1. 火箭發射:一種有效的輕量網絡訓練架構《Rocket Launching: A Universal and Efficient Framework for Training Well-performing Light Net》
【團隊名稱】阿裡媽媽事業部
【作者】周國睿、範穎、崔潤鵬、卞維傑、朱小強、蓋坤
【論文簡介】像點選率預估這樣的線上實時響應系統對響應時間要求非常嚴格,結構複雜,層數很深的深度模型不能很好的滿足嚴苛的響應時間的限制。為了獲得滿足響應時間限制的具有優良表現的模型,我們提出了一個新型架構:訓練階段,同時訓練繁簡兩個複雜度有明顯差異的網絡,簡單的網絡稱為輕量網絡(light net),複雜的網絡稱為助推器網絡(booster net),相比前者,有更強的學習能力。兩網絡共享部分參數,分别學習類别标記,此外,輕量網絡通過學習助推器的soft target來模仿助推器的學習過程,進而得到更好的訓練效果。測試階段,僅采用輕量網絡進行預測。我們的方法被稱作“火箭發射”系統。在公開資料集和阿裡巴巴的線上展示廣告系統上,我們的方法在不提高線上響應時間的前提下,均提高了預測效果,展現了其在線上模型上應用的巨大價值。
【方法架構】
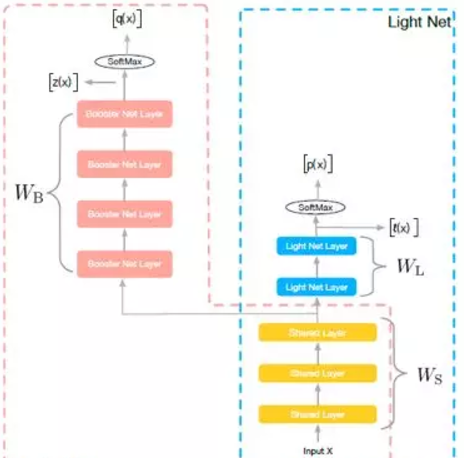
圖1:網絡結構
如圖1所示,訓練階段,我們同時學習兩個網絡:Light Net 和Booster Net, 兩個網絡共享部分資訊。我們把大部分的模型了解為表示層學習和判别層學習,表示層學習的是對輸入資訊做一些高階處理,而判别層則是和目前子task目标相關的學習,我們認為表示層的學習是可以共享的,如multi task learning中的思路。是以在我們的方法裡,共享的資訊為底層參數(如圖像領域的前幾個卷積層,NLP中的embedding), 這些底層參數能一定程度上反應了對輸入資訊的基本刻畫。
【論文連結】https://arxiv.org/abs/1708.04106
2. 基于對抗學習的衆包标注用于中文命名實體識别
《Adversarial Learning for Chinese NER from Crowd Annotations》
【團隊名稱】業務平台事業部
【主要作者】楊耀晟,張梅山,陳文亮,王昊奮,張偉,張民
【文章簡介】為了能用較低的成本擷取新的标注資料,我們采用衆包标注的方法來完成這個任務。衆包标注的資料是沒有經過專家标注員稽核的,是以它會包含一定的噪聲。在這篇文章中,我們提出一種在中文NER任務上,利用衆包标注結果來訓練模型的方法。受到對抗學習的啟發,我們在模型中使用了兩個雙向LSTM子產品,來分别學習衆包标注資料中的公有資訊和屬于不同标注員的私有資訊。對抗學習的思想展現在公有塊的學習過程中,以不同标注員作為分類目标進行對抗學習,進而優化公有子產品的學習品質,使之收斂于真實資料(專家标注資料)。我們認為這兩個子產品學習到的資訊對于任務學習都有積極作用,并在最終使用CRF層完成ner标注。
【模型如下】

3. 句法敏感的實體表示用于神經網絡關系抽取
《Syntax-aware Entity Embedding for Neural Relation Extraction》
【作者】何正球,陳文亮,張梅山,李正華,張偉,張民
【論文簡介】句法敏感的實體表示用于神經網絡關系抽取。關系抽取任務大規模應用的一個主要瓶頸就是語料的擷取。近年來基于神經網絡的關系抽取模型把句子表示到一個低維空間。這篇論文的創新在于把句法資訊加入到實體的表示模型裡。首先,基于Tree-GRU,把實體上下文的依存樹放入句子級别的表示。其次,利用句子間和句子内部的注意力,來獲得含有目标實體的句子集合的表示。
【主要方法】
首先,基于依存句法樹,利用基于樹結構的循環神經網絡(Tree-GRU)模型生成實體在句子級别的表示。如上圖所示,有别于僅僅使用實體本身,我們能夠更好地表達出長距離的資訊。具體的實體語義表示如下圖所示。我們使用Tree-GRU來獲得實體的語義表示。
其次,利用基于子節點的注意力機制(ATTCE,上圖)和基于句子級别的實體表示注意力機制(ATTEE,下圖)來減輕句法錯誤和錯誤标注的負面影響。
4. 一種基于詞尾預測的提高英俄翻譯品質的方法
Improved English to Russian Translation by Neural Suffix Prediction
【團隊】iDst-NLP-翻譯平台
【作者】宋楷/Kai Song(阿裡巴巴), 張嶽/Yue Zhang(新加坡科技設計大學), 張民/Min Zhang (蘇州大學), 駱衛華/Weihua Luo(阿裡巴巴)
【論文簡介】神經網絡翻譯模型受限于其可以使用的詞表大小,經常會遇到詞表無法覆寫源端和目标端單詞的情況,特别是當處理形态豐富的語言(例如俄語、西班牙語等)的時候,詞表對全部語料的覆寫度往往不夠,這就導緻很多“未登入詞”的産生,嚴重影響翻譯品質。
