮進去。
Motivation (Why): 使用者在 session 中的 item 停留時間越長,越感興趣。
Main Idea (What): We explore the value of incorporating dwell time into existing RNN framework for session-based recommendations by boosting items above the predefined dwell time threshold.
模型架構
對于 session 中的一個序列 item 集合 x= { [x1,x2...xn] },以及每個 item xi 的停留時間
,設定機關時間門檻值 t。如此我們可以将每個 item 按照機關時間劃分成
個時間片。如下圖所示,其餘訓練方式與第一篇文章相同,實驗證明可以提升推薦效果。
實驗結果
Personalizing Session-based Recommendations with Hierarchical Recurrent Neural Networks
本文的貢獻在于提出一種階層化的 RNN 模型,相比之前的工作,可以刻畫 session 中使用者個人的興趣變化,做使用者個性化的 session 推薦。
Motivation (Why): 使用者的曆史資訊反映了使用者的興趣愛好,應該在下一個 session 的推薦中考慮進去。
Main Idea (What): 提出一種階層化的 RNN 模型,可以解決 (1) session-aware recommenders:傳遞使用者的曆史興趣愛好到下一個 session 中;(2) session-based recommenders:當使用者沒有曆史記錄時,對使用者目前 session 進行模組化。
用兩個 GRU,Session-level GRU 和 User-level 的 GRU 分别刻畫 session 資訊和 user曆史資訊,模型架構圖如下,對于一個使用者的多個 sessions,當一個 session 結束時,用該 session 的輸出作為目前的 user 的表示,并用來初始化下一個 session 的輸入。
資料集
Baseline
When Recurrent Neural Networks meet the Neighborhood for Session-Based Recommendation
本文的貢獻在于提出将 session 中的 RNN 模型,與 KNN 方法結合起來,能夠提高推薦的效果。
Motivation (Why): 如果一個 item 在與目前 item 相似的 session 中出現,那麼這個 item 出現的可能性更大。
Main Idea (What): 提出一種 Session-based kNN 算法。
session-based 方法
找出與目前 session 最相近的 k most similar past sessions in the training data。
item i 在目前 session 中出現的機率是:
如果 item i 有出現在 k 個最相近的 session 中,
,如果沒有,那麼認為該 item 不會出現在目前 session 中。
Hybrid Approach:将 session-based 方法和 kNN 方法結合推薦效果最好。
結論:item 的共現信号 co-occurrence signals 可以用來預測 sequential patterns。
Improved Recurrent Neural Networks for Session-based Recommendations
DLRS 2016
本文的貢獻在于提出将在 GRU4REC 中引入了四條優化方法。
Data augmentation(資料增強)
給定一個session的輸入序列 [x1,x2...xn] , 可以産生多條訓練資料,如([x1,V(x2)], [x1,x2, V(x3)] )如下圖,可以增加訓練資料。此外,使用者可能出現誤點選的,用 dropout 的方式來泛化資料,可以增強訓練的魯棒性。
Model pre-training
在推薦中,對于 user 和 item 更新都很快的推薦場景,最近的資訊更為重要,文本提出先利用曆史所有資料預訓練出一個模型,然後隻選取最近的資料,以預訓練得到的模型權重作為初始化參數,再訓練一個最終模型。
Use of Privileged information
這是一個 generalized distillation framework。給定序列 [x1,x2...xr] 和對應 label
,其相應的 privileged sequence 為
,對應 label 為
,其中 n 為該 session 總長度(剩餘序列的逆序列)。此時 loss function 變為:
其中 L 為距離函數,V(xr) 是 xr 的标簽。
Output embedding
直接預測 item 的 embedding 向量。使預測結果更具有泛化意義,相當于預測了使用者 embedding 後的語義空間中興趣表示,訓練時定義的 loss 為輸出層與該樣本在 embedding 層的 cosine 相似度。
現有 session-based neural recommendation 論文對比如下:
原文釋出時間為:2017-11-9
本文作者:白婷