OpenSearch : 是一款結構化資料搜尋托管服務,為移動應用開發者和網站站長提供簡單、高效、穩定、低成本(?)和可擴充的搜尋解決方案。
OpenSearch的産品架構在官方文檔處可以查閱
<a href="https://help.aliyun.com/document_detail/29108.html?spm=5176.doc29104.6.540.0YyjoL">https://help.aliyun.com/document_detail/29108.html?spm=5176.doc29104.6.540.0YyjoL</a>
今天我們不談架構層面的問題,單從使用者的角度來和大家分享下使用OpenSearch的一些值得注意的點,忝為最佳實踐:)
假設你已經接觸過opensearch, 有了一定的opensearch的概念及使用基礎,那麼這篇分享很适合你
opensearch有2個版本應用可建立,大家應根據業務場景進行選擇
<code>标準版</code> 做搜尋加速,實時,僅支援單表,不支援下拉提示,部分區域不支援标準版。
<code>進階版</code> 多表聯合檢索,且對實時性要求不是非常高(以我們的使用情形看,阿裡雲保證的準實時還是有保障的)
當用到進階版opensearch并且需要多表聯合檢索時,其中一個很重要的概念就是主表與附表,按照官方解釋:主表與附表僅支援 N : 1的關系,打個比方,如果主表是商品,附表是商鋪,那麼多個商品可以屬于一個商鋪,但是反過來卻不行;那麼在業務開發中,如何更加快速的确定哪個表是主表呢?我的常用做法是:
假設有表A、B、C,A與B通過字段x_id關聯;A與C通過y_id關聯;那麼基本可以确定A作為主表,驗證的方法是,假定A中有一條記錄rowA,通過這條記錄的x_id能不能找到唯一的一條B記錄,通過y_id能不能找到唯一的一條C記錄,如果均可以,那麼,A即主表
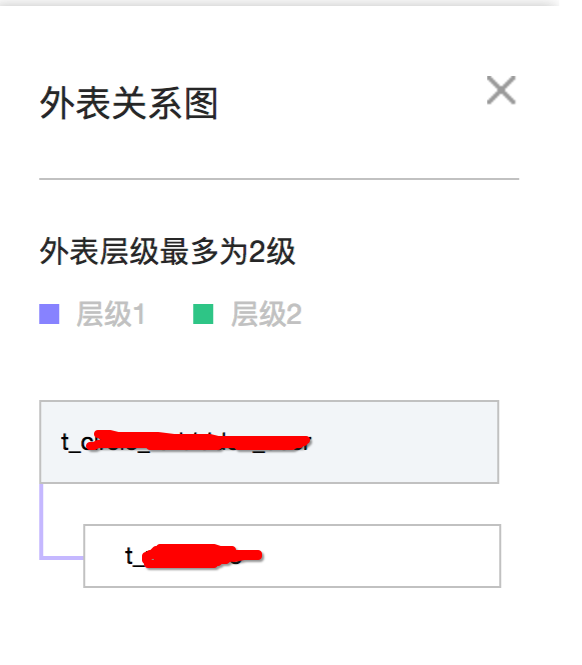
明确了主附表後,我們定義完應用結構後,可以看一看是否設定正确,所有表是否都關聯上了。如下圖:灰色底的表為主表,白色底的表為附表
opensearch中另一個很重要的概念就是分詞,分詞方式決定了你檢索時opensearch如何召回文檔。目前常用的中文分詞為模糊分詞與中文基礎分詞。
模糊分詞: 僅支援short_text類型, 支援拼音、前字尾、單數字、單字母方式檢索,召回量大,是以性能有損失。如果文檔量非常大,建議慎用。 基礎分詞:适合語義化的場景搜尋,比較适合文檔的标題,正文檢索。
建立好應用結構後,需要選擇資料源,告訴opensearch從哪擷取資料進行文檔的索引重建。這裡有個小tip,如果在建立應用結構時,字段名與資料源中的字段名一緻,那麼選擇好rds或者odps後,opensearch可以自動映射好各個字段。
在建立應用時,建議事先多想想需要哪些字段;否則,後期重新添加字段,修改資料源并重建索引的話,往往耗時較久
opensearch一個很友善的功能就是下拉提示,下拉提示的索引重建是不支援增量資料的,而且背景沒有提供明顯的入口讓使用者去重建下拉提示的索引,那麼當業務經過一段時間的發展,需要重建下拉提示索引,如何做呢?有個方法就是在如圖處,叉掉之前的來源字段,然後重新選擇一下這個字段,點選儲存,然後你就會發現“生效下拉提示”這個按鈕可以點了,點選即可重建下拉提示的索引。(不知道是阿裡雲遺留的bug還是故意做的不明顯。。。)ps: 重建下拉提示索引是不收費的:)

這個在官方文檔裡有比較詳細的解釋,這裡就不贅述了。隻說一點,粗排盡量選擇篩選性好的字段或者方法,如果召回的文檔依舊非常多,那麼可以将條件放在filter字句中,提高檢索效率;否則容易遇到檢索逾時的錯誤。
配額的問題:
以實際業務來說,opensearch在配額使用率達到80%時會報一次警,此後就再無報警;如果運維人員或者開發人員疏忽沒有注意到報警,那麼在配額耗盡時,opensearch更新文檔會直接失敗,導緻搜尋結果不準确。而且這個失敗也不會觸發報警,除非人為去檢視錯誤日志。。。
是以在業務迅速發展時期,應當定期檢視opensearch的配額,購買配額時還需注意,要稍微多購買一點,略微大于主附表的有效資料容量和,否則在重建索引時也有可能遇到空間不足的錯誤而失敗。個人猜測是重建索引時的中間檔案或者臨時檔案會額外占據一些空間,是以配額要稍大一點
排序不符合業務需求的問題
這個建議多查閱官方文檔,熟悉每種排序方法的使用場景,并進行合理的搭配使用。實際使用中,粗排與精排可能會需要較長的時間去不斷調整回報,耐心與科學的排序方法需兼顧,當然了,也可以咨詢阿裡雲的技術專家:)