已有的工作主要關注在如何調整翻譯粒度以及擴充詞表大小兩個次元上,這些工作可以減少“未登入詞”的産生,但是語言本身的形态問題并沒有被真正研究和專門解決過。
我們的工作提出了一種創新的方法,不僅能夠通過控制翻譯粒度來減少資料稀疏,進而減少“未登入詞”,還可以通過一個有效的詞尾預測機制,大大降低目标端俄語譯文的形态錯誤,提高英俄翻譯品質。通過和多個比較有影響力的已有工作(基于subword和character的方法)對比,在5000萬量級的超大規模的資料集上,我們的方法可以成功的在基于RNN和Transformer兩種主流的神經網絡翻譯模型上得到穩定的提升。
【詞尾預測網絡】在NMT的解碼階段,每一個解碼步驟分别預測詞幹和詞尾。詞幹的生成和NMT原有的網絡結構一緻。額外的,利用目前step生成的詞幹、目前decoder端的hidden state和源端的source context資訊,通過一個前饋神經網絡(Feedforward neural network)生成目前step的詞尾。網絡結構如下圖:
最後,将生成的詞幹和詞尾拼接在一起,就是目前step的譯文單詞。
5. 一種利用使用者搜尋日志進行多任務學習的商品标題壓縮方法
A Multi-task Learning Approach for Improving Product Title Compression with User Search Log Data
【團隊】iDST-NLP
【作者】王金剛,田俊峰(華東師大),裘龍(Onehome),李生,郎君,司羅,蘭曼(華東師大)
【論文簡介】在淘寶、天貓等電商平台,商家為了搜尋引擎優化(SEO),撰寫的商品标題通常比較備援,尤其是在APP端等展示空間有限的場景下,過長的商品标題往往不能完全顯示,隻能進行截斷處理,嚴重影響使用者體驗。如何将原始商品标題壓縮到限定長度内,而不影響整體成交是一個極具挑戰的任務。以往的标題摘要方法往往需要大量的人工預處理,成本較高,并且未考慮電商場景下對點選率、轉化率等名額的特殊需求。基于此,我們提出一種利用使用者搜尋日志進行多任務學習的商品标題壓縮方法。該方法同時進行兩個Sequence-to-Sequence學習任務:主任務基于Pointer Network模型實作從原始标題到短标題的抽取式摘要生成,輔任務基于帶有注意力機制的encoder-decoder模型實作從原始标題生成對應商品的使用者搜尋query。兩個任務之間共享編碼網絡參數,并對兩者的對原始标題的注意力分布進行聯合優化,使得兩個任務對于原始标題中重要資訊的關注盡可能一緻。離線人工評測和線上實驗證明通過多任務學習方法生成的商品短标題既保留了原始商品标題中的核心資訊又能透出使用者搜尋query資訊,保證成交轉化不受影響。
【方法介紹】如圖2(下)所示,本文提出的多任務學習方法包含兩個Sequence to Sequence任務,主任務是商品标題壓縮,由商品原始标題生成短标題,采用Pointer Network模型,通過attention機制選取原始标題的關鍵字輸出;輔助任務是搜尋query生成,由商品原始标題生成搜尋query,采用帶attention機制的encoder-decoder模型。兩個任務共享編碼網絡參數,并對兩者的對原始标題的注意力分布進行聯合優化,使得兩個任務對于原始标題中重要資訊的關注盡可能一緻。 輔助任務的引入可以幫助主任務更好地從原始标題中保留更有資訊量、更容易吸引使用者點選的詞。相應地,我們為兩個任務建構訓練資料,主任務使用的資料為女裝類目下的商品原始标題和手淘推薦頻道達人改寫的商品短标題,輔助任務使用的資料為女裝類目下的商品原始标題和對應的引導成交的使用者搜尋query。
圖2. 多任務學習架構, 兩個Seq2Seq任務共享同一個encoder
6. τ-FPL: 線性時間的限制容忍分類學習算法
τ-FPL: Tolerance-Constrained Learning in Linear Time
【團隊名稱】iDST
【作者】張翺,李楠,浦劍,王駿,嚴駿馳,查宏遠
【論文簡介】許多實際應用需要在滿足假陽性率上限限制的前提下學習一個二分類器。對于該問題,現存方法往往通過調整标準分類器的參數,或者引入基于領域知識的不平衡分類損失來達到目的。由于沒有顯式地将假陽性率上限融合到模型訓練中,這類方法的精度往往受到制約。本文提出了一個新的排序-門檻值方法τ-FPL 解決這個問題。首先,我們設計了一個新的排序學習方法,其顯式地将假陽性率上限值納入考慮,并且展示了如何高效地線上性時間内求得該排序問題的全局最優解;而後将學到的排序函數轉化為一個低假陽性率的分類器。通過理論誤差分析以及實驗,我們驗證了τ-FPL對比傳統方法在性能及精度上的優越性。
原文釋出時間為:2017-12-29
本文來自雲栖社群合作夥伴新智元,了解相關資訊可以關注“AI_era”微信公衆号