PredNet --- Deep Predictive coding networks for video prediction and unsupervised learning ICLR 2017
2017.03.12
Code and video examples can be found at: https://coxlab.github.io/prednet/
摘要:基于監督訓練的深度學習技術取得了非常大的成功,但是無監督問題仍然是一個未能解決的一大難題(從未标注的資料中學習到一個領域的結構)。本文探索了無監督學習中關于 video prediction 的問題。設計了一種 “PredNet”結構,實作了該項工程,并且得到了非常喜人的實驗結果。實驗結果表明:預測代表了一種非常強大的無監督學習架構,可以潛在的學習到物體或者場景結構。
網絡設計:
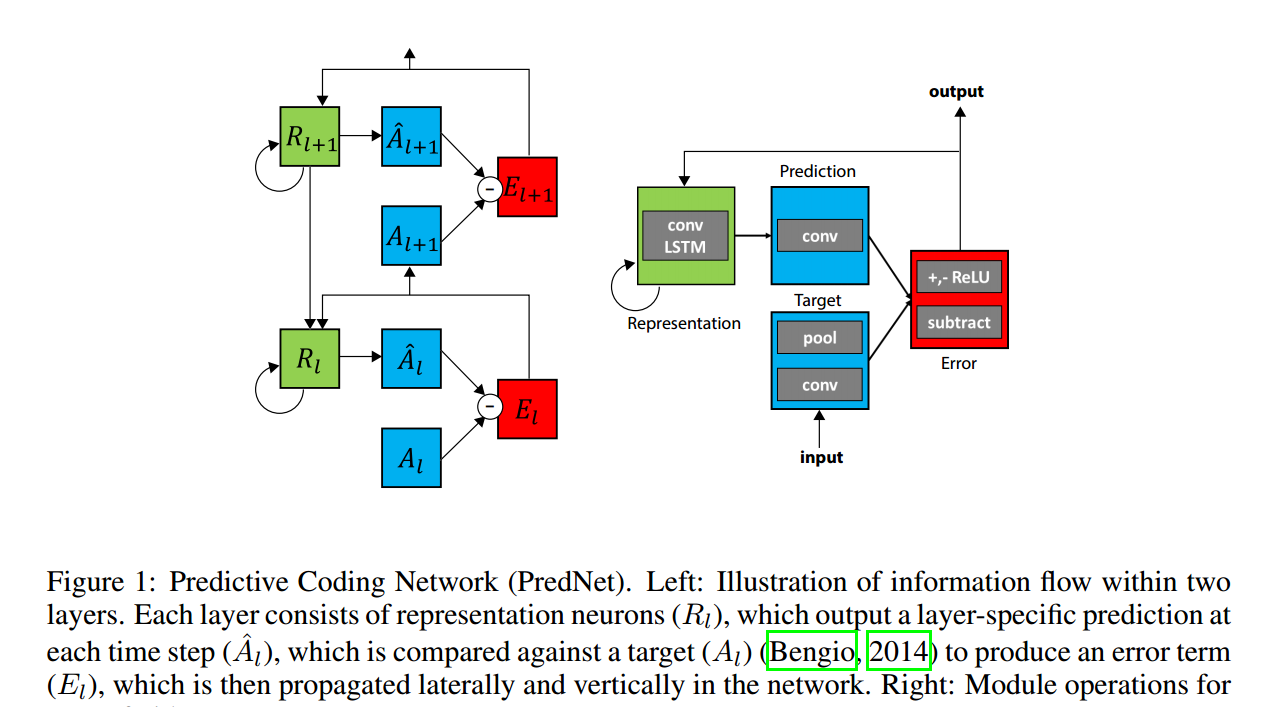
如上圖所示的流程,是有一系列的子產品堆疊在一起産生的。該網絡首先進行局部預測,然後減去真實的輸入,傳到下一層。
簡單的說,每個子產品可以分為 4 個部分:
1. 一個輸入卷積層 $A_l$
2. 循環表示層 $R_l$
3. 預測層 $\hat{A}_l $
4. 誤差表示層 $E_l$
$R_l$ 是一個循環卷積網絡産生一個預測 A^l,layer的輸入是 Al。網絡計算 Al 和 A^l 的不同,然後輸出一個誤差表示 El, 分為單獨修正的 positive 和 negative error 傳遞。将該誤差 El 傳遞給卷積層,作為下一層的輸入 $A_{l+1}$。$R_l$ 子產品有兩個輸入,分别來自于:直接拷貝過來的 El,以及 下一層 $R_{l+1}$ 的輸入。
這個網絡可以分為兩個最重要的部分來看,左邊 Rl 部分是循環産生式反卷積網絡;右邊 Al 和 El 是标準的深度卷積網絡。
該模型訓練的目标是:minimize the weighted sum of the firing rates of the error units. 此處的 error units 類似于 L1 error. 雖然此處沒有嘗試,但也可以嘗試其他的 loss function。

總的算法架構如下:
實驗部分: