昨天我在判斷正則引擎用到的方法是用 /nfa|nfa not/ 去比對 "nfa not",得到的結果是 'nfa'。
其實我們的本意是想得到整個字元串 "nfa not" 的,可卻隻得到了 'nfa'。
再來看個例子,/an (nfa)?(nfa test)?/ 去比對 "an nfa test",如果和上面一樣的解釋,那應該隻得到 'an nfa',
接着第一個捕獲組裡是 'nfa' 第二個捕獲組裡是空。
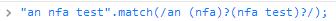
我們的本意是盡量多的去比對所有字元串,可是得到的卻是 'an nfa' 這不是我們期望的結果,為什麼它不去比對第二個呢?
因為傳統型NFA引擎遵循的原則是從左到右按順序去比對,滿足要求就停止。
多分支表達式 /nfa|nfa not/ 在 nfa 比對成功的時候,就不會去繼續比對第二個表達式了。
捕獲組也是一樣,當 (nfa)? 表達式比對成功,就儲存目前比對狀态,隻會接下去比對 'an nfa' 後面的部分,而不會回到 'an ' 這裡重新比對一下表達式。
是以 左最長規則 的意思就是把你希望得到的最長的那個表達式寫在左邊,這樣他就會按順序比對到我們期望的内容了。
用 /nfa not|nfa/ 去比對 "nfa not",用 /an (nfa test)?(nfa)?/ 去比對 "an nfa test"。
好吧,今天又是水文一篇,不過好歹學了一丁點新東西了。
