本節書摘來自華章計算機《高性能科學與工程計算》一書中的第1章,第1.7節,作者:(德)Georg Hager Gerhard Wellein 更多章節内容可以通路雲栖社群“華章計算機”公衆号檢視。
1.1 除法的速度。寫一段代碼對下列函數積分:
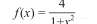
x從0~1,結果應該是π的近似值。用一個簡單的矩形積分就可以實作,即矩形寬為xi,步長Δx,高為f(xi),對面積累加:

https://yqfile.alicdn.com/11ffab67a981a59cd14a151369a5f6e148d4e87a.png" >
完成程式段,選擇合适的Δx,判斷結果是不是π的近似值,并計算性能,結果機關為MFlop/s。假設浮點除法不能被流水線運作,試估計延遲為多少時間周期。
1.2 資料依賴。在1.2.3節我們讨論了流水線,請看以下代碼:
s是一個非零的雙精度浮點标量,ofs是一個正整數,A是一個長度為N的雙精度數組。如果N足夠小,能使數組A的元素在L1 cache中都能命中,對于不同的ofs,請預計循環的性能。
1.3 硬體預取。預取是一個有效利用記憶體接口的重要操作。x86設計的硬體預取通常一次取滿整記憶體頁資料。試說明這可能對程式性能産生的負面效應。
1.4 點積和預取。考慮雙精度浮點數的點積操作:
https://yqfile.alicdn.com/25e3361b8572c5b691ce0f1ddcb946c54b36d54d.png" >
N非常大。CPU(時間周期為1ns)能在一個周期内做一次讀取(或者存儲),一次乘法和一次加法(假設循環計數和分支不産生時間消耗)。存儲總線的傳輸速率為3.2GB/s。假設從存儲讀取一個cache行的延遲為100個CPU周期,一個cache行的長度為4個雙精度浮點數。在以下情況下:
(a)如果沒有指令預取,循環的性能怎樣?
(b)假設CPU有預取的能力,為了使代碼有效利用帶寬(隐藏延遲),需要CPU能容忍預取多少條指令?
(c)如果cache行的長度變為以前的2倍、4倍,(b)中算出的數值會怎樣變化?
(d)如果我們假設指令預取能隐藏所有的延遲,循環的性能怎樣?