内容如下:
神經網絡本質上是一種語言,我們通過它來表達對應用問題的了解。例如我們用卷積層來表達空間相關性,RNN來表達時間連續性。根據問題的複雜性和資訊如何從輸入到輸出一步步提取,我們将不同大小的層按一定原則連接配接起來。近年來随着資料的激增和計算能力的大幅提升,神經網絡也變得越來越深和大。例如最近幾次imagnet競賽的冠軍都使用有數十至百層的網絡。對于這一類神經網絡我們通常稱之為深度學習。從應用的角度而言,對深度學習最重要的是如何友善的表述神經網絡,以及如何快速訓練得到模型。
對于一個優秀的深度學習系統,或者更廣來說優秀的科學計算系統,最重要的程式設計接口的設計。他們都采用将一個領域特定語言(domain specific language)嵌入到一個主語言中。例如numpy将矩陣運算嵌入到python中。這類嵌入一般分為兩種,其中一種嵌入的較淺,其中每個語句都按原來的意思執行,且通常采用指令式程式設計(imperative programming),其中numpy和Torch就是屬于這種。而另一種則用一種深的嵌入方式,提供一整套針對具體應用的迷你語言。這一種通常使用聲明式語言(declarative programing),既使用者隻需要聲明要做什麼,而具體執行則由系統完成。這類系統包括Caffe,theano和剛公布的TensorFlow。
這兩種方式各有利弊,總結如下
淺嵌入,指令式程式設計
深嵌入,聲明式程式設計
如何執行a=b+1
需要b已經被指派。立即執行加法,将結果儲存在a中。
傳回對應的計算圖(computation graph),我們可以之後對b進行指派,然後再執行加法運算
優點
語義上容易了解,靈活,可以精确控制行為。通常可以無縫的和主語言互動,友善的利用主語言的各類算法,工具包,bug和性能調試器。
在真正開始計算的時候已經拿到了整個計算圖,是以我們可以做一系列優化來提升性能。實作輔助函數也容易,例如對任何計算圖都提供forward和backward函數,對計算圖進行可視化,将圖儲存到硬碟和從硬碟讀取。
缺點
實作統一的輔助函數困和提供整體優化都很困難。
很多主語言的特性都用不上。某些在主語言中實作簡單,但在這裡卻經常麻煩,例如if-else語句 。debug也不容易,例如監視一個複雜的計算圖中的某個節點的中間結果并不簡單。
目前現有的系統大部分都采用上兩種程式設計模式的一種。與它們不同的是,MXNet嘗試将兩種模式無縫的結合起來。在指令式程式設計上MXNet提供張量運算,而聲明式程式設計中MXNet支援符号表達式。使用者可以自由的混合它們來快速實作自己的想法。例如我們可以用聲明式程式設計來描述神經網絡,并利用系統提供的自動求導來訓練模型。另一友善,模型的疊代訓練和更新模型法則中可能涉及大量的控制邏輯,是以我們可以用指令式程式設計來實作。同時我們用它來進行友善的調式和與主語言互動資料。
下表我們比較MXNet和其他流行的深度學習系統
主語言
從語言
硬體
分布式
指令式
聲明式
Caffe
C++
Python/Matlab
CPU/GPU
x
v
Torch
Lua
-
CPU/GPU/FPGA
Theano
Python
TensorFlow
CPU/GPU/Mobile
MXNet
Python/R/Julia/Go
(注,TensforFlow暫時沒有公開其分布式實作)
MXNet的系統架構如下圖所示:
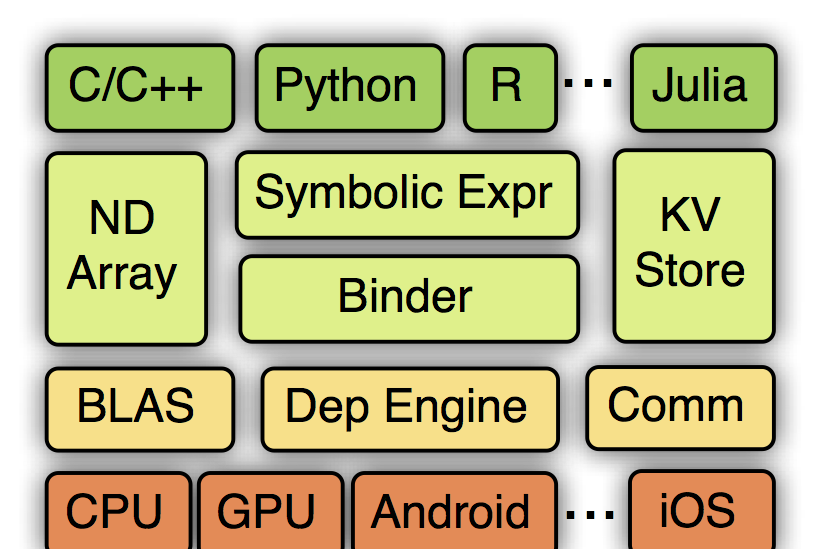
從上到下分别為各種主語言的嵌入,程式設計接口(矩陣運算,符号表達式,分布式通訊),兩種程式設計模式的統一系統實作,以及各硬體的支援。接下一章我們将介紹程式設計接口,然後下一章介紹系統實作。之後我們給出一些實驗對比結果,以及讨論MXNet的未來。
MXNet使用多值輸出的符号表達式來聲明計算圖。符号是由操作子建構而來。一個操作子可以是一個簡單的矩陣運算“+”,也可以是一個複雜的神經網絡裡面的層,例如卷積層。一個操作子可以有多個輸入變量和多個輸出變量,還可以有内部狀态變量。一個變量既可以是自由的,我們可以之後對其指派;也可以是某個操作子的輸出。例如下面的代碼中我們使用Julia來定義一個多層感覺機,它由一個代表輸入資料的自由變量,和多個神經網絡層串聯而成。
