Face Aging with Conditional Generative Adversarial Network 論文筆記
2017.02.28
Motivation:
本文是要根據最新的條件産生式對抗玩網絡(CGANs)來完成,人類老年照片的估計。
主要是做了一下兩個事情:
1. 根據年齡階段,進行照片的老年估計,用 acGAN 網絡來完成;
2. 提出一種 隐層變量優化算法(latent vector optimization approach),允許 acGAN 可以重構輸入人臉圖像,與此同時,保留原本人臉的個體。
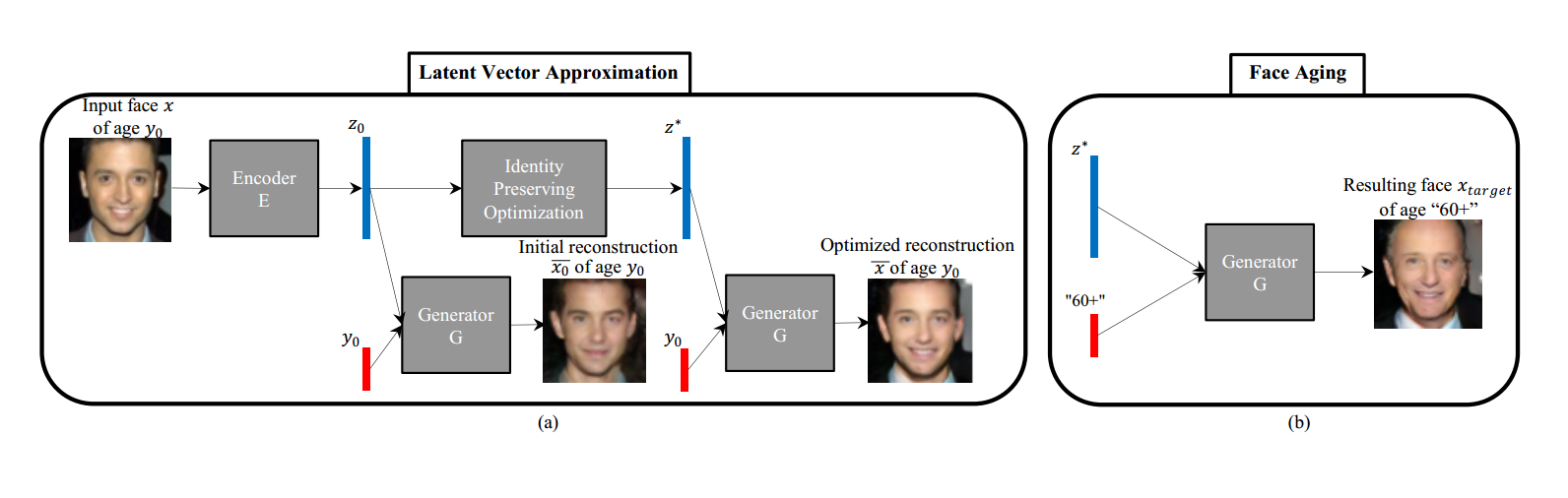
猛地一看,這個流程圖,其實是挺迷惑人的,我感覺。
按照上述流程圖,來看看作者想要達到什麼效果:
1. 首先給定一張輸入圖像 x ,假設年齡記為 y0,找到一個最優的隐層向量 z*,使得可以産生一個重構的人臉 x-,盡可能的和初始的人臉盡可能的相似。
2. 給定一個目标年齡 $y_{target}$,産生一張結果人臉圖像 $x_{target} = G(z*, y_{target})$,簡單的完成年齡的切換。
其實,這個文章是做了這麼一個事情:
結合 條件産生式對抗網絡 和 隐層向量之間的loss 來完成整個網絡的訓練。
首先,作者是在給定一張圖像的基礎上,進行人臉的老化估計。作者這裡考慮了 輸入随機 noise 對最終結果的影響。
自己随機的産生了一堆 noise Z,然後在條件--->> 年齡這個标簽的條件下,利用對抗網絡生成許多僞造的 image ;
由于是自己根據 noise z 生成的,這裡相當于是 已經有了 groundtruth,我們訓練一個 encode 網絡,将輸入的人臉圖像,估計其 編碼後的 向量 z* ;
通過不斷地訓練,可以得到 能夠預測圖像隐層編碼的網絡 Encoder 。
其次,我們文章的一個很重要的賣點在于,可以保持生成圖像和輸入圖像是 相同的身份,是同一個人,那麼,這裡是怎麼做到的呢?
因為我們知道,GAN 生成的資料,一般都是看起來有模有樣,但是實際上是很難控制輸出什麼的。
本文之是以可以做到這一點,就是因為,在生成圖像的過程中,加入了隐層變量 z 之間的 loss,即:

這樣在生成圖像過程中,考慮生成的圖像和原始輸入圖像之間的隐層向量 z 之間的差距,盡可能的小,就可以将這個事情 model 的非常好!
總結起來就是,在生成圖像的過程中,首先學習一個編碼網絡,可以預測圖像的隐層變量。然後在 GAN 過程中,加入這個 loss,作為衡量輸出圖像品質好壞的一個标準。
這樣,生成的人臉圖像,不但可以盡可能的和原始圖像保持是同一個人,另外,又可以,在條件 年齡的基礎上,生成對應年齡階段的人臉圖像。
大緻就是這麼個流程。有任何疑問,請發郵件與我聯系! [email protected]