在執行一個符号表達式前,我們需要對所有的自由變量進行指派。上例中,我們需要給定資料,和各個層裡隐式定義的輸入,例如全連接配接層的權重和偏值。我們同時要申明所需要的輸出,例如softmax的輸出。
除了執行獲得softmax輸出外(通常也叫forward),符号表達式也支援自動求導來擷取各權重和偏值對應的梯度(也稱之為backward)。此外,我們還可以提前估計計算時需要的記憶體,符号表達式的可視化,讀入和輸出等。
MXNet提供指令式的張量計算來橋接主語言的和符号表達式。下面代碼中,我們在GPU上計算矩陣和常量的乘法,并使用numpy來列印結果
另一方面,NDArray可以無縫和符号表達式進行對接。假設我們使用Symbol定義了一個神經網絡,那麼我們可以如下實作一個梯度下降算法
這裡梯度由Symbol計算而得。Symbol的輸出結果均表示成NDArray,我們可以通過NDArray提供的張量計算來更新權重。此外,我們還利用了主語言的for循環來進行疊代,學習率eta也是在主語言中進行修改。
上面的混合實作跟使用純符号表達式實作的性能相差無二,然後後者在表達控制邏輯時會更加複雜。其原因是NDArray的執行會和Symbol類似的建構一個計算圖,并與其他運算一同交由背景引擎執行。對于運算<code>-=</code>由于我們隻是将其結果交給另一個Symbol的forward作為輸入,是以我們不需要立即得到結果。當上面的for循環結束時,我們隻是将數個Symbol和NDarray對應的計算圖送出給了背景引擎。當我們最終需要結果的時候,例如将weight複制到主語言中或者儲存到磁盤時,程式才會被阻塞直到所有計算完成。
MXNet提供一個分布式的key-value存儲來進行資料交換。它主要有兩個函數,
1. push: 将key-value對從一個裝置push進存儲
2. pull:将某個key上的值從存儲中pull出來此外,KVStore還接受自定義的更新函數來控制收到的值如何寫入到存儲中。最後KVStore提供數種包含最終一緻性模型和順序一緻性模型在内的資料一緻性模型。
在下面例子中,我們将前面的梯度下降算法改成分布式梯度下降。
在這裡我們先使用最終一緻性模型建立一個kvstore,然後将更新函數注冊進去。在每輪疊代前,每個計算節點先将最新的權重pull回來,之後将計算的得到的梯度push出去。kvstore将會利用更新函數來使用收到的梯度更新其所存儲的權重。
這裡push和pull跟NDArray一樣使用了延後計算的技術。它們隻是将對應的操作送出給背景引擎,而引擎則排程實際的資料互動。是以上述的實作跟我們使用純符号實作的性能相差無幾。
資料讀取在整體系統性能上占重要地位。MXNet提供工具能将任意大小的樣本壓縮打包成單個或者數個檔案來加速順序和随機讀取。
通常資料存在本地磁盤或者遠端的分布式檔案系統上(例如HDFS或者Amazon S3),每次我們隻需要将目前需要的資料讀進記憶體。MXNet提供疊代器可以按塊讀取不同格式的檔案。疊代器使用多線程來解碼資料,并使用多線程預讀取來隐藏檔案讀取的開銷。
MXNet實作了常用的優化算法來訓練模型。使用者隻需要提供資料資料疊代器和神經網絡的Symbol便可。此外,使用者可以提供額外的KVStore來進行分布式的訓練。例如下面代碼使用分布式異步SGD來訓練一個模型,其中每個計算節點使用兩快GPU。
一個已經指派的符号表達式可以表示成一個計算圖。下圖是之前定義的多層感覺機的部分計算圖,包含forward和backward。
<a href="https://raw.githubusercontent.com/dmlc/web-data/master/mxnet/paper/graph.png" target="_blank"></a>
其中圓表示變量,方框表示操作子,箭頭表示資料依賴關系。在執行之前,MXNet會對計算圖進行優化,以及為所有變量提前申請空間。
計算圖優化已經在資料庫等領域被研究多年,我們目前隻探索了數個簡單的方法。
1. 注意到我們提前申明了哪些輸出變量是需要的,這樣我們隻需要計算這些輸出需要的操作。例如,在預測時我們不需要計算梯度,是以整個backforward圖都可以忽略。而在特征抽取中,我們可能隻需要某些中間層的輸出,進而可以忽略掉後面的計算。
2. 我們可以合并某些操作。例如 ab+1*隻需要一個blas或者cuda函數即可,而不需要将其表示成兩個操作。
3. 我們實作了一些“大”操作,例如一個卷積層就隻需要一個操作子。這樣我們可以大大減小計算圖的大小,并且友善手動的對這個操作進行優化。
記憶體通常是一個重要的瓶頸,尤其是對GPU和智能裝置而言。而神經網絡計算時通常需要大量的臨時空間,例如每個層的輸入和輸出變量。對每個變量都申請一段獨立的空間會帶來高額的記憶體開銷。幸運的是,我們可以從計算圖推斷出所有變量的生存期,就是這個變量從建立到最後被使用的時間段,進而可以對兩個不交叉的變量重複使用同一記憶體空間。這個問題在諸多領域,例如編譯器的寄存器配置設定上,有過研究。然而最優的配置設定算法需要 O(n2) 時間複雜度,這裡n是圖中變量的個數。
MXNet提供了兩個啟發式的政策,每個政策都是線性的複雜度。
1. inplace。在這個政策裡,我們模拟圖的周遊過程,并為每個變量維護一個還有多少其他變量需要它的計數。當我們發現某個變量的計數變成0時,我們便回收其記憶體空間。
2. co-share。我們允許兩個變量使用同一段記憶體空間。這麼做當然會使得這兩個變量不能同時在寫這段空間。是以我們隻考慮對不能并行的變量進行co-share。每一次我們考慮圖中的一條路(path),路上所有變量都有依賴關系是以不能被并行,然後我們對其進行記憶體配置設定并将它們從圖中删掉。
在MXNet中,所有的任務,包括張量計算,symbol執行,資料通訊,都會交由引擎來執行。首先,所有的資源單元,例如NDArray,随機數生成器,和臨時空間,都會在引擎處注冊一個唯一的标簽。然後每個送出給引擎的任務都會标明它所需要的資源标簽。引擎則會跟蹤每個資源,如果某個任務所需要的資源到到位了,例如産生這個資源的上一個任務已經完成了,那麼引擎會則排程和執行這個任務。
通常一個MXNet運作執行個體會使用多個硬體資源,包括CPU,GPU,PCIe通道,網絡,和磁盤,是以引擎會使用多線程來排程,既任何兩個沒有資源依賴沖突的任務都可能會被并行執行,以求最大化資源利用。
與通常的資料流引擎不同的是,MXNet的引擎允許一個任務修改現有的資源。為了保證排程正确性,送出任務時需要分開标明哪些資源是隻讀,哪些資源會被修改。這個附加的寫依賴可以帶來很多便利。例如我們可以友善實作在numpy以及其他張量庫中常見的數組修改操作,同時也使得記憶體配置設定時更加容易,比如操作子可以修改其内部狀态變量而不需要每次都重來記憶體。再次,假如我們要用同一個種子生成兩個随機數,那麼我們可以标注這兩個操作會同時修改種子來使得引擎不會并行執行,進而使得代碼的結果可以很好的被重複。
KVStore的實作是基于參數伺服器。但它跟前面的工作有兩個顯著的差別。
1. 我們通過引擎來管理資料一緻性,這使得參數伺服器的實作變得相當簡單,同時使得KVStore的運算可以無縫的與其他結合在一起。
2. 我們使用一個兩層的通訊結構,原理如下圖所示。第一層的伺服器管理單機内部的多個裝置之間的通訊。第二層伺服器則管理機器之間通過網絡的通訊。第一層的伺服器在與第二層通訊前可能合并裝置之間的資料來降低網絡帶寬消費。同時考慮到機器内和外通訊帶寬和延時的不同性,我們可以對其使用不同的一緻性模型。例如第一層我們用強的一緻性模型,而第二層我們則使用弱的一緻性模型來減少同步開銷。
<a href="https://raw.githubusercontent.com/dmlc/web-data/master/mxnet/paper/ps.png" target="_blank"></a>
輕量和可移植性是MXNet的一個重要目标。MXNet核心使用C++實作,并提供C風格的頭檔案。是以友善系統移植,也使得其很容易被其他支援C FFI (forigen language interface )的語言調用。此外,我們也提供一個腳本将MXNet核心功能的代碼連同所有依賴打包成一個單一的隻有數萬行的C++源檔案,使得其在一些受限的平台,例如智能裝置,友善編譯和使用。
這裡我們提供一些早期的實驗結果。
我們首先使用一個流行卷積網絡測試方案來對比MXNet與Torch,Caffe和TensorFlow在過去幾屆imagenet競賽冠軍網絡上的性能。每個系統使用同樣的CUDA 7.0和CUDNN 3,但TensorFlow使用其隻支援的CUDA 6.5 和CUDNN 2。我們使用單塊GTX 980并報告單個forward和backward的耗時。
<a href="https://raw.githubusercontent.com/dmlc/web-data/master/mxnet/paper/time_forward_backward.png" target="_blank"></a>
可以看出MXNet,Torch和Caffe三者在性能上不相上下。這個符合預期,因為在單卡上我們評測的幾個網絡的絕大部分運算都由CUDA和CUDNN完成。TensorFlow比其他三者都慢2倍以上,這可能由于是低版本的CUDNN和項目剛開源的緣故。
接下來我們考察不同的記憶體配置設定算法對記憶體占用的影響。下圖分别表示使用batch=128時,在做預測時和做訓練時的不同算法在内部變量(除去模型,最初輸入和最終輸出)上的記憶體開銷。

可以看出,inplace和co-share兩者都可以極大的降低記憶體使用。将兩者合起來可以在訓練時減少2倍記憶體使用,在預測時則可以減小4倍記憶體使用。特别的,即使是最複雜的vggnet,對單張圖檔進行預測時,MXNet隻需要16MB額外記憶體。
最後我們報告在分布式訓練下的性能。我們使用imagenet 1k資料(120萬224x224x3圖檔,1000類),并用googlenet加上batch normalization來訓練。我們使用Amazon EC2 g2.8x,單機和多機均使用同樣的參數,下圖表示了使用單機和10台g2.8x時的收斂情況。
從訓練精度來看,單機的收斂比多機快,這個符合預期,因為多機時有效的batch大小比單機要大,在處理同樣多的資料上收斂通常會慢。但有意思的是兩者在測試精度上非常相似。
單機下每周遊一次資料需要1萬4千秒,而在十台機器上,每次隻需要1千4百秒。如果考慮運作時間對比測試精度,10台機器帶來了10倍的提升。
大半年前我們拉來數個優秀的C++機器學習系統的開發人員成立了DMLC,本意是更友善共享各自項目的代碼,并給使用者提供一緻的體驗。當時我們有兩個深度學習的項目,一個是CXXNet,其通過配置來定義和訓練神經網絡。另一個是Minerva,提供類似numpy一樣的張量計算接口。前者在圖檔分類等使用卷積網絡上很友善,而後者更靈活。那時候我們想要能不能一個兩者功能都具備的系統,于是這樣就有了MXNet。其名字來自Minerva的M和CXXNet的XNet。其中Symbol的想法來自CXXNet,而NDArray的想法來自Minerva。我們也常把MXNet叫“mix net”。
MXNet是DMLC第一個結合了所有的成員努力的項目,也同時吸引了很多核心成員的加入。MXNet目的是做一個有意思的系統,能夠讓大家用着友善的系統,一個輕量的和可以快速測試系統和算法想法的系統。對于未來,我們主要關注下面四個方向:
支援更多的硬體,我們目前在積極考慮支援AMD GPU,高通GPU,Intel Phi,FPGA,和更多智能裝置。相信MXNet的輕量和記憶體節省可以在這些上大有作為。
更加完善的操作子。目前不論是Symbol還是NDArray支援的操作還是有限,我們希望能夠盡快的擴充他們。
更多程式設計語言。除了C++,目前MXNet對Python,R和Julia的支援比較完善。但我們希望還能有很多的語言,例如javascript。
更的應用。我們之前花了很多精力在圖檔分類上,下面我們會考慮很多的應用。例如上周我們試了下如何利用一張圖檔的風格和一張圖檔的内容合成一張新圖檔。下圖是利用我辦公室窗景和梵高的starry night來合成圖檔
<a href="https://github.com/dmlc/web-data/raw/master/mxnet/neural-style/output/4343_starry_night.jpg" target="_blank"></a>
接下來我們希望能夠在更多應用,例如語音,翻譯,問答,上有所産出。
我們忠心希望MXNet能為大家做深度學習相關研究和應用帶來便利。也希望能與更多的開發者一起學習和進步。